In diesem Tutorial werden wir erklären, eine der aufstrebenden und prominenten Worteinbettungstechniken namens Word2Vec vorgeschlagen von Mikolov et al. im Jahr 2013. Wir haben diese Inhalte aus verschiedenen Tutorials und Quellen gesammelt Leser an einem einzigen Ort zu erleichtern. Ich hoffe es hilft.
Word2vec ist eine Kombination von Modellen, die verwendet werden, um verteilte Darstellungen von Wörtern in einem Korpus darzustellen C. Word2Vec (W2V) ist ein Algorithmus, der Textkorpus als Eingabe akzeptiert und eine Vektordarstellung für jedes Wort ausgibt, wie im folgenden Diagramm gezeigt:

Es gibt zwei Varianten dieses Algorithmus: CBOW und Skip-Gram. Bei einer Reihe von Sätzen (auch Korpus genannt) durchläuft das Modell die Wörter jedes Satzes und versucht entweder, das aktuelle Wort w zu verwenden, um seine Nachbarn (dh seinen Kontext) vorherzusagen. Um die Anzahl der Wörter in jedem Kontext zu begrenzen, wird ein Parameter namens „Fenstergröße“ verwendet.

Die Vektoren, die wir zur Darstellung von Wörtern verwenden, werden als neuronale Worteinbettungen bezeichnet, und Darstellungen sind seltsam. Eine Sache beschreibt eine andere, obwohl diese beiden Dinge radikal unterschiedlich sind. Wie Elvis Costello sagte: „Über Musik zu schreiben ist wie über Architektur zu tanzen.“ Word2vec “ vektorisiert“ über Wörter und macht dadurch natürliche Sprache computerlesbar – wir können beginnen, leistungsstarke mathematische Operationen an Wörtern durchzuführen, um ihre Ähnlichkeiten zu erkennen.
Eine neuronale Worteinbettung repräsentiert also ein Wort mit Zahlen. Es ist eine einfache, aber unwahrscheinliche Übersetzung. Word2vec ähnelt einem Autoencoder, der jedes Wort in einem Vektor codiert, aber anstatt wie eine eingeschränkte Boltzmann-Maschine durch Rekonstruktion gegen die Eingabewörter zu trainieren, trainiert word2vec Wörter gegen andere Wörter, die sie im Eingabekorpus angrenzen.
Dies geschieht auf zwei Arten: Entweder mithilfe des Kontexts zur Vorhersage eines Zielworts (eine Methode, die als Continuous Bag of Words oder CBOW bezeichnet wird) oder mithilfe eines Wortes zur Vorhersage eines Zielkontexts, der als Skip-Gram bezeichnet wird. Wir verwenden die letztere Methode, weil sie bei großen Datensätzen genauere Ergebnisse liefert.

Wenn der einem Wort zugewiesene Merkmalsvektor nicht verwendet werden kann, um den Kontext dieses Wortes genau vorherzusagen, werden die Komponenten des Vektors angepasst. Der Kontext jedes Wortes im Korpus ist der Lehrer, der Fehlersignale zurücksendet, um den Merkmalsvektor anzupassen. Die Vektoren von Wörtern, die durch ihren Kontext ähnlich beurteilt werden, werden durch Anpassen der Zahlen im Vektor näher zusammengeschoben. In diesem Tutorial konzentrieren wir uns auf das Skip-Gram-Modell, das im Gegensatz zu CBOW das Mittelwort als Eingabe betrachtet, wie in Abbildung oben dargestellt, und Kontextwörter vorhersagt.
Modellübersicht
Wir haben verstanden, dass wir ein seltsames neuronales Netzwerk mit einigen Wortpaaren füttern müssen, aber wir können das nicht einfach mit den tatsächlichen Zeichen als Eingabe tun, wir müssen einen Weg finden, diese Wörter mathematisch darzustellen, damit das Netzwerk sie verarbeiten kann. Eine Möglichkeit, dies zu tun, besteht darin, ein Vokabular aller Wörter in unserem Text zu erstellen und dann unser Wort als Vektor mit den gleichen Dimensionen unseres Vokabulars zu codieren. Jede Dimension kann als ein Wort in unserem Wortschatz gedacht werden. Wir haben also einen Vektor mit allen Nullen und einer 1, die das entsprechende Wort im Vokabular darstellt. Diese Codierungstechnik wird als One-Hot-Codierung bezeichnet. Wenn wir unser Beispiel betrachten, wenn wir ein Vokabular aus den Wörtern „der“, „schnell“, „braun“, „Fuchs“, „springt“, „über“, „der“, „faul“, „Hund“ haben, wird das Wort „braun“ durch diesen Vektor dargestellt: .

