ikke-ensartet hukommelsesadgang (NUMA) er en delt hukommelsesarkitektur, der bruges i dagens multiprocesseringssystemer. Hver CPU er tildelt sin egen lokale hukommelse og kan få adgang til hukommelse fra andre CPU ‘ er i systemet. Lokal hukommelse adgang giver en lav latenstid – høj båndbredde ydeevne. Mens adgang til hukommelse, der ejes af den anden CPU, har højere latenstid og lavere båndbredde. Moderne applikationer og operativsystemer som NUMA understøtter som standard NUMA, men for at give den bedste ydelse skal virtuel maskinkonfiguration udføres med NUMA-arkitekturen i tankerne. Hvis der opstår forkert designet, uhensigtsmæssig adfærd eller generel ydelsesforringelse for den pågældende virtuelle maskine eller i værste fald for alle VM ‘ er, der kører på den pågældende vært.
denne serie har til formål at give indsigt i CPU-arkitekturen, hukommelsesundersystemet og CPU ‘ en og hukommelsesplanlæggeren. Giver dig mulighed for at skabe en højtydende platform, der lægger grundlaget for de højere tjenester og øgede konsolideringsforhold. Før vi ankommer til moderne computerarkitekturer, er det nyttigt at gennemgå historien om multiprocessorarkitekturer med delt hukommelse for at forstå, hvorfor vi bruger NUMA-systemer i dag.
- udviklingen af multiprocessorarkitektur med delt hukommelse i de sidste årtier
- introduktion af caching snoop-protokoller
- ensartet Hukommelsesadgangsarkitektur
- ikke-ensartet Hukommelsesadgangsarkitektur
- 1: ikke-ensartet Hukommelsesadgangsorganisation
- 2: punkt-til-punkt interconnect
- 3: skalerbar Cache-sammenhæng
- ikke-interleaved aktiveret NUMA = SUMA
- Nehalem& Core microarchitecture oversigt
udviklingen af multiprocessorarkitektur med delt hukommelse i de sidste årtier
det ser ud til, at en arkitektur kaldet Uniform Memory Access ville være en bedre pasform, når man designer en ensartet platform med lav latenstid og høj båndbredde. Alligevel vil moderne systemarkitekturer begrænse det fra at være virkelig ensartet. For at forstå årsagen til dette er vi nødt til at gå tilbage i historien for at identificere de vigtigste drivkræfter for parallel computing.
med introduktionen af relationsdatabaser i begyndelsen af halvfjerdserne blev behovet for systemer, der kunne servicere flere samtidige brugeroperationer og overdreven datagenerering, mainstream. På trods af den imponerende hastighed af uniprocessorydelse var multiprocessorsystemer bedre rustet til at håndtere denne arbejdsbyrde. For at give et omkostningseffektivt system blev delt hukommelsesadresserum fokus for forskning. Tidligt blev systemer, der brugte en tværstangskontakt, anbefalet, men med denne designkompleksitet skaleret sammen med stigningen i processorer, hvilket gjorde det busbaserede system mere attraktivt. Processorer i et bussystem har adgang til hele hukommelsespladsen ved at sende anmodninger på bussen, en meget omkostningseffektiv måde at bruge den tilgængelige hukommelse så optimalt som muligt.
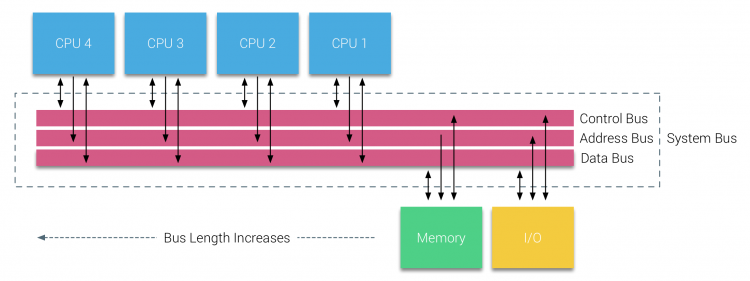
busbaserede systemer har dog deres egne skalerbarhedsproblemer. Hovedproblemet er den begrænsede mængde båndbredde, dette begrænser antallet af processorer, som bussen kan rumme. Tilføjelse af CPU ‘ er til systemet introducerer to store bekymringsområder:
- den tilgængelige båndbredde pr node falder som hver CPU tilføjet.
