Non-Uniform Memory Access (NUMA) ist eine Shared-Memory-Architektur, die in heutigen Multiprozessorsystemen verwendet wird. Jeder CPU wird ein eigener lokaler Speicher zugewiesen und kann von anderen CPUs im System auf Speicher zugreifen. Der lokale Speicherzugriff bietet eine niedrige Latenz – hohe Bandbreitenleistung. Während der Zugriff auf Speicher, der der anderen CPU gehört, eine höhere Latenz und eine geringere Bandbreitenleistung aufweist. Moderne Anwendungen und Betriebssysteme wie ESXi unterstützen NUMA standardmäßig, doch um die beste Leistung zu erzielen, sollte die Konfiguration der virtuellen Maschine unter Berücksichtigung der NUMA-Architektur erfolgen. Bei falschem Design treten für diese bestimmte virtuelle Maschine oder im schlimmsten Fall für alle auf diesem ESXi-Host ausgeführten VMs inkonsequentes Verhalten oder allgemeine Leistungseinbußen auf.
Diese Serie soll Einblicke in die CPU-Architektur, das Speichersubsystem und den ESXi-CPU- und Speicherplaner geben. So können Sie eine leistungsstarke Plattform schaffen, die die Grundlage für höhere Services und höhere Konsolidierungsquoten legt. Bevor wir zu modernen Rechenarchitekturen kommen, ist es hilfreich, die Geschichte der Shared-Memory-Multiprozessorarchitekturen zu lesen, um zu verstehen, warum wir heute NUMA-Systeme verwenden.
- Die Entwicklung der Shared-Memory-Multiprozessorarchitektur in den letzten Jahrzehnten
- Einführung von Caching-Snoop-Protokollen
- Einheitliche Speicherzugriffsarchitektur
- Uneinheitliche Speicherzugriffsarchitektur
- 1: Non-Uniform Memory Access organization
- 2: Punkt-zu-Punkt-Verbindung
- 3: Skalierbare Cache-Kohärenz
- Nicht verschachtelt aktiviert NUMA = SUMA
- Nehalem & Überblick über die Kernmikroarchitektur
Es scheint, dass eine Architektur namens Uniform Memory Access besser zum Entwerfen einer konsistenten Plattform mit niedriger Latenz und hoher Bandbreite geeignet wäre. Moderne Systemarchitekturen werden es jedoch daran hindern, wirklich einheitlich zu sein. Um den Grund dafür zu verstehen, müssen wir in der Geschichte zurückgehen, um die wichtigsten Treiber des Parallel Computing zu identifizieren.
Mit der Einführung relationaler Datenbanken in den frühen siebziger Jahren wurde der Bedarf an Systemen, die mehrere gleichzeitige Benutzeroperationen und übermäßige Datengenerierung bedienen konnten, zum Mainstream. Trotz der beeindruckenden Uniprozessorleistung waren Multiprozessorsysteme für diese Arbeitslast besser gerüstet. Um ein kostengünstiges System bereitzustellen, wurde der gemeinsame Speicheradressraum in den Mittelpunkt der Forschung gerückt. Früh wurden Systeme mit einem Crossbar-Switch befürwortet, jedoch mit dieser Designkomplexität, die mit der Zunahme von Prozessoren skaliert wurde, was das busbasierte System attraktiver machte. Prozessoren in einem Bussystem können auf den gesamten Speicherplatz zugreifen, indem sie Anfragen auf dem Bus senden, eine sehr kostengünstige Möglichkeit, den verfügbaren Speicher so optimal wie möglich zu nutzen.
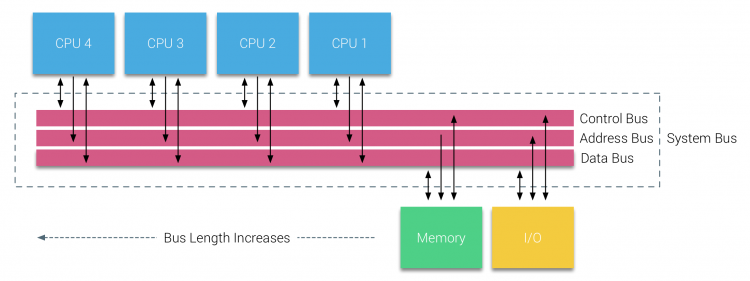
Busbasierte Systeme haben jedoch ihre eigenen Skalierbarkeitsprobleme. Das Hauptproblem ist die begrenzte Bandbreite, dies schränkt die Anzahl der Prozessoren ein, die der Bus aufnehmen kann. Das Hinzufügen von CPUs zum System führt zu zwei Hauptproblemen:
- Die verfügbare Bandbreite pro Knoten nimmt mit jeder hinzugefügten CPU ab.
