stykkevis regression er en særlig type lineær regression, der opstår, når en enkelt linje ikke er tilstrækkelig til at modellere et datasæt. Stykkevis regression bryder domænet i potentielt mange” segmenter ” og passer til en separat linje gennem hver enkelt. For eksempel i graferne nedenfor er en enkelt linje ikke i stand til at modellere dataene såvel som en stykkevis regression med tre linjer:
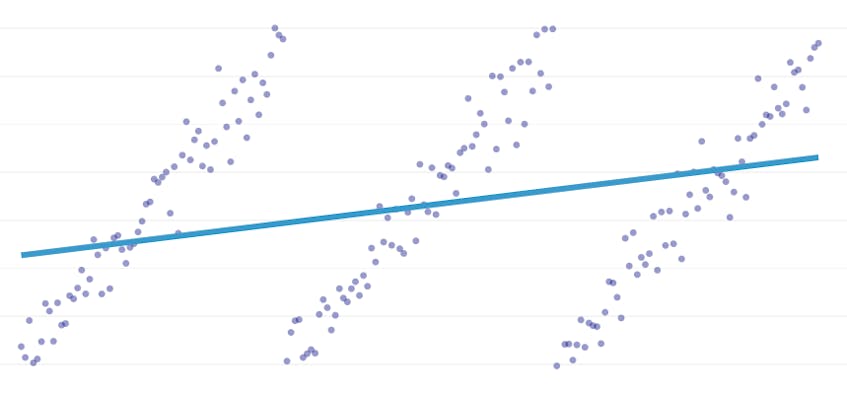
dette indlæg præsenterer Datadogs tilgang til automatisering af stykkevis regression på tidsseriedata.
mål
stykkevis regression kan betyde lidt forskellige ting i forskellige sammenhænge, så lad os tage et øjeblik for at afklare, hvad vi præcist forsøger at opnå med vores stykkevis regressionsalgoritme.
Automatisk detektering af breakpoint. I klassisk statistiklitteratur foreslås stykkevis regression ofte under manuel regressionsanalysearbejde, hvor det er indlysende for det blotte øje, hvor en lineær tendens giver plads til en anden. I så fald kan et menneske specificere brudpunktet mellem stykkevis segmenter, opdele datasættet og udføre en lineær regression på hvert segment uafhængigt. I vores brugssager ønsker vi at gøre hundredvis af regressioner per sekund, og det er ikke muligt at få et menneske til at specificere alle breakpoints. I stedet har vi kravet om, at vores stykkevis regressionsalgoritme identificerer sine egne breakpoints.
Automatisk registrering af segmentantal. Hvis vi skulle vide, at et datasæt har nøjagtigt to segmenter, kunne vi let se på hvert af de mulige par segmenter. Men i praksis, når der gives en vilkårlig tidsserie, er der ingen grund til at tro, at der skal være mere end et segment eller mindre end 3 eller 4 eller 5. Vores algoritme skal vælge et passende antal segmenter, uden at det er brugerspecificeret.
intet kontinuitetskrav. Nogle metoder til stykkevis regressioner genererer tilsluttede segmenter, hvor hvert segments slutpunkt er det næste segments startpunkt. Vi stiller ikke et sådant krav til vores algoritme.
udfordringer
den mest oplagte udfordring ved at implementere en stykkevis regression med automatiseret breakpoint-detektion er den store størrelse af løsningssøgningsrummet; en brute-force-søgning af alle mulige segmenter er uoverkommeligt dyr. Antallet af måder en tidsserie kan opdeles i segmenter er eksponentiel i længden af tidsserien. Mens dynamisk programmering kan bruges til at krydse dette søgeområde meget mere effektivt end en naiv brute-force-implementering, er det stadig for langsomt i praksis. En grådig heuristisk vil være nødvendig for hurtigt at kassere store områder af søgeområdet.
en mere subtil udfordring er, at vi har brug for en måde at sammenligne kvaliteten af en løsning til en anden. For vores version af problemet med ukendte numre og placeringer af segmenter er vi nødt til at sammenligne potentielle løsninger med forskellige antal segmenter og forskellige breakpoints. Vi forsøger at balancere to konkurrerende mål:
- Minimer fejlene. Det vil sige, gør hvert segments regressionslinje tæt på de observerede datapunkter.