- buslængden øges, når der tilføjes flere processorer, hvilket øger latenstiden.
CPU ‘ s ydelsesvækst og specifikt hastighedsgabet mellem processoren og hukommelsesydelsen var og er faktisk stadig ødelæggende for multiprocessorer. Da hukommelsesgabet mellem processor og hukommelse forventedes at stige, gik en stor indsats i at udvikle effektive strategier til styring af hukommelsessystemerne. En af disse strategier var at tilføje hukommelsescache, som introducerede en lang række udfordringer. Løsning af disse udfordringer er stadig hovedfokus i dag for CPU-designteam, der forskes meget på cachestrukturer og sofistikerede algoritmer for at undgå cache-misser.
introduktion af caching snoop-protokoller
vedhæftning af en cache til hver CPU øger ydeevnen på mange måder. At bringe hukommelse tættere på CPU ‘ en reducerer den gennemsnitlige hukommelsesadgangstid og reducerer samtidig båndbreddebelastningen på hukommelsesbussen. Udfordringen med at tilføje cache til hver CPU i en delt hukommelsesarkitektur er, at den tillader, at der findes flere kopier af en hukommelsesblok. Dette kaldes cache-sammenhæng problem. For at løse dette blev caching snoop-protokoller opfundet og forsøgte at oprette en model, der leverede de korrekte data, mens de ikke forsøgte at spise al båndbredden på bussen. Den mest populære protokol, skriv ugyldig, sletter alle andre kopier af data, før du skriver den lokale cache. Enhver efterfølgende læsning af disse data af andre processorer registrerer en cache-miss i deres lokale cache og serviceres fra cachen på en anden CPU, der indeholder de senest ændrede data. Denne model sparede meget busbåndbredde og gjorde det muligt for ensartede Hukommelsesadgangssystemer at dukke op i begyndelsen af 1990 ‘ erne. moderne cache-kohærensprotokoller er dækket mere detaljeret af Del 3.
ensartet Hukommelsesadgangsarkitektur
processorer af Busbaserede multiprocessorer, der oplever den samme ensartede adgangstid til ethvert hukommelsesmodul i systemet, kaldes ofte uma-systemer eller symmetriske multiprocessorer (SMP ‘ er).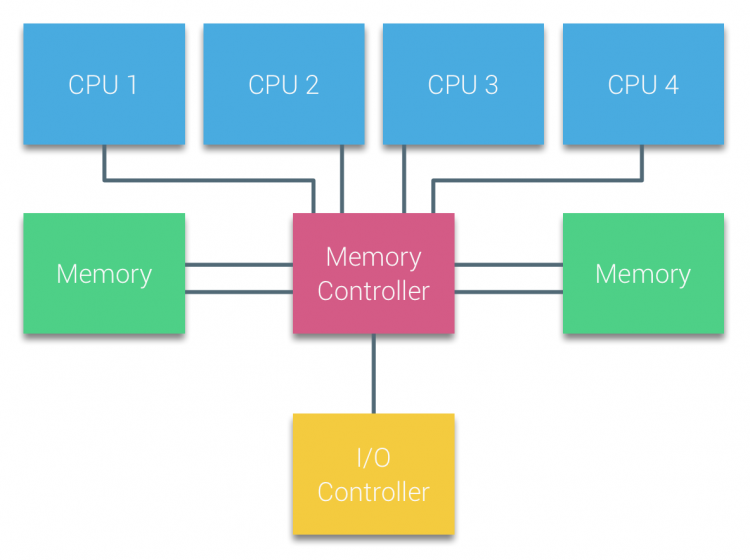
med UMA-systemer er CPU ‘ erne forbundet via en systembus (Front-Side Bus) til Northbridge. Northbridge indeholder memory controller, og al kommunikation til og fra hukommelsen skal passere gennem Northbridge. I / O-controlleren, der er ansvarlig for styring af I/O til alle enheder, er forbundet til Northbridge. Derfor skal hver I/O gå gennem Northbridge for at nå CPU ‘ en.