Das Skip-Gram-Modell nimmt einen Textkorpus auf und erstellt für jedes Wort einen Hot-Vektor. Ein heißer Vektor ist eine Vektordarstellung eines Wortes, wobei der Vektor die Größe des Vokabulars (insgesamt eindeutige Wörter) ist. Alle Dimensionen werden auf 0 gesetzt, mit Ausnahme der Dimension, die das Wort darstellt, das zu diesem Zeitpunkt als Eingabe verwendet wird. Hier ist ein Beispiel für einen heißen Vektor:

Die obige Eingabe wird einem neuronalen Netzwerk mit einer einzigen versteckten Schicht gegeben.
Wir werden ein Eingabewort wie „Ameisen“ als One-Hot-Vektor darstellen. Dieser Vektor wird 10.000 Komponenten haben (eine für jedes Wort in unserem Vokabular) und wir werden eine „1“ in der Position platzieren, die dem Wort „Ameisen“ entspricht, und 0s in allen anderen Positionen. Die Ausgabe des Netzwerks ist ein einzelner Vektor (ebenfalls mit 10.000 Komponenten), der für jedes Wort in unserem Vokabular die Wahrscheinlichkeit enthält, dass ein zufällig ausgewähltes Wort in der Nähe dieses Vokabularwort ist.
In word2vec wird eine verteilte Darstellung eines Wortes verwendet. Nehmen Sie einen Vektor mit mehreren hundert Dimensionen (z. B. 1000). Jedes Wort wird durch eine Verteilung der Gewichte über diese Elemente dargestellt. Anstelle einer Eins-zu-Eins-Zuordnung zwischen einem Element im Vektor und einem Wort wird die Darstellung eines Wortes auf alle Elemente im Vektor verteilt, und jedes Element im Vektor trägt zur Definition vieler Wörter bei.
Wenn ich die Dimensionen in einem hypothetischen Wortvektor beschrifte (es gibt natürlich keine solchen vorab zugewiesenen Beschriftungen im Algorithmus), könnte es ein bisschen so aussehen:

Ein solcher Vektor repräsentiert auf abstrakte Weise die Bedeutung eines Wortes. Und wie wir als nächstes sehen werden, ist es einfach durch die Untersuchung eines großen Korpus möglich, Wortvektoren zu lernen, die in der Lage sind, die Beziehungen zwischen Wörtern auf überraschend ausdrucksstarke Weise zu erfassen. Wir können die Vektoren auch als Eingaben in ein neuronales Netzwerk verwenden. Da unsere Eingangsvektoren eindimensional sind, bedeutet das Multiplizieren eines Eingangsvektors mit der Gewichtsmatrix W1, dass einfach eine Zeile aus W1 ausgewählt wird.
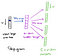

Von der verborgenen Schicht zur Ausgabeschicht kann die zweite Gewichtsmatrix W2 verwendet werden, um eine Punktzahl für jedes Wort im Vokabular zu berechnen, und softmax kann verwendet werden, um die posteriore Verteilung von Wörtern zu erhalten. Das Skip-Gram-Modell ist das Gegenteil des CBOW-Modells. Es wird mit dem Fokuswort als einzigem Eingabevektor erstellt, und die Zielkontextwörter befinden sich jetzt auf der Ausgabeebene. Die Aktivierungsfunktion für die ausgeblendete Ebene besteht einfach darin, die entsprechende Zeile aus der Gewichtungsmatrix W1 (linear) zu kopieren, wie wir zuvor gesehen haben. Auf der Ausgabeebene geben wir jetzt C multinomiale Verteilungen anstelle von nur einer aus. Das Trainingsziel besteht darin, den summierten Vorhersagefehler über alle Kontextwörter in der Ausgabeschicht hinweg zu imitieren. In unserem Beispiel wäre die Eingabe „Lernen“, und wir hoffen, („an“, „effizient“, „Methode“, „für“, „hoch“, „Qualität“, „verteilt“, „Vektor“) auf der Ausgabeebene zu sehen.
Hier ist die Architektur unseres neuronalen Netzwerks.