- Die Buslänge nimmt zu, wenn mehr Prozessoren hinzugefügt werden, wodurch die Latenz erhöht wird.
Das Leistungswachstum der CPU und insbesondere die Geschwindigkeitslücke zwischen Prozessor und Speicherleistung war und ist für Multiprozessoren verheerend. Da erwartet wurde, dass die Speicherlücke zwischen Prozessor und Speicher größer wird, wurden große Anstrengungen unternommen, um effektive Strategien zur Verwaltung der Speichersysteme zu entwickeln. Eine dieser Strategien war das Hinzufügen von Speichercache, was eine Vielzahl von Herausforderungen mit sich brachte. Die Lösung dieser Herausforderungen ist immer noch das Hauptaugenmerk der heutigen CPU-Design-Teams, eine Menge Forschung wird auf Caching-Strukturen und ausgefeilte Algorithmen getan, um Cache-Misses zu vermeiden.
Einführung von Caching-Snoop-Protokollen
Das Anhängen eines Caches an jede CPU erhöht die Leistung in vielerlei Hinsicht. Wenn der Speicher näher an die CPU herangeführt wird, verringert sich die durchschnittliche Speicherzugriffszeit und gleichzeitig die Bandbreitenlast auf dem Speicherbus. Die Herausforderung beim Hinzufügen von Cache zu jeder CPU in einer Shared-Memory-Architektur besteht darin, dass mehrere Kopien eines Speicherblocks vorhanden sein können. Dies wird als Cache-Kohärenzproblem bezeichnet. Um dies zu lösen, wurden Caching-Snoop-Protokolle erfunden, um ein Modell zu erstellen, das die richtigen Daten bereitstellt, ohne die gesamte Bandbreite auf dem Bus zu verbrauchen. Das beliebteste Protokoll, write invalidate, löscht alle anderen Datenkopien, bevor der lokale Cache geschrieben wird. Jedes nachfolgende Lesen dieser Daten durch andere Prozessoren erkennt einen Cache-Fehler in ihrem lokalen Cache und wird aus dem Cache einer anderen CPU bedient, die die zuletzt geänderten Daten enthält. Dieses Modell sparte viel Busbandbreite und ermöglichte die Entstehung einheitlicher Speicherzugriffssysteme in den frühen 1990er Jahren. Moderne Cache-Kohärenzprotokolle werden in Teil 3 ausführlicher behandelt.
Einheitliche Speicherzugriffsarchitektur
Prozessoren von busbasierten Multiprozessoren, die die gleiche – einheitliche – Zugriffszeit auf jedes Speichermodul im System haben, werden häufig als UMA–Systeme (Uniform Memory Access) oder Symmetrische Multiprozessoren (Symmetric Multi-Processors, SMPs) bezeichnet.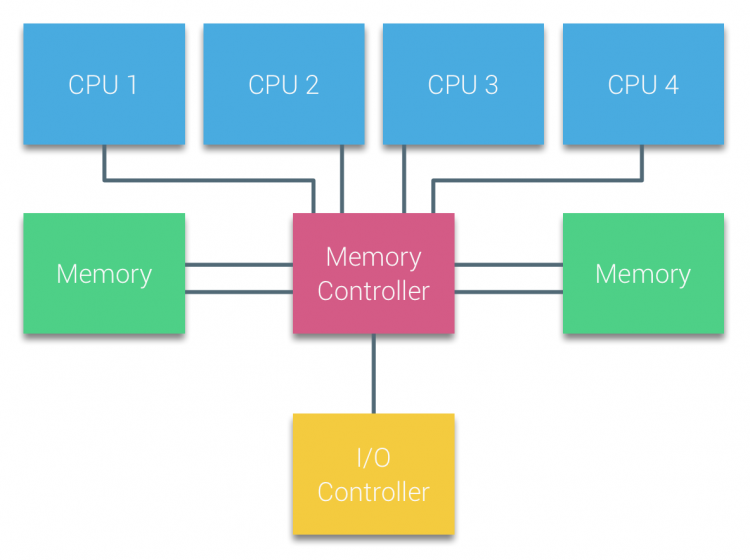
Bei UMA-Systemen sind die CPUs über einen Systembus (Front-Side-Bus) mit der Northbridge verbunden. Die Northbridge enthält den Speichercontroller und die gesamte Kommunikation zum und vom Speicher muss über die Northbridge erfolgen. Der E / A-Controller, der für die Verwaltung der E / A für alle Geräte verantwortlich ist, ist mit der Northbridge verbunden. Daher muss jede E / A durch die Northbridge gehen, um die CPU zu erreichen.