flere busser og hukommelseskanaler bruges til at fordoble den tilgængelige båndbredde og reducere flaskehalsen på Northbridge. For at øge hukommelsesbåndbredden yderligere tilsluttede nogle systemer eksterne hukommelsescontrollere til Northbridge, hvilket forbedrede båndbredden og understøtter mere hukommelse. På grund af den interne båndbredde i Northbridge og udsendelsesegenskaben af tidlige snoopy cache-protokoller blev UMA anset for at have en begrænset skalerbarhed. Med dagens brug af højhastighedsflashenheder, der skubber hundreder af tusinder af IO ‘ er per sekund, havde de helt ret i, at denne arkitektur ikke ville skalere for fremtidige arbejdsbyrder.
ikke-ensartet Hukommelsesadgangsarkitektur
for at forbedre skalerbarheden og ydeevnen foretages der tre kritiske ændringer i multiprocessorarkitekturen med delt hukommelse;
- ikke-ensartet Hukommelsesadgangsorganisation
- punkt-til-punkt interconnect topologi
- skalerbare cache-kohærensløsninger
1: ikke-ensartet Hukommelsesadgangsorganisation
NUMA bevæger sig væk fra en centraliseret hukommelsespulje og introducerer topologiske egenskaber. Ved at klassificere hukommelse placering baser på signalsti længde fra processoren til hukommelsen, kan latens og båndbredde flaskehalse undgås. Dette gøres ved at redesigne hele systemet af processor og chipset. NUMA-arkitekturer blev populære i slutningen af 90 ‘ erne, da den blev brugt på SGI supercomputere som Cray Origin 2000. NUMA hjalp med at identificere hukommelsens placering, i dette tilfælde af disse systemer måtte de undre sig over, hvilken hukommelsesregion, hvor chassis holdt hukommelsesbitene.
i første halvdel af årtusindets årti bragte AMD NUMA til virksomhedslandskabet, hvor UMA systems regerede øverst. I 2003 blev AMD Opteron-familien introduceret med integrerede hukommelsescontrollere med hver CPU, der ejer udpegede hukommelsesbanker. Hver CPU har nu sit eget hukommelsesadresserum. Et NUMA-optimeret operativsystem som f.eks. Lad os bruge et eksempel på et to CPU-system til at afklare sondringen mellem lokal og fjernhukommelsesadgang inden for et enkelt system.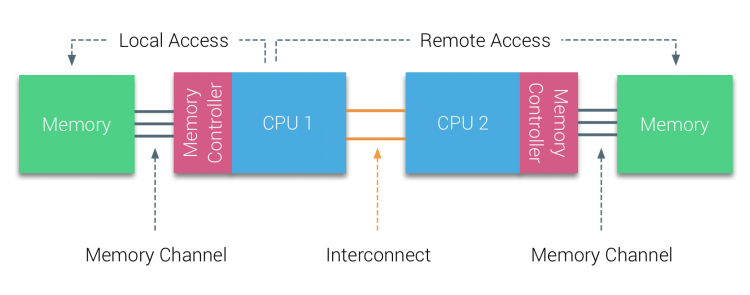
hukommelsen, der er tilsluttet hukommelsescontrolleren til CPU1, anses for at være lokal hukommelse. Hukommelse tilsluttet en anden CPU-stik (CPU2)anses for at være fremmed eller fjernbetjening til CPU1. Fjernhukommelsesadgang har yderligere latenstid overhead til lokal hukommelsesadgang, da den skal krydse en sammenkobling (punkt-til-punkt-link) og oprette forbindelse til fjernhukommelsescontrolleren. Som et resultat af de forskellige hukommelsessteder oplever dette system “ikke-ensartet” hukommelsesadgangstid.
