- Was sind interne Links?
- Codebeispiel
- Optimales Format
- Was ist ein interner Link?
- SEO Best Practice
- Links in einreichungspflichtigen Formularen
- Links, auf die nur über interne Suchfelder zugegriffen werden kann
- Links in nicht analysierbarem Javascript
- Links in Flash, Java oder anderen Plug-Ins
- Links, die auf Seiten verweisen, die durch das Meta Robots-Tag oder die Robots blockiert sind.txt
- Links auf Seiten mit Hunderten oder Tausenden von Links
- Links in Frames oder I-Frames
- Lerne weiter
Was sind interne Links?
Interne Links sind Hyperlinks, die auf (Ziel-) dieselbe Domain verweisen wie die Domain, auf der der Link existiert (Quelle). In Laienbegriffen ist ein interner Link einer, der auf eine andere Seite derselben Website verweist.
Codebeispiel
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
Optimales Format
Verwenden Sie beschreibende Schlüsselwörter im Ankertext, die ein Gefühl für das Thema oder die Schlüsselwörter vermitteln, auf die die Quellseite abzielt.
Was ist ein interner Link?
Interne Links sind Links, die von einer Seite einer Domain zu einer anderen Seite derselben Domain führen. Sie werden häufig in der Hauptnavigation verwendet.
Diese Art von Links sind aus drei Gründen nützlich:
- Sie ermöglichen es Benutzern, auf einer Website zu navigieren.
- Sie helfen dabei, die Informationshierarchie für die angegebene Website festzulegen.
- Sie helfen, Link-Equity (Ranking-Power) auf Websites zu verbreiten.
SEO Best Practice
Interne Links sind am nützlichsten, um die Site-Architektur zu etablieren und Link-Gerechtigkeit zu verbreiten (URLs sind ebenfalls unerlässlich). Aus diesem Grund geht es in diesem Abschnitt um den Aufbau einer SEO-freundlichen Site-Architektur mit internen Links.
Auf einer einzelnen Seite müssen Suchmaschinen Inhalte sehen, um Seiten in ihren massiven Keyword–basierten Indizes aufzulisten. Sie müssen auch Zugriff auf eine crawlbare Linkstruktur haben — eine Struktur, mit der Spinnen die Pfade einer Website durchsuchen können —, um alle Seiten einer Website zu finden. Hunderttausende von Websites machen den kritischen Fehler, ihre Hauptlink-Navigation auf eine Weise zu verbergen oder zu vergraben, auf die Suchmaschinen nicht zugreifen können. Dies behindert ihre Fähigkeit, Seiten in den Indizes der Suchmaschinen aufgeführt zu bekommen. Im Folgenden wird veranschaulicht, wie dieses Problem auftreten kann:
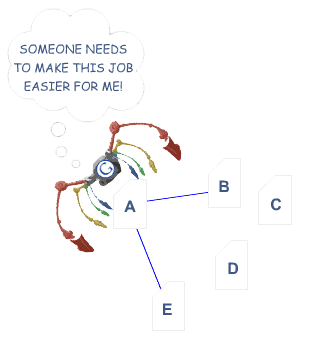
Im obigen Beispiel hat Googles bunte Spinne die Seite „A“ erreicht und sieht interne Links zu den Seiten „B“ und „E“. Wie wichtig die Seiten C und D für die Website auch sein mögen, die Spinne hat keine Möglichkeit, sie zu erreichen — oder gar zu wissen, dass sie existieren —, da keine direkten, crawlbaren Links auf diese Seiten verweisen. Für Google gibt es diese Seiten im Grunde nicht – großartige Inhalte, gutes Keyword-Targeting und intelligentes Marketing machen überhaupt keinen Unterschied, wenn die Spinnen diese Seiten überhaupt nicht erreichen können.