- brug det færreste antal segmenter, der modellerer dataene godt. Vi kunne altid få nul fejl ved at oprette et enkelt segment for hvert punkt (eller endda et segment for hvert to punkter). Alligevel ville det besejre hele pointen med at gøre en regression; vi ville ikke lære noget om det generelle forhold mellem et tidsstempel og dets tilknyttede metriske værdi, og vi kunne ikke let bruge resultatet til interpolation eller ekstrapolation.
vores løsning
vi bruger følgende grådige algoritme til stykkevis regressionsproblem:
- lav en stykkevis regression med N/2 segmenter, hvor n er antallet af observationer i tidsserien. Regressionslinjen i hvert segment er egnet ved hjælp af almindelig mindste kvadrater (OLS) regression. Denne indledende stykkevis regression vil næppe have nogen fejl, men den vil alvorligt tilpasse datasættet.
- iterativt, indtil der kun er et segment:
- for alle par af nabosegmenter skal du evaluere stigningen i den samlede fejl, der ville opstå, hvis de to segmenter blev kombineret, hvor deres to regressionslinjer erstattes af en enkelt regressionslinje.
- Flet sammen det par segmenter, der ville resultere i den mindste stigning i fejl.
- hvis udførelsen af denne fletning opfylder vores stoppekriterier (defineret nedenfor), er vi måske gået for langt og flettet to segmenter, der skal forblive adskilte. Hvis dette er tilfældet, skal du huske tilstanden for segmenterne fra før denne iterations fusion.
- hvis ingen fusion resulterede i at huske tilstanden af segmenter i (2C) ovenfor, så er den bedste løsning et stort segment. Ellers er den sidste segmenttilstand, der skal huskes i (2C), den bedste løsning.
Stopkriterier
vi betragter en fletning som et potentielt stoppunkt, hvis det øger den samlede sum af kvadratiske fejl med mere end nogen tidligere fletning. For at forhindre at stoppe for tidligt i tilfælde, hvor der kun burde være et segment, betragter vi ikke en fusion som et potentielt stoppunkt, medmindre det resulterer i en stigning i total fejl, der er mindre end 3% af den samlede fejl i en regression med et segment. (3% er en vilkårlig tærskel, men vi har fundet det til at fungere godt i praksis.) Nedenfor er et par eksempler for at demonstrere, hvorfor dette stopkriterium fungerer.
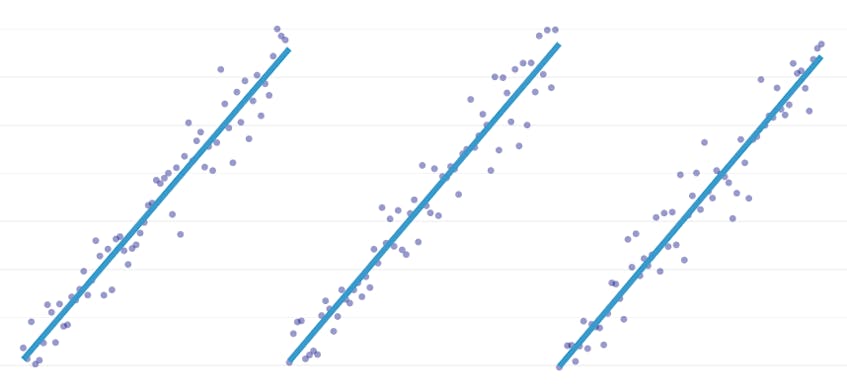
lad os først se på et datasæt, der blev genereret ved at tilføje normalt distribueret støj til punkter langs en enkelt linje. Algoritmen passer korrekt kun et enkelt segment gennem dette datasæt.
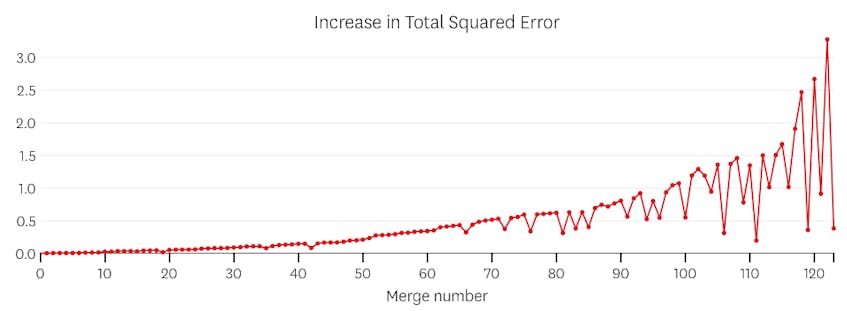
i dette tilfælde øger ingen fusion nogensinde den samlede sum af kvadrerede fejl med mere end 3%. Derfor betragtes ingen fusion som et passende stoppunkt, og vi bruger den endelige tilstand, efter at alle fusioner er blevet udført. I plottet nedenfor ser vi, at senere fusioner har tendens til at introducere mere fejl end tidligere (hvilket giver mening, fordi de hver især påvirker flere point), men stigningen i fejl øges kun gradvist, når flere segmenter flettes.