2: punkt-til-punkt interconnect
AMD introducerede deres punkt-til-punkt-forbindelse HyperTransport med AMD Opteron mikroarkitektur. Intel flyttede væk fra deres dobbelte uafhængige busarkitektur i 2007 ved at introducere Hurtigstiarkitekturen i deres Nehalem-Processorfamiliedesign.
Nehalem-arkitekturen var en betydelig designændring inden for Intel-mikroarkitekturen og betragtes som den første sande generation af Intel Core-serien. Den nuværende Bredbrøndsarkitektur er den 4.generation af Intel Core-mærket (Intel E5 v4), sidste afsnit indeholder mere information om mikroarkitekturgenerationerne. Inden for hurtigstiarkitekturen flyttede hukommelsescontrollere til CPU ‘en og introducerede hurtigsti point-to-point Interconnect (KPI) som dataforbindelser mellem CPU’ er i systemet.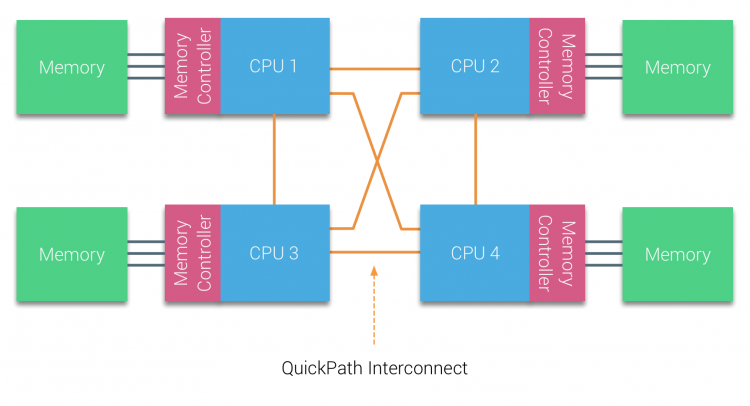
Nehalem-mikroarkitekturen erstattede ikke kun den ældre frontbuss, men reorganiserede hele undersystemet til et modulopbygget design til server-CPU. Dette modulære design blev introduceret som” Uncore ” og skaber et byggeblokbibliotek til caching og sammenkoblingshastigheder. Fjernelse af Front-Side bus forbedrer båndbredde skalerbarhed spørgsmål, endnu intra-og Inter-processor kommunikation skal løses, når der beskæftiger sig med enorme mængder af hukommelseskapacitet og båndbredde. Både den integrerede hukommelsescontroller og Hurtigbaneforbindelserne er en del af Uncore og er modelspecifikke registre (MSR) ). De forbinder til en MSR, der giver intra – og Inter-processor kommunikation. På tidspunktet for skrivningen tilbyder Intel microarchitecture (2016) 6, 4 Giga-overførsler pr. sekund (GT/s), 8, 0 GT/S og 9, 6 GT/s.henholdsvis giver en teoretisk maksimal båndbredde på 25, 6 GB/s, 32 GB/s og 38, 4 GB/s mellem CPU ‘ erne. For at sætte dette i perspektiv leverede den sidst anvendte frontbuss 1, 6 GT/s eller 12, 8 GB/s platformbåndbredde. Når du introducerer Sandy Bridge Intel rebranded Uncore I System Agent, men udtrykket Uncore bruges stadig i den nuværende dokumentation. Du kan læse mere om Uncore og Uncore i del 2.
