af Doble Engineering Company i Enterprise Asset Management / juni 25, 2020
Del dette…

Facebook

Pinterest

kvidre

Linkedin
verden af data og analyser er i konstant udvikling. I sine enklere dage bestod typisk dataorganisation af nogle filer, applikations-eller transaktionsdatabaser, datalagre og rapporteringsdatamarts. Da datakilder, mængder, generationshastigheder og indsamlingsprocessen er vokset gennem årene, skal dagens computermiljø håndtere ekstremt store datasæt – ofte benævnt ‘big data’ – der afslører mønstre, tendenser og mere, som organisationer kan basere beslutninger på.
de fleste organisationer har i dag mange, hvis ikke alle, af de komponenter, der er fremhævet i referencearkitekturen, der formidles i Figur 1 – applikationer, systemer og kilder, dataoverførsel, virksomhedsdatalag, datatjenester, analyse og rapportering og avanceret databehandling.
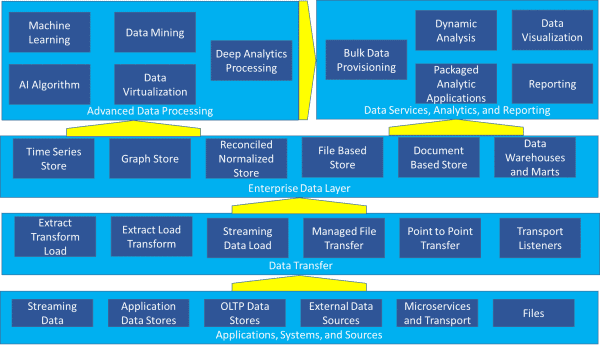
Figur 1-kompleks referencearkitektur
med datalager og marts repræsenteret som en af 28 mulige komponenter, er det svært at forstå, hvordan de passer ind i billedet ved første øjekast. Men de fleste organisationer beskæftiger sig i øjeblikket med mere end et datalager – de skal sammenhængende styre et komplekst miljø som det, der er afbildet i Figur 1.
Kimball-og Inmon-arkitekturer tilbyder begge rammer til at hjælpe med udviklingen af kompleks referencearkitektur.
hurtig genopfriskning af de to tilgange
før du anvender Kimball-eller Inmon-mønstrene, er det værd at gennemgå forskellene mellem de to tilgange. Tjek de visuelle repræsentationer af hver i figur 21 og figur 32 .
arbejdet med Kimball og Inmon – grundlæggerne af de respektive modeller – udfordrede hinanden. Mens begge tilgange overvejende er drevet af udviklingscyklussen for en datamodel, modellerne er baseret på et målbevidst fokus på enten en bund op, eller en top ned tilgang. Disse spændinger spillede ud i udviklingen af de samlede datalagrings-og analysemiljøer.
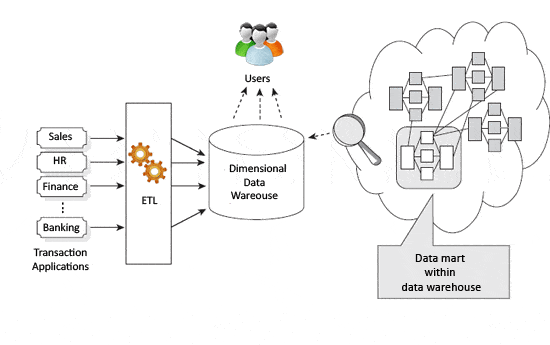
figur 2-visuel Kimball

se figur 3-visuel Inmon-visning
Kimball-tilgangen indikerer, at datalagre og datamarts er drevet af forretningsprocesser og forretningsspørgsmål. Den åbenlyse fare for dette er nyttige data kan ikke nødvendigvis kategoriseres eller fanges, da de ikke passer ind i den forretningsproces, der defineres.
inmon-tilgangen angiver oprettelsen af et virksomhedsdatalager med logiske modeller designet til hver enhed omkring et emne, såsom måler, faktura og aktiv. Udfordringen er, mens de vigtigste emner kan repræsentere differentiering, de enheder, der støtter dem, kan repræsentere fællesheder, der kan gå tabt.
f.eks. kan placeringen af en måler som repræsenteret af en tjenesteplacering, den faktureringsadresse, der er repræsenteret på fakturaen, og et aktivs lagerplacering eller installationsplacering alle dele fælles attributter. Selv under Inmon er der fare for, at tjenesteplaceringen, faktureringsadressen, aktivet, lagerplaceringen og aktivudrulningsplaceringen kan repræsenteres som fem forskellige objekter, da de anses for at understøtte forskellige vertikaler i organisationen med forskellige datamarts.
både inmon-og Kimball-tilgange er drevet af cyklussen for at udvikle den konceptuelle datamodel og derefter implementere datamodellerne i en fysisk form. Denne cyklus kan understøtte mere smidige udviklingsmetoder, men den passer bedst sammen med en vandfaldstype udviklingsmetode på grund af forskningens linearitet (baseret på processen eller virksomhedsemnet), udviklingen af den konceptuelle model (baseret på dataene i processen eller virksomhedsemnet) og udviklingen af den fysiske model.
at tage det næste trin
en smidig proces kan gøre det vanskeligt at injicere cyklusser i denne type udviklingsaktivitet. Udfordringen for enhver organisation vil være at tage erfaringerne fra inmon og Kimball tilgange, og anvende dem i en ny sammenhæng.
flere detaljer om, hvordan man anvender mønstrene i et komplekst miljø for at komme i del to af denne blogserie – stay tuned!
i mellemtiden kan du tjekke vores seneste indlæg om succesfuld implementering af enterprise information management (EIM).