In unserem Beispiel werden wir sagen, dass wir Wortvektoren mit 300 Funktionen lernen. Die versteckte Ebene wird also durch eine Gewichtsmatrix mit 10.000 Zeilen (eine für jedes Wort in unserem Wortschatz) und 300 Spalten (eine für jedes versteckte Neuron) dargestellt. 300 Funktionen hat Google in seinem veröffentlichten Modell verwendet, das auf dem Google News-Datensatz trainiert wurde (Sie können es hier herunterladen). Die Anzahl der Features ist ein „Hyper-Parameter“, den Sie nur auf Ihre Anwendung abstimmen müssten (dh verschiedene Werte ausprobieren und sehen, was die besten Ergebnisse liefert).
Wenn Sie sich die Zeilen dieser Gewichtsmatrix ansehen, sind dies unsere Wortvektoren!

Das Endziel von all dem ist also wirklich nur, diese versteckte Schichtgewichtsmatrix zu lernen – die Ausgabeschicht, die wir einfach werfen, wenn wir fertig sind! Der 1 x 300-Wortvektor für „Ameisen“ wird dann der Ausgabeschicht zugeführt. Die Ausgabeebene ist ein Softmax-Regressionsklassifikator. Insbesondere hat jedes Ausgangsneuron einen Gewichtsvektor, den es mit dem Wortvektor aus der verborgenen Ebene multipliziert, und wendet dann die Funktion exp (x) auf das Ergebnis an. Um schließlich die Ausgaben auf 1 zu summieren, teilen wir dieses Ergebnis durch die Summe der Ergebnisse aller 10.000 Ausgabeknoten. Hier ist eine Illustration zur Berechnung der Ausgabe des Ausgangsneurons für das Wort „Auto“.

Wenn zwei verschiedene Wörter sehr ähnliche „Kontexte“ haben (dh welche Wörter wahrscheinlich um sie herum erscheinen), muss unser Modell für diese beiden Wörter sehr ähnliche Ergebnisse ausgeben. Eine Möglichkeit für das Netzwerk, ähnliche Kontextvorhersagen für diese beiden Wörter auszugeben, besteht darin, dass die Wortvektoren ähnlich sind. Wenn also zwei Wörter ähnliche Kontexte haben, ist unser Netzwerk motiviert, ähnliche Wortvektoren für diese beiden Wörter zu lernen! Ta da!
Jede Dimension der Eingabe durchläuft jeden Knoten der ausgeblendeten Ebene. Die Dimension wird mit dem Gewicht multipliziert, das sie zur verborgenen Ebene führt. Da die Eingabe ein heißer Vektor ist, hat nur einer der Eingabeknoten einen Wert ungleich Null (nämlich den Wert 1). Dies bedeutet, dass für ein Wort nur die Gewichte aktiviert werden, die dem Eingabeknoten mit dem Wert 1 zugeordnet sind, wie in der obigen Abbildung gezeigt.
Da die Eingabe in diesem Fall ein heißer Vektor ist, hat nur einer der Eingabeknoten einen Wert ungleich Null. Dies bedeutet, dass nur die Gewichte, die mit diesem Eingabeknoten verbunden sind, in den ausgeblendeten Knoten aktiviert werden. Ein Beispiel für die zu berücksichtigenden Gewichte ist unten für das zweite Wort im Vokabular dargestellt:
Die Vektordarstellung des zweiten Wortes im Vokabular (im obigen neuronalen Netzwerk gezeigt) sieht nach Aktivierung in der ausgeblendeten Ebene wie folgt aus:
Diese Gewichte beginnen als Zufallswerte. Das Netzwerk wird dann trainiert, um die Gewichte anzupassen, um die eingegebenen Wörter darzustellen. Hier wird die Ausgabeschicht wichtig. Jetzt, da wir uns in der versteckten Ebene mit einer Vektordarstellung des Wortes befinden, müssen wir feststellen, wie gut wir vorhergesagt haben, dass ein Wort in einen bestimmten Kontext passt. Der Kontext des Wortes ist eine Reihe von Wörtern in einem Fenster um es herum, wie unten gezeigt:

Das obige Bild zeigt, dass der Kontext für Freitag Wörter wie „Katze“ und „ist“ enthält. Ziel des neuronalen Netzes ist es, vorherzusagen, dass „Freitag“ in diesen Kontext fällt.
Wir aktivieren die Ausgabeebene, indem wir den Vektor, den wir durch die ausgeblendete Ebene durchlaufen haben (der Eingabe-Hot-Vektor * Gewichte, die in den ausgeblendeten Knoten eintreten), mit einer Vektordarstellung des Kontextworts multiplizieren (Das ist der heiße Vektor für das Kontextwort * Gewichte, die in den Ausgabeknoten eintreten). Der Zustand der Ausgabeschicht für das erste Kontextwort kann unten visualisiert werden:

Die obige Multiplikation erfolgt für jedes Wort-zu-Wort-Paar. Wir berechnen dann die Wahrscheinlichkeit, dass ein Wort zu einer Reihe von Kontextwörtern gehört, anhand der Werte, die sich aus den ausgeblendeten und ausgegebenen Ebenen ergeben. Schließlich wenden wir stochastischen Gradientenabstieg an, um die Werte der Gewichte zu ändern, um einen wünschenswerteren Wert für die berechnete Wahrscheinlichkeit zu erhalten.
Im Gradientenabstieg müssen wir den Gradienten der Funktion berechnen, die an dem Punkt optimiert wird, der das Gewicht darstellt, das wir ändern. Der Gradient wird dann verwendet, um die Richtung zu wählen, in der ein Schritt in Richtung des lokalen Optimums gemacht werden soll, wie im folgenden Minimierungsbeispiel gezeigt.
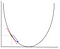
Das Gewicht wird durch einen Schritt in Richtung des optimalen Punktes (im obigen Beispiel der niedrigste Punkt in der Grafik) geändert. Der neue Wert wird berechnet, indem vom aktuellen Gewichtswert die abgeleitete Funktion an der Stelle des durch die Lernrate skalierten Gewichts subtrahiert wird. Der nächste Schritt ist die Verwendung von Backpropagation, um die Gewichte zwischen mehreren Ebenen anzupassen. Der Fehler, der am Ende der Ausgabeebene berechnet wird, wird durch Anwenden der Kettenregel von der Ausgabeebene an die ausgeblendete Ebene zurückgegeben. Gradient Descent wird verwendet, um die Gewichte zwischen diesen beiden Ebenen zu aktualisieren. Der Fehler wird dann an jeder Schicht angepasst und weiter zurückgeschickt. Hier ist ein Diagramm zur Darstellung der Backpropagation:

Verständnis mit Beispiel
Word2vec verwendet eine einzelne versteckte Schicht, vollständig verbundenes neuronales Netzwerk, wie unten gezeigt. Die Neuronen in der verborgenen Schicht sind alle lineare Neuronen. Die Eingangsschicht ist so eingestellt, dass sie so viele Neuronen enthält, wie Wörter im Vokabular für das Training vorhanden sind. Die Größe der ausgeblendeten Ebene wird auf die Dimensionalität der resultierenden Wortvektoren festgelegt. Die Größe der Ausgabeebene entspricht der der Eingabeebene. Wenn also das Vokabular zum Lernen von Wortvektoren aus V Wörtern besteht und N die Dimension von Wortvektoren ist, kann die Eingabe in versteckte Schichtverbindungen durch eine Matrix WI der Größe VxN dargestellt werden, wobei jede Zeile ein Vokabularwort darstellt. In gleicher Weise können die Verbindungen von versteckter Schicht zu Ausgangsschicht durch Matrix WO der Größe NxV beschrieben werden. In diesem Fall repräsentiert jede Spalte der Matrix ein Wort aus dem gegebenen Vokabular.

Die Eingabe in das Netzwerk wird mit der Darstellung „1-out of -V“ codiert, was bedeutet, dass nur eine Eingangsleitung auf eins und die restlichen Eingangsleitungen auf Null gesetzt werden.
Angenommen, wir haben ein Trainingskorpus mit den folgenden Sätzen:
„Der Hund sah eine Katze“, „Der Hund jagte die Katze“, „Die Katze kletterte auf einen Baum“
Das Korpus-Vokabular besteht aus acht Wörtern. Einmal alphabetisch geordnet, kann jedes Wort durch seinen Index referenziert werden. In diesem Beispiel hat unser neuronales Netzwerk acht Eingangsneuronen und acht Ausgangsneuronen. Nehmen wir an, wir beschließen, drei Neuronen in der verborgenen Schicht zu verwenden. Dies bedeutet, dass WI und WO jeweils 8 × 3- und 3 × 8-Matrizen sind. Bevor das Training beginnt, werden diese Matrizen auf kleine Zufallswerte initialisiert, wie es beim neuronalen Netzwerktraining üblich ist. Nehmen wir zur Veranschaulichung an, dass WI und WO auf die folgenden Werte initialisiert werden:

Angenommen, wir möchten, dass das Netzwerk die Beziehung zwischen den Wörtern „Katze“ und „Hund“ lernt. Das heißt, das Netzwerk sollte eine hohe Wahrscheinlichkeit für „geklettert“ zeigen, wenn „cat“ in das Netzwerk eingegeben wird. In der Terminologie der Worteinbettung wird das Wort „Katze“ als Kontextwort und das Wort „Hund“ als Zielwort bezeichnet. In diesem Fall ist der Eingangsvektor X t. Beachten Sie, dass nur die zweite Komponente des Vektors 1 ist. Dies liegt daran, dass das Eingabewort „cat“ ist, das die Nummer zwei in der sortierten Liste der Korpuswörter einnimmt. Da das Zielwort „Katze“ ist, sieht der Zielvektor wie folgt aus: t. Wenn der Eingabevektor „Katze“ darstellt, kann die Ausgabe an den Neuronen der verborgenen Schicht wie folgt berechnet werden:
Ht = XtWI =
Es sollte uns nicht überraschen, dass der Vektor H der Ausgaben versteckter Neuronen die Gewichte der zweiten Zeile der WI-Matrix aufgrund von 1-out-of-Vrepresentation nachahmt. Die Funktion der Verbindungen zwischen Eingabe und versteckter Ebene besteht also im Wesentlichen darin, den Eingabewortvektor in die versteckte Ebene zu kopieren. Bei ähnlichen Manipulationen für die Eingabe in die Ausgabeschicht kann der Aktivierungsvektor für Neuronen der Ausgabeschicht als
HtWO =
Da das Ziel darin besteht, Wahrscheinlichkeiten für Wörter in der Ausgabeschicht zu erzeugen, Pr(wordk | wordcontext) für k = 1, V, um ihre nächste Wortbeziehung mit dem Kontextwort bei der Eingabe widerzuspiegeln, müssen wir die Summe der Neuronenausgaben in der Ausgabeschicht zu einer addieren. Word2vec erreicht dies, indem Aktivierungswerte von Neuronen der Ausgangsschicht mithilfe der Softmax-Funktion in Wahrscheinlichkeiten umgewandelt werden. Somit wird die Ausgabe des k-ten Neurons durch den folgenden Ausdruck berechnet, wobei die Aktivierung (n) den Aktivierungswert des n-ten Ausgangsschichtneurons darstellt:
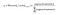
Somit sind die Wahrscheinlichkeiten für acht Wörter im Korpus:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
Die fettgedruckte Wahrscheinlichkeit ist für das gewählte Zielwort „geklettert“. Bei dem Zielvektor t wird der Fehlervektor für die Ausgangsschicht leicht berechnet, indem der Wahrscheinlichkeitsvektor vom Zielvektor subtrahiert wird. Sobald der Fehler bekannt ist, können die Gewichte in den Matrizen WO und WI mit backpropagation aktualisiert werden. Somit kann das Training fortgesetzt werden, indem verschiedene Kontext-Ziel-Wörterpaare aus dem Korpus präsentiert werden. So lernt Word2vec Zusammenhänge zwischen Wörtern und entwickelt dabei Vektordarstellungen für Wörter im Korpus.
Die Idee hinter word2vec besteht darin, Wörter durch einen Vektor reeller Zahlen der Dimension d darzustellen. Daher ist die zweite Matrix die Darstellung dieser Wörter. Die i-te Linie dieser Matrix ist die Vektordarstellung des i-ten Wortes. Nehmen wir an, dass Sie in Ihrem Beispiel 5 Wörter haben: , dann bedeutet der erste Vektor, dass Sie das Wort „Pferd“ betrachten und so die Darstellung von „Pferd“ ist . Ähnlich ist die Darstellung des Wortes „Löwe“.