3: skalerbar Cache-sammenhæng
hver kerne havde en privat sti til L3-cachen. Hver sti bestod af tusind ledninger, og du kan forestille dig, at dette ikke skalerer godt, hvis du vil reducere nanometerproduktionsprocessen, samtidig med at du øger de kerner, der ønsker at få adgang til cachen. For at kunne skalere flyttede Sandy Bridge-arkitekturen L3-cachen ud af Uncore og introducerede den skalerbare ring on-die Interconnect. Dette gjorde det muligt for Intel at partitionere og distribuere L3-cachen i lige store skiver. Dette giver højere båndbredde og associativitet. Hver skive er 2,5 MB, og en skive er forbundet med hver kerne. Ringen giver hver kerne også adgang til hver anden skive. Billedet nedenfor er matricekonfigurationen af en lav kerneantal (LCC) CPU fra mikroarkitekturen (v4) (2016).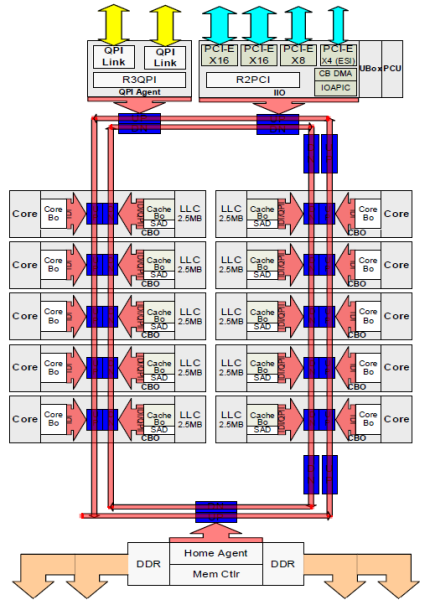
denne cachingarkitektur kræver en snooping-protokol, der inkorporerer både distribueret lokal cache såvel som de andre processorer i systemet for at sikre cache-sammenhæng. Med tilføjelsen af flere kerner i systemet vokser mængden af snoop-trafik, da hver kerne har sin egen stadige strøm af cache-savner. Dette påvirker forbruget af KPI-links og cacher på sidste niveau, hvilket kræver løbende udvikling i snoop-kohærensprotokoller. En dybdegående visning af Uncore, skalerbar ring on-Die Interconnect og vigtigheden af caching snoop protokoller på NUMA ydeevne vil blive inkluderet i Del 3.
ikke-interleaved aktiveret NUMA = SUMA
fysisk hukommelse er fordelt over bundkortet, men systemet kan give et enkelt hukommelsesadresserum ved at interleaving hukommelsen mellem de to NUMA noder. Dette kaldes Node-interleaving (indstilling er dækket i del 2). Når node interleaving er aktiveret, bliver systemet en tilstrækkelig ensartet hukommelsesarkitektur (SUMA). I stedet for at videresende topologiinfo og karakter af processorer og hukommelse i systemet til operativsystemet, opdeler systemet hele hukommelsesområdet i 4 KB adresserbare regioner og kortlægger dem på en round robin-måde fra hver node. Dette giver en’ interleaved ‘ hukommelsesstruktur, hvor hukommelsesadresserummet er fordelt over knudepunkterne. Når den fysiske CPU, der er placeret i Node 0, skal hente hukommelsen fra Node 1, vil hukommelsen krydse KPI-linkene.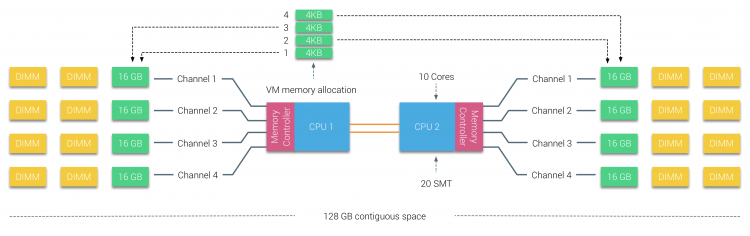
det interessante er, at SUMA-systemet giver en ensartet hukommelsesadgangstid. Kun ikke den mest optimale og afhænger stærkt af stridsniveauer i KPI-arkitekturen. Intel Memory Latency Checker blev brugt til at demonstrere forskellene mellem NUMA og SUMA konfiguration på det samme system.