Mehrere Busse und Speicherkanäle werden verwendet, um die verfügbare Bandbreite zu verdoppeln und den Engpass der Northbridge zu reduzieren. Um die Speicherbandbreite noch weiter zu erhöhen, schlossen einige Systeme externe Speichercontroller an die Northbridge an, wodurch die Bandbreite und die Unterstützung von mehr Speicher verbessert wurden. Aufgrund der internen Bandbreite der Northbridge und des Broadcasting-Charakters früher Snoopy-Cache-Protokolle wurde UMA jedoch als begrenzt skalierbar angesehen. Mit dem heutigen Einsatz von Hochgeschwindigkeits-Flash-Geräten, die Hunderttausende von E / A pro Sekunde übertragen, hatten sie absolut Recht, dass diese Architektur für zukünftige Workloads nicht skalierbar sein würde.
Uneinheitliche Speicherzugriffsarchitektur
Zur Verbesserung der Skalierbarkeit und Leistung werden drei wichtige Änderungen an der Shared-Memory-Multiprozessorarchitektur vorgenommen;
- Uneinheitliche Speicherzugriffsorganisation
- Punkt-zu-Punkt-Verbindungstopologie
- Skalierbare Cache-Kohärenzlösungen
1: Non-Uniform Memory Access organization
NUMA entfernt sich von einem zentralisierten Speicherpool und führt topologische Eigenschaften ein. Durch die Klassifizierung des Speicherplatzes basierend auf der Signalweglänge vom Prozessor zum Speicher können Latenz- und Bandbreitenengpässe vermieden werden. Dies geschieht durch Neugestaltung des gesamten Systems von Prozessor und Chipsatz. NUMA-Architekturen wurden Ende der 90er Jahre populär, als sie auf SGI-Supercomputern wie dem Cray Origin 2000 verwendet wurden. NUMA half, den Speicherort zu identifizieren, in diesem Fall dieser Systeme mussten sie sich fragen, welcher Speicherbereich in welchem Chassis die Speicherbits enthielt.
In der ersten Hälfte des Millennium-Jahrzehnts brachte AMD NUMA in die Unternehmenslandschaft, in der UMA-Systeme die Oberhand behielten. Im Jahr 2003 wurde die AMD Opteron-Familie mit integrierten Speichercontrollern eingeführt, wobei jede CPU bestimmte Speicherbänke besitzt. Jede CPU hat jetzt einen eigenen Speicheradressraum. Ein NUMA-optimiertes Betriebssystem wie ESXi ermöglicht es Workloads, Speicher aus beiden Speicheradressräumen zu verbrauchen und gleichzeitig den lokalen Speicherzugriff zu optimieren. Lassen Sie uns ein Beispiel für ein Zwei-CPU-System verwenden, um die Unterscheidung zwischen lokalem und Remote-Speicherzugriff innerhalb eines einzelnen Systems zu verdeutlichen.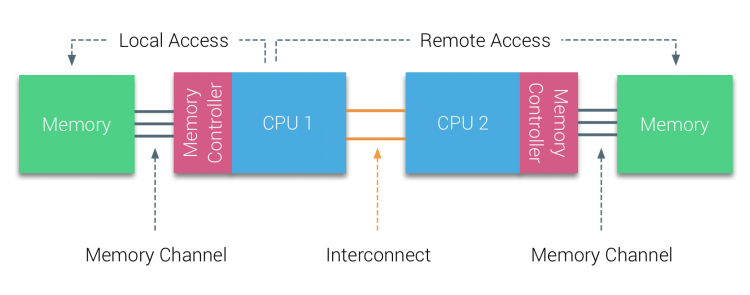
Der an den Speichercontroller der CPU1 angeschlossene Speicher gilt als lokaler Speicher. Speicher, der an einen anderen CPU-Sockel (CPU2) angeschlossen ist, gilt für CPU1 als fremd oder entfernt. Der Remote-Speicherzugriff hat einen zusätzlichen Latenzaufwand für den lokalen Speicherzugriff, da er eine Verbindung (Punkt-zu-Punkt-Verbindung) durchlaufen und eine Verbindung zum Remote-Speichercontroller herstellen muss. Aufgrund der unterschiedlichen Speicherplätze erfährt dieses System eine „ungleichmäßige“ Speicherzugriffszeit.