for det andet, lad os se et eksempel, hvor der er syv forskellige segmenter i datasættet.
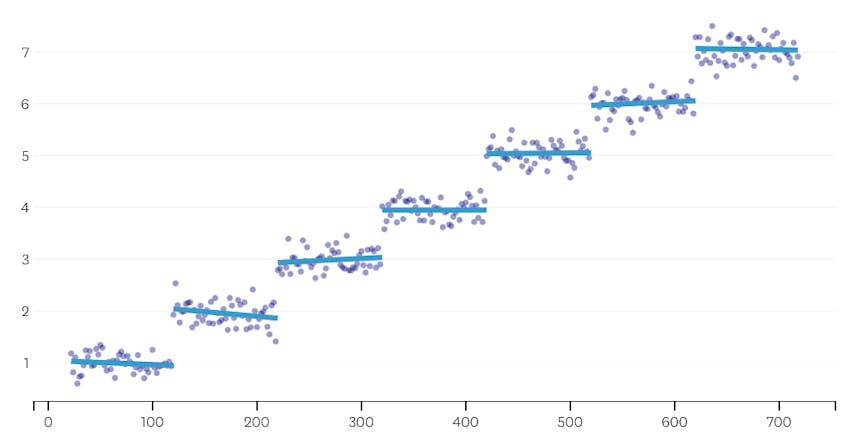
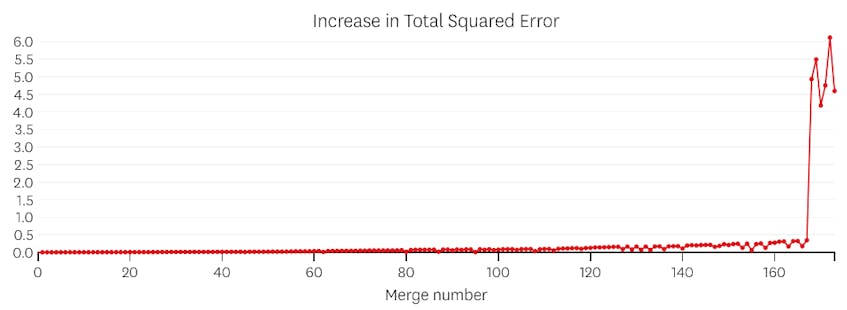
i dette tilfælde, når vi ser på det plot af fejl, der blev introduceret ved hver fusion, ser vi, at de sidste seks fusioner introducerede meget mere fejl end nogen af de tidligere fusioner. Derfor huskede vores algoritme tilstanden af segmenterne fra før den 6.til sidste fusion og brugte den som den endelige løsning.
koden
i Datadog/stykkevis Github repo finder du vores Python implementering af algoritmen. piecewise() – funktionen er, hvor den tunge løft sker; givet et sæt data, vil det returnere placering og regressionskoefficienter for hvert af de monterede segmenter.
også inkluderet i kernen er plot_data_with_regression() — en indpakningsfunktion til hurtig og nem plotning. Et hurtigt eksempel på, hvordan dette kan bruges:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)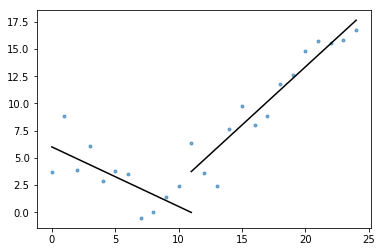
mens denne implementering bruger OLS lineær regression, kan den samme ramme tilpasses til at løse relaterede problemer. Ved at erstatte kvadreret fejl med absolut fejl eller Huber-tab kan regressionen gøres robust. Eller en trinfunktion kan passe ved at tildele hvert segment en konstant værdi svarende til gennemsnittet af observationerne i sit domæne.