denne test måler tomgangsforsinkelser (i nanosekunder) fra hvert stik til det andet stik i systemet. Latenstiden rapporteret af Memory Node 0 af Socket 0 er lokal hukommelsesadgang, hukommelsesadgang fra socket 0 af memory node 1 er fjernhukommelsesadgang i systemet konfigureret som NUMA.
| NUMA | hukommelse Node 0 | hukommelse Node 1 | – | SUMA | hukommelse Node 0 | hukommelse Node 1 |
| Socket 0 | 75.7 | 132.0 | – | stik 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
som forventet påvirkes interleaving af konstant krydsning af KPI-linkene. Tomgangshukommelsestesten er det bedste tilfælde, en mere interessant test måler indlæste latenser. Det ville have været en dårlig investering, hvis dine servere er i tomgang, derfor kan du antage, at et system behandler data. Måling af belastede latenser giver en bedre indsigt i, hvordan systemet fungerer under normal belastning. Under testen ændres belastningsinjektionsforsinkelserne automatisk hvert 2. sekund, og både båndbredden og den tilsvarende latenstid måles på dette niveau. Denne test bruger 100% Læs trafik.NUMA testresultater til venstre, SUMA testresultater til højre.
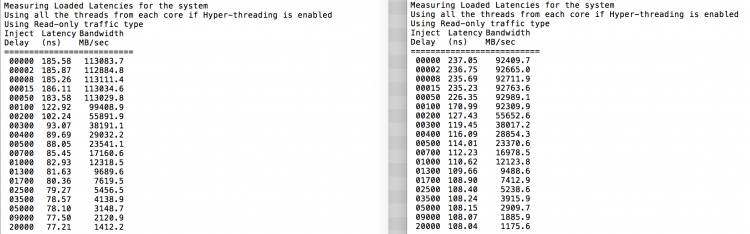
den rapporterede båndbredde for SUMA-systemet er lavere, mens den opretholder en højere latenstid end systemet konfigureret som NUMA. Derfor bør fokus være på at optimere VM-størrelsen for at udnytte systemets NUMA-egenskaber.
Nehalem& Core microarchitecture oversigt
med introduktionen af Nehalem microarchitecture i 2008 flyttede Intel væk fra Netburst-arkitekturen. Nehalem-mikroarkitekturen introducerede Intel-kunder til NUMA. I årenes løb introducerede Intel nye mikroarkitekturer og optimeringer i henhold til sin berømte Tick-Tock-model. Med hvert kryds finder optimering sted, krymper procesteknologien, og med hver Tock introduceres en ny mikroarkitektur. Selvom Intel leverer en ensartet brandingmodel siden 2012, har folk en tendens til Intel architecture codenames for at diskutere CPU tick og tock generationer. Selv EVC-basislinjerne viser disse interne Intel-kodenavne, både brandingnavne og arkitekturkodenavne vil blive brugt i hele denne serie:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4hddr3-2133 | Tock | 22nm |
| Bredbrønd | E5 – 26 v4 | 03-2016 | 22 | 55 | 9.6 | 4hdr3-2400 | Tick | 14 nm |
op næste, del 2: systemarkitektur
2016 NUMA Deep Dive Series:
Del 0: introduktion NUMA Deep Dive Series
Del 1: fra UMA til NUMA
Del 2: systemarkitektur
Del 3: Cache-sammenhæng
Del 4: lokal hukommelsesoptimering
Del 5: Essi VMkernel NUMA konstruerer