i denne tutorial vil vi forklare, en af de nye og fremtrædende ord indlejring teknik kaldet Ord2vec foreslået af Mikolov et al. i 2013. Vi har samlet dette indhold fra forskellige tutorials og kilder for at lette læserne på et enkelt sted. Jeg håber, det hjælper.
Ord2vec er en kombination af modeller, der bruges til at repræsentere distribuerede repræsentationer af ord i et corpus C. Ord2vec (V2V) er en algoritme, der accepterer tekstkorpus som input og udsender en vektorrepræsentation for hvert ord, som vist i diagrammet nedenfor:

der er to varianter af denne algoritme, nemlig: CBO og Skip-Gram. Givet et sæt sætninger (også kaldet corpus) modellen sløjfer på ordene i hver sætning og forsøger enten at bruge det aktuelle ord V for at forudsige sine naboer (dvs.dens kontekst) kaldes denne tilgang “Spring-Gram”, eller den bruger hver af disse sammenhænge til at forudsige det aktuelle ord V, i så fald kaldes metoden “kontinuerlig pose med ord” (CBO). For at begrænse antallet af ord i hver kontekst bruges en parameter kaldet “vinduesstørrelse”.

de vektorer, vi bruger til at repræsentere ord, kaldes neurale ordindlejringer, og repræsentationer er mærkelige. En ting beskriver en anden, selvom disse to ting er radikalt forskellige. Som Elvis Costello sagde: “at skrive om musik er som at danse om arkitektur.”Ord2vec” vektoriserer ” om ord, og ved at gøre det gør det naturligt sprog computerlæsbart-vi kan begynde at udføre kraftige matematiske operationer på ord for at opdage deres ligheder.
så repræsenterer et neuralt ord indlejring et ord med tal. Det er en enkel, men alligevel usandsynlig oversættelse. Ord2vec ligner en autoencoder, der koder for hvert ord i en vektor, men snarere end at træne mod inputordene gennem genopbygning, som en begrænset maskine gør, ord2vec træner ord mod andre ord, der nabo dem i input corpus.
det gør det på en af to måder, enten ved hjælp af kontekst til at forudsige et målord (en metode kendt som kontinuerlig pose med ord eller cbo) eller ved hjælp af et ord til at forudsige en målkontekst, som kaldes Spring-gram. Vi bruger sidstnævnte metode, fordi den giver mere nøjagtige resultater på store datasæt.

når funktionsvektoren, der er tildelt et ord, ikke kan bruges til nøjagtigt at forudsige ordets kontekst, justeres komponenterne i vektoren. Hvert ords kontekst i corpus er læreren, der sender fejlsignaler tilbage for at justere funktionsvektoren. Vektorerne af ord, der bedømmes ens efter deres kontekst, skubbes tættere sammen ved at justere tallene i vektoren. I denne tutorial, vi vil fokusere på Skip-Gram-model, som i modsætning til CBO betragter centerord som input som afbildet i figuren ovenfor og forudsiger kontekstord.
modeloversigt
vi forstod, at vi er nødt til at fodre et mærkeligt neuralt netværk med nogle par ord, men vi kan ikke bare gøre det ved at bruge de faktiske tegn som input, vi er nødt til at finde en måde at repræsentere disse ord matematisk på, så netværket kan behandle dem. En måde at gøre dette på er at skabe et ordforråd med alle ordene i vores tekst og derefter kode vores ord som en vektor med de samme dimensioner af vores ordforråd. Hver dimension kan tænkes som et ord i vores ordforråd. Så vi vil have en vektor med alle nuller og en 1, der repræsenterer det tilsvarende ord i ordforrådet. Denne kodningsteknik kaldes one-hot-kodning. I betragtning af vores eksempel, hvis vi har et ordforråd lavet af ordene “den”, “hurtig”, “brun”, “ræv”, “hopper”, “over”, “den” “dovne”, “hund”, ordet “brun” er repræsenteret af denne vektor: .