Meines Wissens gibt es keine „menschliche Bedeutung“ speziell für jede der Zahlen in diesen Darstellungen. Eine Zahl repräsentiert nicht, ob das Wort ein Verb ist oder nicht, ein Adjektiv oder nicht … Es sind nur die Gewichte, die Sie ändern, um Ihr Optimierungsproblem zu lösen und die Darstellung Ihrer Wörter zu lernen.
Ein visuelles Diagramm zur Ausarbeitung des word2vec-Matrixmultiplikationsprozesses ist in der folgenden Abbildung dargestellt:

Die erste Matrix repräsentiert den Eingangsvektor in einem heißen Format. Die zweite Matrix repräsentiert die synaptischen Gewichte von den Neuronen der Eingangsschicht zu den Neuronen der verborgenen Schicht. Beachten Sie insbesondere die linke obere Ecke, in der die Eingabeschichtmatrix mit der Gewichtsmatrix multipliziert wird. Schauen Sie sich nun oben rechts an. Diese Matrixmultiplikation InputLayer dot-produced mit Gewichten Transponieren ist nur eine praktische Möglichkeit, das neuronale Netzwerk oben rechts darzustellen.
Der erste Teil repräsentiert das Eingangswort als einen heißen Vektor und die andere Matrix repräsentiert das Gewicht für die Verbindung jedes der Neuronen der Eingangsschicht mit den Neuronen der verborgenen Schicht. Als Word2Vec Züge, backpropagates es (mit Gradient descent) in diese Gewichte und ändert sie, um bessere Darstellungen von Wörtern als Vektoren zu geben. Sobald das Training abgeschlossen ist, verwenden Sie nur diese Gewichtsmatrix, nehmen Sie zum Beispiel ‚Hund‘ und multiplizieren Sie sie mit der verbesserten Gewichtsmatrix, um die Vektordarstellung von ‚Hund‘ in einer Dimension = Nein der Neuronen der versteckten Schicht zu erhalten. Im Diagramm beträgt die Anzahl der Neuronen der verborgenen Ebene 3.
Kurz gesagt, das Skip-Gram-Modell kehrt die Verwendung von Ziel- und Kontextwörtern um. In diesem Fall wird das Zielwort am Eingang zugeführt, die verborgene Schicht bleibt gleich und die Ausgangsschicht des neuronalen Netzwerks wird mehrmals repliziert, um die gewählte Anzahl von Kontextwörtern aufzunehmen. Am Beispiel von „Katze“ und „Baum“ als Kontextwörter und „Baum“ als Zielwort wäre der Eingangsvektor im Skim-Gram-Modell t , während die beiden Ausgangsschichten t bzw. t als Zielvektoren hätten. Anstelle der Erzeugung eines Vektors von Wahrscheinlichkeiten würden für das aktuelle Beispiel zwei solcher Vektoren erzeugt. Der Fehlervektor für jede Ausgangsschicht wird in der oben diskutierten Weise erzeugt. Die Fehlervektoren aus allen Ausgangsschichten werden jedoch summiert, um die Gewichte über Backpropagation anzupassen. Dies stellt sicher, dass die Gewichtsmatrix WO für jede Ausgabeschicht während des gesamten Trainings identisch bleibt.
Wir benötigen einige zusätzliche Modifikationen am grundlegenden Skip-Gram-Modell, die wichtig sind, um das Training zu ermöglichen. Das Ausführen eines Gradientenabstiegs in einem so großen neuronalen Netzwerk wird langsam sein. Und um die Sache noch schlimmer zu machen, benötigen Sie eine große Menge an Trainingsdaten, um so viele Gewichte abzustimmen und eine Überanpassung zu vermeiden. millionen von Gewichten mal Milliarden von Trainingsproben bedeuten, dass das Training dieses Modells ein Biest sein wird. Zu diesem Zweck haben die Autoren zwei Techniken vorgeschlagen, die als Subsampling und negative Sampling bezeichnet werden und bei denen unbedeutende Wörter entfernt und nur eine bestimmte Stichprobe von Gewichten aktualisiert wird.
Mikolov et al. verwenden Sie auch einen einfachen Subsampling-Ansatz, um dem Ungleichgewicht zwischen seltenen und häufigen Wörtern im Trainingssatz entgegenzuwirken (z. B. „in“, „the“ und „a“ bieten weniger Informationswert als seltene Wörter). Jedes Wort im Trainingssatz wird mit der Wahrscheinlichkeit P (wi) verworfen, wobei

