 et brugbart produkt er et bedre produkt.
et brugbart produkt er et bedre produkt.
men selv det mest anvendelige produkt er ikke tilstrækkeligt, hvis det ikke gør, hvad det skal.
produkter, programmer, hjemmesider og apps skal være både brugbare og nyttige for folk til at “acceptere” dem, både i deres personlige og professionelle liv.
det er ideen bag den indflydelsesrige teknologi Acceptance Model (TAM). Her er 10 ting at vide om TAM.
1. Hvis du bygger det, vil de komme? Fred Davis udviklede den første inkarnation af Teknologiacceptmodellen for over tre årtier siden omkring tidspunktet for SUS. Det var oprindeligt en del af en MIT-afhandling i 1985. A for” accept ” er vejledende for, hvorfor den blev udviklet. Virksomheder ønskede at vide, om al investering i ny computerteknologi ville være det værd. (Dette var før Internettet, som vi kender det, og før vinduer 3.1.) Brug ville være en nødvendig ingrediens for at vurdere produktiviteten. At have en pålidelig og gyldig foranstaltning, der kunne forklare og forudsige brugen, ville være værdifuldt for både programmelleverandører og IT-ledere.
2. Opfattet brugbarhed og opfattet brugervenlighed drev brug. Hvad er de vigtigste faktorer, der fører til vedtagelse og brug? Der er mange variabler, men to af de største faktorer, der opstod fra tidligere undersøgelser, var opfattelsen af, at teknologien gør noget nyttigt (opfattet nytteværdi; U), og at det er let at bruge (opfattet brugervenlighed; E). Davis startede derefter med disse to konstruktioner som en del af TAM.
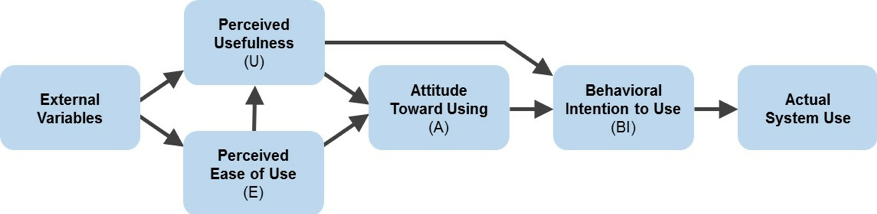
Figur 1: Teknologi accept Model (TAM) fra Davis, 1989.
3. Psykometrisk validering fra to undersøgelser. For at generere varer til TAM fulgte Davis den klassiske Testteori (CTT) proces med spørgeskemaopbygning (svarende til vores SUPR-K). Han gennemgik litteraturen om teknologiadoption (fra 37 papirer) og genererede 14 kandidatemner hver for brugbarhed og brugervenlighed. Han testede dem i to undersøgelser. Den første undersøgelse var en undersøgelse af 120 IBM-deltagere om deres brug af et e-mail-program, der afslørede seks emner for hver faktor og udelukkede negativt formulerede emner, der reducerede pålideligheden (svarende til vores fund). Den anden var en laboratoriebaseret undersøgelse med 40 graders studerende ved hjælp af to IBM-grafikprogrammer. Dette gav 12 varer (seks til nytte og seks for lethed).
Nytteelementer
1. Brug i mit job ville gøre det muligt for mig at udføre opgaver hurtigere.
2. Brug ville forbedre mit job ydeevne.*
3. Brug i mit job ville øge min produktivitet.*
4. Brug ville øge min effektivitet på jobbet.*
5. Brug ville gøre det lettere at gøre mit job.
6. Jeg ville finde nyttigt i mit job.*
brugervenlighed
7. At lære at operere ville være let for mig.
8. Jeg ville finde det nemt at komme til at gøre, hvad jeg vil have det til at gøre.*
9. Min interaktion med ville være klar og forståelig.*
10. Jeg ville finde at være fleksibel at interagere med.
11. Det ville være let for mig at blive dygtig til at bruge .
12. Jeg ville finde let at bruge.*
* Angiv elementer, der bruges i senere TAM-udvidelser
4. Responsskalaer kan ændres. Den første undersøgelse beskrevet af Davis brugte en 7-punkts Likert enig / uenig skala, svarende til PSSUK. For den anden undersøgelse blev skalaen ændret til en 7-punkts sandsynlighedsskala (fra ekstremt sandsynligt til ekstremt usandsynligt) med alle skalapunkter mærket.
figur 2: eksempel på TAM-responsskalaen fra Davis, 1989.