Skip-gram-modellen tager et korpus af tekst og opretter en hot-vektor for hvert ord. En varm vektor er en vektorrepræsentation af et ord, hvor vektoren er størrelsen på ordforrådet (samlede unikke ord). Alle dimensioner er indstillet til 0 undtagen den dimension, der repræsenterer det ord, der bruges som input på det tidspunkt. Her er et eksempel på en varm vektor:

ovenstående input gives til et neuralt netværk med et enkelt skjult lag.
vi skal repræsentere et inputord som” myrer ” som en en-hot vektor. Denne vektor vil have 10.000 komponenter (en for hvert ord i vores ordforråd), og vi placerer en “1” i den position, der svarer til ordet “myrer”, og 0s i alle de andre positioner. Netværkets output er en enkelt vektor (også med 10.000 komponenter), der for hvert ord i vores ordforråd indeholder sandsynligheden for, at et tilfældigt valgt nærliggende ord er det ordforrådsord.
i ord2vec bruges en distribueret repræsentation af et ord. Tag en vektor med flere hundrede dimensioner (sig 1000). Hvert ord er repræsenteret ved en fordeling af vægte på tværs af disse elementer. Så i stedet for en en-til-en kortlægning mellem et element i vektoren og et ord, er repræsentationen af et ord spredt over alle elementerne i vektoren, og hvert element i vektoren bidrager til definitionen af mange ord.
hvis jeg mærker dimensionerne i en hypotetisk ordvektor (der er selvfølgelig ingen sådanne forudtildelte etiketter i algoritmen), kan det se lidt ud som dette:

en sådan vektor kommer til at repræsentere på en eller anden abstrakt måde ‘betydningen’ af et ord. Og som vi vil se næste, simpelthen ved at undersøge et stort korpus er det muligt at lære ordvektorer, der er i stand til at fange forholdet mellem ord på en overraskende udtryksfuld måde. Vi kan også bruge vektorerne som input til et neuralt netværk. Da vores inputvektorer er one-hot, multiplicerer en inputvektor med vægtmatricen V1 til blot at vælge en række fra V1.
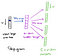

fra det skjulte lag til outputlaget kan den anden vægtmatrice V2 bruges til at beregne en score for hvert ord i ordforrådet, og softmaks kan bruges til at opnå den bageste fordeling af ord. Skip-gram-modellen er det modsatte af CBO-modellen. Det er konstrueret med fokusordet som den enkelte inputvektor, og målkontekstordene er nu ved outputlaget. Aktiveringsfunktionen for det skjulte lag svarer simpelthen til at kopiere den tilsvarende række fra vægtmatricen V1 (lineær) som vi så før. Ved outputlaget udsender vi nu C multinomiale distributioner i stedet for kun en. Træningsmålet er at efterligne den summerede forudsigelsesfejl på tværs af alle kontekstord i outputlaget. I vores eksempel ville input være” læring”, og vi håber at se (“en”,” effektiv”,” metode”,” for”,” høj”,” kvalitet”,” distribueret”,” vektor”) ved outputlaget.
her er arkitekturen i vores neurale netværk.

For vores eksempel vil vi sige, at vi lærer ordvektorer med 300 funktioner. Så det skjulte lag vil blive repræsenteret af en vægtmatrice med 10.000 rækker (en for hvert ord i vores ordforråd) og 300 kolonner (en for hver skjult neuron). 300 funktioner er, hvad Google brugte i deres offentliggjorte model trænet på Google Nyheder datasæt (du kan hente det herfra). Antallet af funktioner er en “hyperparameter”, som du bare skal indstille til din applikation (det vil sige prøve forskellige værdier og se, hvad der giver de bedste resultater).
hvis du ser på rækkerne i denne vægtmatrice, er det, hvad der vil være vores ordvektorer!

så slutmålet med alt dette er virkelig bare at lære denne skjulte lagvægtmatrice — outputlaget, vi bare kaster, når vi er færdige! 1 300 ordvektoren for “myrer” bliver derefter fodret til outputlaget. Dette er en af de mest almindelige typer af regressionsklassificeringer. Specifikt har hver udgangsneuron en vægtvektor, som den multiplicerer mod ordvektoren fra det skjulte lag, så anvender den Funktionen eksp(h) til resultatet. Endelig, for at få output til at opsummere op til 1, deler vi dette resultat med summen af resultaterne fra alle 10.000 outputnoder. Her er en illustration af beregning af output af output neuron for ordet”bil”.