Die optimale Struktur für eine Website würde ähnlich einer Pyramide aussehen (wobei der große Punkt oben homepage ist):
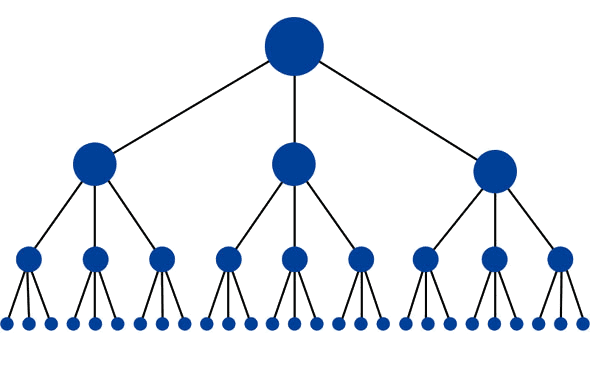
Diese Struktur hat die minimale Anzahl von Links, die zwischen der Homepage und einer bestimmten Seite möglich sind. Dies ist hilfreich, da Link-Equity (Ranking-Power) über die gesamte Website fließen kann, wodurch das Ranking-Potenzial für jede Seite erhöht wird. Diese Struktur ist auf vielen leistungsstarken Websites (wie Amazon.com ) in Form von Kategorie- und Unterkategoriesystemen.
Aber wie wird das erreicht? Der beste Weg, dies zu tun, ist mit internen Links und ergänzenden URL-Strukturen. Sie verlinken beispielsweise intern auf eine Seite unter http://www.example.com/mammals… mit dem Ankertext „Katzen.“ Unten ist das Format für einen korrekt formatierten internen Link. Stellen Sie sich vor, dieser Link befindet sich in der Domain jonwye.com.

In der obigen Abbildung zeigt das „a“ -Tag den Beginn eines Links an. Link-Tags können Bilder, Text oder andere Objekte enthalten, die alle einen „anklickbaren“ Bereich auf der Seite bieten, den Benutzer aktivieren können, um zu einer anderen Seite zu wechseln. Dies ist das ursprüngliche Konzept des Internets: „Hyperlinks.“ Der Verweisort des Links teilt dem Browser — und den Suchmaschinen — mit, wohin der Link zeigt. In diesem Beispiel wird auf die URL http://www.jonwye.com verwiesen. Als nächstes beschreibt der sichtbare Teil des Links für Besucher, der in der SEO-Welt als „Ankertext“ bezeichnet wird, die Seite, auf die der Link verweist. In diesem Beispiel, Auf der Seite, auf die verwiesen wurde, geht es um benutzerdefinierte Gürtel, die von einem Mann namens Jon Wye hergestellt wurden, Daher verwendet der Link den Ankertext „Jon Wyes benutzerdefinierte Gürtel.“ Das </a> -Tag schließt den Link, sodass auf Elemente später auf der Seite nicht das Link-Attribut angewendet wird.
Dies ist das grundlegendste Format eines Links – und es ist für die Suchmaschinen hervorragend verständlich. Die Suchmaschinen-Spider wissen, dass sie diesen Link zum Link-Diagramm der Suchmaschine im Web hinzufügen, ihn verwenden sollten, um abfrageunabhängige Variablen (wie MozRank) zu berechnen, und ihm folgen sollten, um den Inhalt der referenzierten Seite zu indizieren.
Im Folgenden finden Sie einige häufige Gründe, warum Seiten möglicherweise nicht erreichbar sind und daher möglicherweise nicht indiziert werden.
Links in einreichungspflichtigen Formularen
Formulare können so grundlegende Elemente wie ein Dropdown–Menü oder so komplexe Elemente wie eine vollständige Umfrage enthalten. In beiden Fällen versuchen Suchspinnen nicht, Formulare zu „senden“, und daher sind Inhalte oder Links, auf die über ein Formular zugegriffen werden kann, für die Suchmaschinen unsichtbar.
Links, auf die nur über interne Suchfelder zugegriffen werden kann
Spinnen werden nicht versuchen, Suchvorgänge durchzuführen, um Inhalte zu finden, und daher wird geschätzt, dass Millionen von Seiten hinter völlig unzugänglichen internen Suchfeldwänden verborgen sind.