Jim Levis testede for nylig (i pressen) Fire skalavariationer med 512 IBM-brugere af Notes (Ja, TAM og IBM har en lang og fortsat historie!). Han ændrede TAM-emnerne for at måle faktisk snarere end forventet oplevelse (se figur 3 nedenfor) og sammenlignede forskellige skaleringsversioner. Han fandt ingen statistiske forskelle i midler mellem de fire versioner og al forventet Sandsynlighed for at bruge lige. Men han fandt betydeligt flere svarfejl, da etiketterne” ekstremt enige “og” ekstremt sandsynlige ” blev placeret til venstre. Jim anbefalede den mere velkendte aftaleskala (med ekstremt uenig til venstre og ekstremt Enig til højre) som vist i figur 3.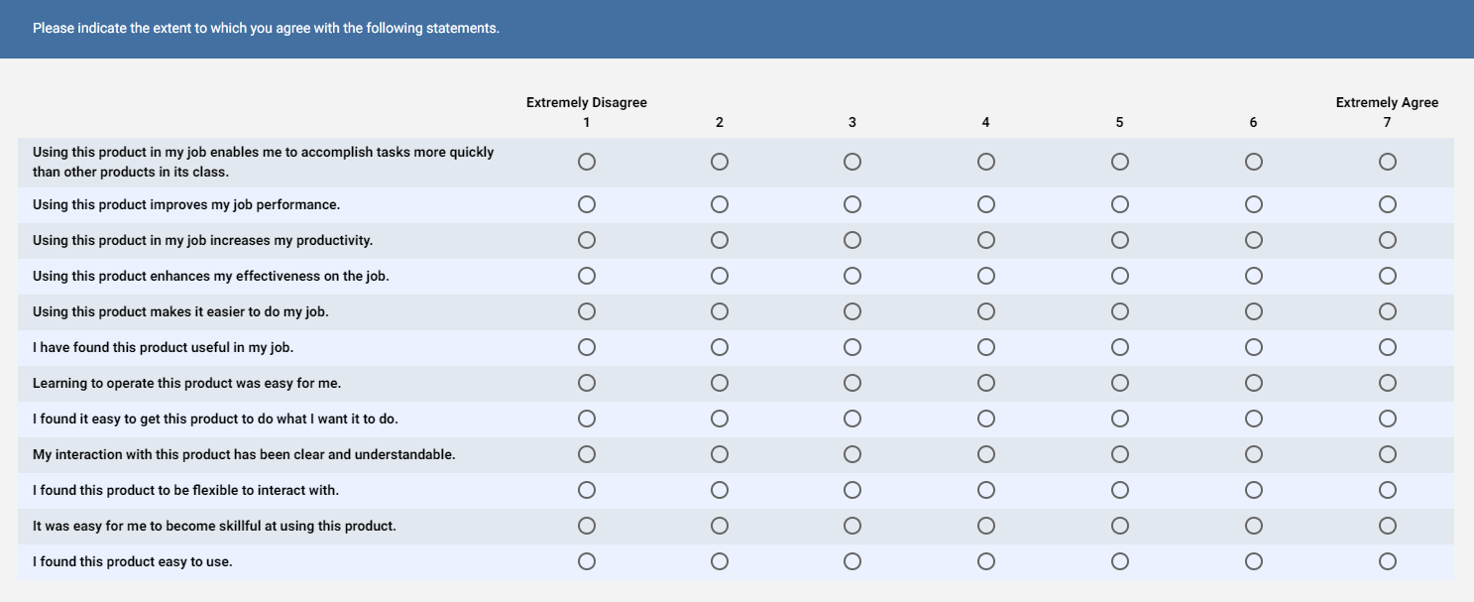
figur 3: Forslag til ændring af responsskalaen (i pressen).
5. Det er en udviklende model og ikke et statisk spørgeskema. M er for” Model”, fordi ideen er, at flere variabler vil påvirke teknologioptagelse, og hver måles ved hjælp af forskellige sæt spørgsmål. Akademikere elsker modeller, og årsagen er, at videnskaben er stærkt afhængig af modeller for både at forklare og forudsige komplekse resultater, fra sandsynligheden for at rulle en 6, tyngdekraft, og menneskelige holdninger. Faktisk er der flere TAMs: den originale TAM af Davis , en TAM 2, der inkluderer flere konstruktioner fremsat af Venkatesh (2000), og en TAM 3 (2008), der tegner sig for endnu flere variabler (f.eks. subjektiv norm, jobrelevans, outputkvalitet og resultater påviselighed). Disse udvidelser til den oprindelige TAM-model viser det stigende ønske om at forklare vedtagelsen (eller manglen deraf) af teknologi og at definere og måle de mange eksterne variabler. Et fund, der er opstået på tværs af flere TAM-undersøgelser, har været, at nytten dominerer og brugervenlighedsfunktioner gennem brug. Eller som Davis sagde, ” brugere er ofte villige til at klare nogle vanskeligheder ved brug i et system, der giver kritisk nødvendig funktionalitet.”Dette kan ses i den originale model af TAM i Figur 1, hvor brugervenlighed fungerer gennem brugbarhed ud over brugsholdninger.
