skjult Markov-Model (HMM) er en statistisk Markov-model, hvor systemet, der modelleres, antages at være en Markov-proces med uobserverede (dvs.skjulte) tilstande.
Skjulte Markov modeller er især kendt for deres anvendelse i forstærkning læring og tidsmæssig mønstergenkendelse såsom tale, håndskrift, gestus anerkendelse, del-af-tale tagging, musikalsk score efter, partielle udledninger og bioinformatik.
terminologi i HMM
udtrykket skjult henviser til den første ordens Markov-proces bag observationen. Observation refererer til de data, vi kender og kan observere. Markov-processen vises ved interaktionen mellem” regnfuld “og” solrig ” i nedenstående diagram, og hver af disse er skjulte tilstande.

observationer er kendte data og henviser til “gå”, “Shop” og “ren” i ovenstående diagram. I maskinindlæringsfølelse er observation vores træningsdata, og antallet af skjulte tilstande er vores hyperparameter for vores model. Evaluering af modellen vil blive diskuteret senere.

T = har ikke nogen observation endnu, N = 2, M = 3, K = {“Rainy”, “Sunny”}, V = {“gå”, “Shop”, “Clean”}
Tilstandsovergangssandsynligheder er pilene, der peger på hver skjult tilstand. Observation Sandsynlighed matrice er de blå og røde pile, der peger på hver observationer fra hver skjult tilstand. Matricen er række stokastisk betyder rækkerne tilføje op til 1.


matricen forklarer, hvad sandsynligheden er fra at gå til en tilstand til en anden eller gå fra en tilstand til en observation.
indledende tilstandsfordeling får modellen til at gå ved at starte i en skjult tilstand.
fuld model med kendte tilstandsovergangssandsynligheder, observationssandsynlighedsmatrice og initial tilstandsfordeling er markeret som,
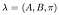
Hvordan kan vi bygge ovenstående model i Python?
i ovenstående tilfælde er emissionerne diskrete {“gåtur”,” butik”,”ren”}. MultinomialHMM fra hmmlearn-biblioteket bruges til ovenstående model. GaussianHMM og GMMHMM er andre modeller i biblioteket.
nu med HMM hvad er nogle vigtige problemer at løse?
- Problem 1, givet en kendt model Hvad er sandsynligheden for sekvens o sker?
- Problem 2, givet en kendt model og sekvens O, Hvad er den optimale skjulte tilstandssekvens? Dette vil være nyttigt, hvis vi vil vide, om vejret er “regnfuldt” eller “solrigt”
- Problem 3, givet sekvens O og antal skjulte tilstande, Hvad er den optimale model, der maksimerer sandsynligheden for o?
Problem 1 i Python
sandsynligheden for, at den første observation er “gåtur” er lig med multiplikationen af den oprindelige tilstandsfordeling og emissions sandsynlighedsmatricen. 0, 6 gange 0, 1 + 0, 4 gange 0, 6 = 0, 30 (30%). Log sandsynligheden leveres fra opkald .Resultat.
Problem 2 i Python

i betragtning af den kendte model og observationen {“Shop”, “Clean”, “gåtur”} var vejret sandsynligvis {“Rainy”, “Rainy”, “Sunny”} med ~1,5% Sandsynlighed.
i betragtning af den kendte model og observationen {“Ren”, “Ren”, “Ren”} var vejret sandsynligvis {“regnfuld”, “regnfuld”, “regnfuld”} med ~3,6% Sandsynlighed.
intuitivt, når “gåtur” opstår, vil vejret sandsynligvis ikke være “regnfuldt”.
Problem 3 i Python
talegenkendelse med lydfil: Forudsig disse ord

Amplitude kan bruges som OBSERVATION for HMM, men funktionsteknik vil give os mere ydeevne.

funktion stft og peakfind genererer funktion til lydsignal.
eksemplet ovenfor blev taget herfra. Kyle Kastner bygget HMM klasse, der tager i 3D arrays, jeg bruger hmmlearn som kun tillader 2D arrays. Dette er grunden til, at jeg reducerer de funktioner, der genereres af Kyle Kastner som test.gennemsnit (akse=2).
at gennemgå denne modellering tog meget tid at forstå. Jeg havde indtryk af, at målvariablen skal være observationen. Dette gælder for tidsserier. Klassificering sker ved at bygge HMM for hver klasse og sammenligne output ved at beregne logprob for dit input.
matematisk løsning på Problem 1: fremad algoritme

Alpha pass er sandsynligheden for OBSERVATION og tilstand sekvens givet model.
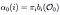
Alpha pass at time (t) = 0, indledende tilstandsfordeling til i og derfra til første observation O0.
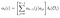
Alpha pass at time (t) = T, summen af sidste alpha pass til hver skjult tilstand ganget med emission til Ot.
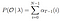
matematisk løsning på Problem 2: Bagudgående algoritme


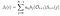

givet model og observation, Sandsynlighed for at være i staten Chi på tidspunktet t.
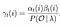
matematisk løsning på Problem 3: Fremad-bagud algoritme


sandsynligheden for fra staten Chi til KJ på tidspunktet t med given model og observation
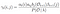
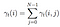
summen af alle overgang Sandsynlighed Fra I til j.
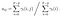
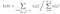
overgangs – og emissionssandsynlighedsmatricen estimeres med di-gamma.
Gentag, hvis sandsynligheden for P(O|model) stiger