Links in nicht analysierbarem Javascript
Links, die mit Javascript erstellt wurden, können je nach Implementierung entweder nicht gecrawlt oder im Gewicht abgewertet werden. Aus diesem Grund wird empfohlen, Standard-HTML-Links anstelle von Javascript-basierten Links auf jeder Seite zu verwenden, auf der der von Suchmaschinen verwiesene Datenverkehr wichtig ist.
Links in Flash, Java oder anderen Plug-Ins
Links, die in Flash, Java-Applets und anderen Plug-Ins eingebettet sind, sind für Suchmaschinen normalerweise nicht zugänglich.
Links, die auf Seiten verweisen, die durch das Meta Robots-Tag oder die Robots blockiert sind.txt
Das Meta-Robots-Tag und die Robots.txt-Datei beide ermöglichen es einem Websitebesitzer, den Spider-Zugriff auf eine Seite einzuschränken.
Links auf Seiten mit Hunderten oder Tausenden von Links
Die Suchmaschinen haben alle ein grobes Crawling-Limit von 150 Links pro Seite, bevor sie möglicherweise aufhören, zusätzliche Seiten zu durchsuchen, auf die von der Originalseite aus verlinkt wurde. Dieses Limit ist etwas flexibel, und besonders wichtige Seiten können mehr als 200 oder sogar 250 Links haben, aber in der allgemeinen Praxis ist es ratsam, die Anzahl der Links auf einer bestimmten Seite auf 150 zu begrenzen oder die Möglichkeit zu verlieren, zusätzliche Seiten zu crawlen.
Links in Frames oder I-Frames
Technisch gesehen sind Links sowohl in Frames als auch in I-Frames crawlbar, aber beide stellen strukturelle Probleme für die Engines in Bezug auf Organisation und Nachverfolgung dar. Nur fortgeschrittene Benutzer mit einem guten technischen Verständnis dafür, wie Suchmaschinen Links in Frames indizieren und folgen, sollten diese Elemente in Kombination mit internen Links verwenden.
Durch die Vermeidung dieser Fallstricke kann ein Webmaster saubere, spiderable HTML-Links haben, die den Spidern einen einfachen Zugriff auf ihre Inhaltsseiten ermöglichen. Auf Links können zusätzliche Attribute angewendet werden, aber die Engines ignorieren fast alle diese Attribute, mit der wichtigen Ausnahme des rel="nofollow" -Tags.
Möchten Sie einen schnellen Einblick in die Indexierung Ihrer Website erhalten? Verwenden Sie ein Tool wie Moz Pro, Link Explorer oder Screaming Frog, um einen Site-Crawl durchzuführen. Vergleichen Sie dann die Anzahl der Seiten, die beim Crawlen angezeigt wurden, mit der Anzahl der Seiten, die beim Ausführen einer Website aufgeführt sind: Suchen Sie in Google.
Rel=“nofollow“ kann mit der folgenden Syntax verwendet werden:
<pre><a href=“/“ rel=“nofollow“>nofollow this link</a></pre>
In diesem Beispiel teilt der Webmaster durch Hinzufügen des Attributs rel="nofollow" zum Link-Tag der Suche beachten Sie, dass sie nicht möchten, dass dieser Link als normale, „vorübergehende“ redaktionelle Abstimmung interpretiert wird.“ Nofollow entstand als eine Methode, um automatisierten Blog-Kommentar-, Gästebuch- und Link-Injection-Spam zu stoppen, hat sich aber im Laufe der Zeit in eine Möglichkeit verwandelt, den Engines mitzuteilen, dass sie jeden Link-Wert, der normalerweise übergeben wird, abwerten sollen. Mit nofollow getaggte Links werden von den einzelnen Engines etwas anders interpretiert.
Lerne weiter
- Ankertext
- Link Equity
- Webmaster-Richtlinien Googles offizielle Richtlinien für Webmaster.
- Textlinks und PageRank Matt Cutts, ehemaliger Leiter des Webspam-Teams bei Google, Gedanken zu Hyperlinks in Bezug auf SEO und Google.