hvis to forskellige ord har meget lignende” sammenhænge ” (det vil sige, hvilke ord der sandsynligvis vises omkring dem), skal vores model udsende meget lignende resultater for disse to ord. Og en måde for netværket at udsende lignende kontekstforudsigelser for disse to ord er, hvis ordvektorerne er ens. Så hvis to ord har lignende sammenhænge, er vores netværk motiveret til at lære lignende ordvektorer for disse to ord! Ta da!
hver dimension af indgangen passerer gennem hver knude i det skjulte lag. Dimensionen multipliceres med vægten, der fører den til det skjulte lag. Fordi indgangen er en varm vektor, vil kun en af inputnoderne have en værdi, der ikke er nul (nemlig værdien 1). Dette betyder, at for et ord kun de vægte, der er forbundet med inputnoden med værdi 1, aktiveres, som vist på billedet ovenfor.
da indgangen i dette tilfælde er en varm vektor, vil kun en af inputnoderne have en værdi, der ikke er nul. Dette betyder, at kun de vægte, der er forbundet til den indgangsknude, aktiveres i de skjulte noder. Et eksempel på de vægte, der vil blive overvejet, er afbildet nedenfor for det andet ord i ordforrådet:
vektorrepræsentationen af det andet ord i ordforrådet (vist i det neurale netværk ovenfor) vil se ud som følger, når den er aktiveret i det skjulte lag:
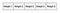
disse vægte starter som tilfældige værdier. Netværket trænes derefter for at justere vægten for at repræsentere inputordene. Det er her outputlaget bliver vigtigt. Nu hvor vi er i det skjulte lag med en vektorrepræsentation af ordet, har vi brug for en måde at bestemme, hvor godt vi har forudsagt, at et ord passer ind i en bestemt sammenhæng. Konteksten af ordet er et sæt ord i et vindue omkring det, som vist nedenfor:

ovenstående billede viser, at konteksten for fredag indeholder ord som “kat” og “er”. Formålet med det neurale netværk er at forudsige, at “fredag” falder inden for denne sammenhæng.
vi aktiverer outputlaget ved at multiplicere vektoren, som vi passerede gennem det skjulte lag (som var input hot vector * vægte, der indtaster skjult knude) med en vektorrepræsentation af kontekstordet (som er den varme vektor for kontekstordet * vægte, der kommer ind i outputnoden). Outputlagets tilstand for det første kontekstord kan visualiseres nedenfor:

ovenstående multiplikation udføres for hvert ord til kontekstordpar. Vi beregner derefter sandsynligheden for, at et ord hører til et sæt kontekstord ved hjælp af de værdier, der er resultatet af de skjulte og outputlag. Endelig anvender vi stokastisk gradientafstamning for at ændre vægtenes værdier for at få en mere ønskelig værdi for den beregnede Sandsynlighed.
i gradient nedstigning skal vi beregne gradienten af den funktion, der optimeres på det punkt, der repræsenterer den vægt, vi ændrer. Gradienten bruges derefter til at vælge den retning, i hvilken man skal tage et skridt for at bevæge sig mod det lokale optimum, som vist i minimeringseksemplet nedenfor.
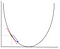
vægten ændres ved at tage et trin i retning af det optimale punkt (i ovenstående eksempel det laveste punkt i grafen). Den nye værdi beregnes ved at trække fra den aktuelle vægtværdi den afledte funktion på det tidspunkt, hvor vægten skaleres af indlæringshastigheden. Det næste trin er at bruge Backpropagation til at justere vægten mellem flere lag. Fejlen, der beregnes i slutningen af outputlaget, føres tilbage fra outputlaget til det skjulte lag ved at anvende Kædereglen. Gradient nedstigning bruges til at opdatere vægten mellem disse to lag. Fejlen justeres derefter ved hvert lag og sendes tilbage yderligere. Her er et diagram til at repræsentere backpropagation:

forståelse ved hjælp af Eksempel
Ord2vec bruger et enkelt skjult lag, fuldt tilsluttet neuralt netværk som vist nedenfor. Neuronerne i det skjulte lag er alle lineære neuroner. Inputlaget er indstillet til at have så mange neuroner, som der er ord i ordforrådet til træning. Den skjulte lagstørrelse er indstillet til dimensionaliteten af de resulterende ordvektorer. Størrelsen på outputlaget er den samme som inputlaget. Således, hvis ordforrådet til læring af ordvektorer består af V ord og N for at være dimensionen af ordvektorer, kan input til skjulte lagforbindelser repræsenteres af matrice med størrelse VCN med hver række, der repræsenterer et ordforrådsord. På samme måde kan forbindelserne fra skjult lag til udgangslag beskrives ved hjælp af matricen i størrelse NV. I dette tilfælde repræsenterer hver kolonne af to matricer et ord fra det givne ordforråd.

indgangen til netværket er kodet ved hjælp af “1-out of-V” – repræsentation, hvilket betyder, at kun en inputlinje er indstillet til en, og resten af inputlinjerne er indstillet til nul.
lad os antage, at vi har et træningskorpus med følgende sætninger:
“hunden så en kat”, “hunden jagede katten”, “katten klatrede et træ”
corpus-Ordforrådet har otte ord. Når det er bestilt alfabetisk, kan hvert ord henvises til dets indeks. I dette eksempel vil vores neurale netværk have otte input neuroner og otte output neuroner. Lad os antage, at vi beslutter at bruge tre neuroner i det skjulte lag. Det betyder, at vi og vi vil være henholdsvis 8 3 og 3 8 8 matricer. Før træningen begynder, initialiseres disse matricer til små tilfældige værdier, som det er sædvanligt i neurale netværkstræning. Bare for illustrationens skyld, lad os antage, at vi og vi initialiseres til følgende værdier:

Antag, at vi ønsker, at netværket skal lære forholdet mellem ordene “kat” og “klatret”. Det vil sige, at netværket skal vise en høj sandsynlighed for “klatret”, når “cat” er indtastet til netværket. I ordindlejringsterminologi kaldes ordet” kat “som kontekstordet, og ordet” klatret ” kaldes målordet. Bemærk, at kun den anden komponent i vektoren er 1. Dette skyldes, at input ordet er” kat”, som holder nummer to position i Sorteret liste over corpus ord. Da målordet er “klatret”, vil målvektoren se ud som t. med inputvektoren, der repræsenterer” kat”, kan udgangen ved de skjulte lagneuroner beregnes som:
Ht = Hvi =
det bør ikke overraske os, at vektoren h af skjulte neuronudgange efterligner vægten af den anden række af vi-matricen på grund af 1-out-of-Vrepresentation. Så funktionen af input til skjulte lagforbindelser er dybest set at kopiere inputordvektoren til skjult lag. Udførelse af lignende manipulationer for skjult til outputlag, aktiveringsvektoren for outputlagneuroner kan skrives som
hto =
da målet er at producere sandsynligheder for ord i outputlaget, Pr(ordk|ordkontekst) for k = 1, V, for at afspejle deres næste ordforhold med kontekstordet ved input, har vi brug for summen af neuronudgange i outputlaget for at tilføje til en. Ord2vec opnår dette ved at konvertere aktiveringsværdier for udgangslagneuroner til sandsynligheder ved hjælp af softmaks-funktionen. Således beregnes udgangen af k-th-neuronen ved hjælp af følgende udtryk, hvor aktivering (n) repræsenterer aktiveringsværdien af det n-th-udgangslagneuron:
sandsynligheden for otte ord i corpus er således:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
sandsynligheden med fed skrift er for det valgte målord”klatret”. I betragtning af målvektoren t beregnes fejlvektoren for outputlaget let ved at trække sandsynlighedsvektoren fra målvektoren. Når fejlen er kendt, kan vægten i matricerne VO og vi opdateres ved hjælp af backpropagation. Således kan træningen fortsætte ved at præsentere forskellige kontekstmålord par fra corpus. Sådan lærer Ord2vec forholdet mellem ord og udvikler i processen vektorrepræsentationer for ord i corpus.
ideen bag ord2vec er at repræsentere ord ved en vektor af reelle tal af dimension d. Derfor er den anden matrice repræsentationen af disse ord. Den i-th linje i denne matrice er vektorrepræsentationen af det i-TH ord. Lad os sige , at i dit eksempel har du 5 ord:, så betyder den første vektor, at du overvejer ordet “hest”, og så er repræsentationen af “hest”. Tilsvarende er repræsentationen af ordet “løve”.