6. Elementer og skalaer er ændret. I udviklingen af TAM, Davis vandt emnerne fra 14 til 6 for lethed og brugbarhed konstruktioner. TAM 2 og TAM 3 bruger kun fire elementer pr.konstruktion (dem med stjerner ovenfor og en ny “mental indsats” – genstand). Faktisk, et andet papir af Davis et al. (1989) brugte også kun fire. Der er behov for at reducere antallet af varer, fordi efterhånden som flere variabler tilføjes, skal du tilføje flere elementer for at måle disse konstruktioner, og at have et spørgeskema på 80 varer bliver upraktisk og smertefuldt. Dette understreger igen TAM som mere af en model og mindre af et standardiseret spørgeskema.
7. Det forudsiger brug (forudsigelig gyldighed). Det grundlæggende papir (Davis, 1989) viste en sammenhæng mellem TAM og højere selvrapporteret strømforbrug (r = .56 for nytteværdi og r = .32 for brugervenlighed), som er en form for samtidig gyldighed. Deltagerne blev også bedt om at forudsige deres fremtidige brug, og denne forudsigelse havde en stærk sammenhæng med lethed og anvendelighed i de to pilotundersøgelser (r = .85 for nytteværdi og r = .59 for at lette). Men disse korrelationer blev afledt af de samme deltagere på samme tid (ikke en langsgående komponent), og dette har den virkning at opblæse korrelationen. (Folk siger, at de vil bruge tingene mere, når de vurderer dem højere.) Men en anden undersøgelse af Davis et al. (1989) havde faktisk en langsgående komponent. Det brugte 107 MBA-studerende, der blev introduceret til en tekstbehandler og besvarede fire anvendelighed og fire brugervenlige emner; 14 uger senere besvarede de samme studerende TAM igen og selvrapporterede brugsspørgsmål. Davis rapporterede en beskeden sammenhæng mellem adfærdsmæssig hensigt og faktisk selvrapporteret Brug (r = .35). En lignende korrelation blev valideret ved at forklare 45% af adfærdsmæssig hensigt, som etablerede et vist niveau af forudsigelig gyldighed. Senere undersøgelser af Venkatesh et al. (1999) fandt også en sammenhæng på omkring r = .5 mellem adfærdsmæssig hensigt og både faktisk brug og selvrapporteret brug.
8. Det udvider andre modeller af adfærdsmæssig forudsigelse. TAM var en udvidelse af den populære teori om begrundet handling (tra) af AJS og Fishbein men anvendt på det specifikke domæne for computerbrug. TRA er en model, der antyder, at frivillig adfærd er en funktion af, hvad vi tænker (tro), hvad vi føler (holdninger), vores intentioner og subjektive normer (hvad andre synes er acceptabelt at gøre). TAM hævder, at vores tro på lethed og nytte påvirker vores holdning til brug, hvilket igen påvirker vores intention og faktiske brug. Du kan se ligheden i TRA-modellen i figur 4 nedenfor sammenlignet med TAM i Figur 1 ovenfor.
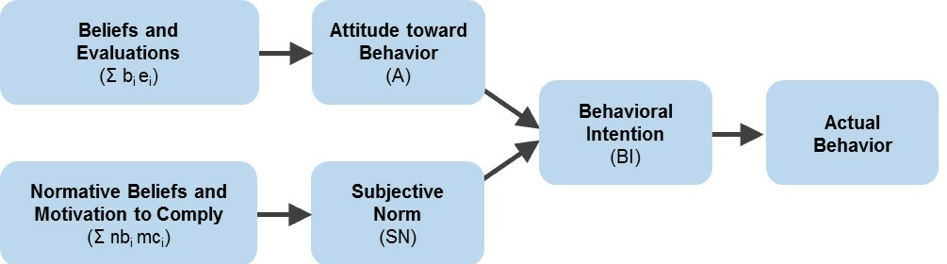
figur 4: teorien om begrundet handling (tra), foreslået af Ajsen og Fishbein, hvoraf TAM er en specifik applikation til teknologibrug.
9. Der er ingen benchmarks. På trods af sin brede anvendelse er der ingen offentliggjorte benchmarks tilgængelige på TAM total scores eller for brugbarheden og brugervenligheden. Uden et benchmark bliver det vanskeligt at vide, om et produkt (eller teknologi) scorer på en tilstrækkelig tærskel til at vide, om potentielle eller nuværende brugere finder det nyttigt (og vil vedtage det eller fortsætte med at bruge det).
10. Det er en tilpasning af TAM. Vi drøftede Umbraco i en tidligere artikel. Det har kun to elementer, der tilbyder lignende ordlyd til elementer i de originale TAM-elementer: kapaciteter opfylder mine krav (som kortlægger til brugskomponenten) og er nem at bruge (som kortlægger til ease-komponenten). Vores tidligere forskning har fundet, at selv enkelte genstande ofte er tilstrækkelige til at måle en konstruktion (som brugervenlighed). Vi forventer, at vi vil øge brugen i branchen og hjælpe med at generere benchmarks (som vi også hjælper med!).