f (wi) ist die Häufigkeit des Wortes wi und t ist eine gewählte Schwelle, typischerweise um 10-5.
Implementierungsdetails
Word2vec wurde in verschiedenen Sprachen implementiert, aber hier werden wir uns besonders auf Java konzentrieren, dh., DeepLearning4j , darks-Learning und Python . Verschiedene neuronale Netzalgorithmen wurden in DL4j implementiert, Code ist auf GitHub verfügbar.
Um es in DL4j zu implementieren, werden wir einige Schritte wie folgt ausführen:
a) Word2Vec Setup
Erstellen Sie mit Maven ein neues Projekt in IntelliJ. Geben Sie dann Eigenschaften und Abhängigkeiten im POM an.XML-Datei im Stammverzeichnis Ihres Projekts.
b) Daten laden
Erstellen und benennen Sie nun eine neue Klasse in Java. Danach nehmen Sie die rohen Sätze in Ihre .durchlaufen Sie sie mit Ihrem Iterator und unterziehen Sie sie einer Vorverarbeitung, z. B. der Konvertierung aller Wörter in Kleinbuchstaben.
String filePath = new ClassPathResource(„raw_sätze“.txt“).In: getFile().getAbsolutePath();
log.info („Load & Sätze vektorisieren….“);
// Leerzeichen vor und nach jeder Zeile entfernen
SentenceIterator iter = new BasicLineIterator(filePath);
Wenn Sie neben den in unserem Beispiel angegebenen Sätzen eine Textdatei laden möchten, tun Sie dies:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenisieren der Daten
Word2vec muss Wörter anstelle von ganzen Sätzen erhalten, daher besteht der nächste Schritt darin, die Daten zu tokenisieren. Um einen Text zu tokenisieren, müssen Sie ihn in seine atomaren Einheiten aufteilen und jedes Mal, wenn Sie auf einen Leerraum treffen, ein neues Token erstellen.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Training des Modells
Nachdem die Daten fertig sind, können Sie das neuronale Netz Word2vec konfigurieren und die Token einspeisen.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Diese Konfiguration akzeptiert mehrere Hyperparameter. Einige erfordern eine Erklärung:
- BatchSize ist die Anzahl der Wörter, die Sie gleichzeitig verarbeiten.
- minWordFrequency gibt an, wie oft ein Wort mindestens im Korpus vorkommen muss. Hier, wenn es weniger als 5 mal erscheint, wird es nicht gelernt. Wörter müssen in mehreren Kontexten erscheinen, um nützliche Funktionen über sie zu erfahren. In sehr großen Korpora ist es sinnvoll, das Minimum zu erhöhen.
- useAdaGrad – Adagrad erstellt für jedes Feature einen anderen Verlauf. Hier geht es uns nicht darum.
- layerSize gibt die Anzahl der Features im Wortvektor an. Dies entspricht der Anzahl der Dimensionen im Featurespace. Wörter, die durch 500 Merkmale dargestellt werden, werden zu Punkten in einem 500-dimensionalen Raum.
- Lernrate ist die Schrittweite für jede Aktualisierung der Koeffizienten, da Wörter im Merkmalsraum neu positioniert werden.
- minLearningRate ist der Boden auf der Lernrate. Die Lernrate nimmt ab, wenn die Anzahl der Wörter, mit denen Sie trainieren, abnimmt. Wenn die Lernrate zu stark schrumpft, ist das Lernen im Netz nicht mehr effizient. Dies hält die Koeffizienten in Bewegung.
- iterate teilt dem Netz mit, auf welchem Stapel des Datensatzes trainiert wird.
- tokenizer füttert es mit den Wörtern aus dem aktuellen Stapel.
- Vzgl.fit() weist das konfigurierte Netz an, mit dem Training zu beginnen.
e) Evaluieren des Modells mit Word2vec
Der nächste Schritt besteht darin, die Qualität Ihrer Merkmalsvektoren zu bewerten.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
Die Zeile vec.similarity("word1","word2") gibt die Kosinusähnlichkeit der beiden eingegebenen Wörter zurück. Je näher es an 1 ist, desto ähnlicher nimmt das Netz diese Wörter wahr (siehe das Beispiel Schweden-Norwegen oben). Beispielsweise:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
Mit vec.wordsNearest("word1", numWordsNearest) können Sie anhand der auf dem Bildschirm gedruckten Wörter feststellen, ob das Netz semantisch ähnliche Wörter gruppiert hat. Mit dem zweiten Parameter von wordsNearest können Sie die Anzahl der nächsten Wörter festlegen. Zum Beispiel:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec auf Java in http://deeplearning4j.org/word2vec.html
7) Word2Vec und Doc2Vec in Python im Genismus http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html