så vidt jeg ved, er der ingen” menneskelig betydning ” specifikt for hvert af numrene i disse repræsentationer. Et tal repræsenterer ikke, om ordet er et verb eller ej, et adjektiv eller ej… det er bare de vægte, du ændrer for at løse dit optimeringsproblem for at lære repræsentationen af dine ord.
en visuel diagram bedst udarbejde ord2vec matrice multiplikation proces er afbildet i følgende figur:

den første matrice repræsenterer inputvektoren i et varmt format. Den anden matrice repræsenterer de synaptiske vægte fra inputlagets neuroner til de skjulte lagneuroner. Bemærk især det øverste venstre hjørne, hvor Inputlagsmatricen multipliceres med Vægtmatricen. Se nu øverst til højre. Denne matrice multiplikation InputLayer dot-producted med vægte transponere er bare en praktisk måde at repræsentere det neurale netværk øverst til højre.
den første del repræsenterer inputordet som en varm vektor, og den anden matrice repræsenterer vægten for forbindelsen af hvert af inputlagneuronerne til de skjulte lagneuroner. Som Ord2vec træner, det backpropagates (ved hjælp af gradient nedstigning) i disse vægte og ændrer dem for at give bedre repræsentationer af ord som vektorer. Når træningen er gennemført, bruger du kun denne vægtmatrice, tager for at sige ‘hund’ og multiplicerer den med den forbedrede vægtmatrice for at få vektorrepræsentationen af ‘hund’ i en dimension = ingen af skjulte lagneuroner. I diagrammet er antallet af skjulte lagneuroner 3.
i en nøddeskal, Skip-gram model vender brugen af mål og kontekst ord. I dette tilfælde fodres målordet ved indgangen, det skjulte lag forbliver det samme, og udgangslaget i det neurale netværk replikeres flere gange for at imødekomme det valgte antal kontekstord. Ved at tage eksemplet på” kat “og” træ “som kontekstord og” klatrede ” som målordet, ville inputvektoren i skumgrammodellen være t, mens de to outputlag ville have henholdsvis t og t som målvektorer. I stedet for at producere en vektor af sandsynligheder, ville to sådanne vektorer blive produceret for det nuværende eksempel. Fejlvektoren for hvert outputlag fremstilles på den måde som beskrevet ovenfor. Imidlertid opsummeres fejlvektorerne fra alle outputlag for at justere vægten via backpropagation. Dette sikrer, at vægtmatricen for hvert outputlag forbliver identisk gennem træning.
vi har brug for få yderligere ændringer til den grundlæggende skip-gram-model, som er vigtige for at gøre det muligt at træne. Kører gradient nedstigning på et neuralt netværk, at store vil være langsom. Og for at gøre tingene værre, har du brug for en enorm mængde træningsdata for at indstille så mange vægte og undgå overmontering. millioner af vægte gange milliarder af træningsprøver betyder, at træning af denne model bliver et dyr. Til det har forfattere foreslået to teknikker kaldet subsampling og negativ prøveudtagning, hvor ubetydelige ord fjernes, og kun en specifik prøve af vægte opdateres.
Mikolov et al. brug også en simpel subsampling-tilgang til at imødegå ubalancen mellem sjældne og hyppige ord i træningssættet (for eksempel “in”, “the” og “a” giver mindre informationsværdi end sjældne ord). Hvert ord i træningssættet kasseres med Sandsynlighed P (U) hvor

F (vi) er hyppigheden af ord vi og t er en valgt tærskel, typisk omkring 10-5.
implementeringsdetaljer
Ord2vec er implementeret på forskellige sprog, men her vil vi især fokusere på Java dvs., DeepLearning4j, darks-learning og python . Forskellige neurale netalgoritmer er implementeret i DL4j, kode er tilgængelig på GitHub.
for at implementere det i DL4j, vil vi gennemgå få trin givet som følger:
a) Ord2vec Setup
Opret et nyt projekt i IntelliJ ved hjælp af Maven. Angiv derefter Egenskaber og afhængigheder i POM.i dit projekts rodmappe.
b) Indlæs data
Opret og navngiv nu en ny klasse i Java. Derefter tager du de rå sætninger i din .krydse dem med din iterator, og udsætte dem for en form for forbehandling, såsom at konvertere alle ord til små bogstaver.
String filePath = ny ClassPathResource(“rå_sentences.tekst”).getFile ().getAbsolutePath ();
log.info (“Indlæs & vektorisere sætninger….”);
// Strip hvidt mellemrum før og efter for hver linje
SentenceIterator ITER = ny BasicLineIterator (filePath);
hvis du vil indlæse en tekstfil udover sætningerne i vores eksempel, vil du gøre dette:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) tokenisering af dataene
Ord2vec skal fodres ord snarere end hele sætninger, så det næste trin er at tokenisere dataene. At tokenisere en tekst er at bryde den op i sine atomenheder og skabe et nyt token hver gang du rammer et hvidt rum, for eksempel.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) træning af modellen
nu hvor dataene er klar, kan du konfigurere Ordet2vec neurale net og foder i tokens.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
denne konfiguration accepterer flere hyperparametre. Nogle få kræver en forklaring:
- batchstørrelse er mængden af ord, du behandler ad gangen.
- minordfrekvens er det mindste antal gange et ord skal vises i corpus. Her, hvis det vises mindre end 5 gange, læres det ikke. Ord skal vises i flere sammenhænge for at lære nyttige funktioner om dem. I meget store corpora er det rimeligt at hæve minimum.
- useAdaGrad — Adagrad skaber en anden gradient for hver funktion. Her er vi ikke bekymrede over det.
- lagstørrelse angiver antallet af funktioner i ordet vektor. Dette er lig med antallet af dimensioner i funktionerneplads. Ord repræsenteret af 500 funktioner bliver punkter i et 500-dimensionelt rum.
- learningRate er trinstørrelsen for hver opdatering af koefficienterne, da ord omplaceres i funktionsrummet.
- minLearningRate er ordet på læringsfrekvensen. Læringshastighed falder, når antallet af ord, du træner på, falder. Hvis læringshastigheden krymper for meget, er nettets læring ikke længere effektiv. Dette holder koefficienterne i bevægelse.
- iterate fortæller nettet, hvilken batch af datasættet det træner på.
- tokenisator føder det ordene fra den aktuelle batch.
- vec.fit () fortæller det konfigurerede net at begynde at træne.
e) evaluering af modellen ved hjælp af Ord2vec
det næste trin er at evaluere kvaliteten af dine funktionsvektorer.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
linjen vec.similarity("word1","word2") returnerer cosinus-ligheden mellem de to ord, du indtaster. Jo tættere det er på 1, jo mere ens opfatter nettet disse ord som (Se eksemplet Sverige-Norge ovenfor). Eksempel:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
med vec.wordsNearest("word1", numWordsNearest) giver ordene, der er trykt på skærmen, Dig mulighed for at øjeæble, om nettet har samlet semantisk lignende ord. Du kan indstille antallet af nærmeste ord, du ønsker, med den anden parameter af ordnæreste. For eksempel:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Ord2vec i Java i http://deeplearning4j.org/word2vec.html
7) Ord2vec og Doc2Vec i Python i genisme http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html