2: Punkt-zu-Punkt-Verbindung
AMD hat seine Punkt-zu-Punkt-Verbindung HyperTransport mit der AMD Opteron-Mikroarchitektur eingeführt. Intel entfernte sich 2007 von seiner Dual Independent Bus-Architektur, indem es die QuickPath-Architektur in das Design der Nehalem-Prozessorfamilie einführte.
Die Nehalem-Architektur war eine bedeutende Designänderung innerhalb der Intel-Mikroarchitektur und gilt als die erste echte Generation der Intel Core-Serie. Die aktuelle Broadwell-Architektur ist die 4. Generation der Marke Intel Core (Intel Xeon E5 v4), der letzte Absatz enthält weitere Informationen zu den Mikroarchitekturgenerationen. Innerhalb der QuickPath-Architektur bewegten sich die Speichercontroller zur CPU und führten den QuickPath Point-to-Point Interconnect (QPI) als Datenverbindungen zwischen CPUs im System ein.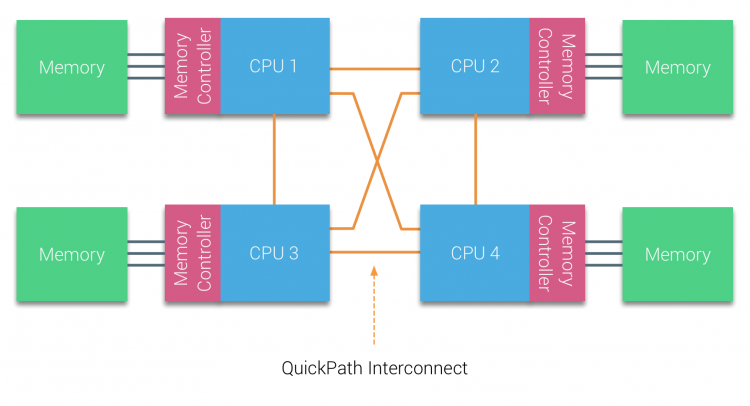
Die Nehalem-Mikroarchitektur ersetzte nicht nur den älteren Front-Side-Bus, sondern reorganisierte das gesamte Subsystem in ein modulares Design für die Server-CPU. Dieses modulare Design wurde als „Uncore“ eingeführt und erstellt eine Bausteinbibliothek für Caching- und Verbindungsgeschwindigkeiten. Das Entfernen des frontseitigen Busses verbessert die Skalierbarkeit der Bandbreite, dennoch muss die Intra- und Interprozessorkommunikation gelöst werden, wenn es um enorme Mengen an Speicherkapazität und Bandbreite geht. Sowohl der integrierte Speichercontroller als auch die QuickPath-Verbindungen sind Teil des Uncore und modellspezifische Register (MSR). Sie verbinden sich mit einem MSR, der die Intra- und Interprozessorkommunikation bereitstellt. Die Modularität des Uncore ermöglicht es Intel auch, unterschiedliche QPI-Geschwindigkeiten anzubieten, zum Zeitpunkt des Schreibens bietet die Intel Broadwell-EP-Mikroarchitektur (2016) 6, 4 Giga-Transfers pro Sekunde (GT / s), 8, 0 GT / s und 9, 6 GT / s. Jeweils eine theoretische maximale Bandbreite von 25, 6 GB / s, 32 GB / s und 38, 4 GB / s zwischen den CPUs. Um dies zu relativieren, bot der zuletzt verwendete Front-Side-Bus 1,6 GT / s oder 12,8 GB / s Plattformbandbreite. Bei der Einführung von Sandy Bridge hat Intel Uncore in System Agent umbenannt, Der Begriff Uncore wird jedoch in der aktuellen Dokumentation weiterhin verwendet. Mehr über QuickPath und den Uncore erfahren Sie in Teil 2.
3: Skalierbare Cache-Kohärenz
Jeder Kern hatte einen privaten Pfad zum L3-Cache. Jeder Pfad bestand aus tausend Drähten, und Sie können sich vorstellen, dass dies nicht gut skaliert, wenn Sie den Nanometer-Herstellungsprozess verringern und gleichzeitig die Kerne erhöhen möchten, die auf den Cache zugreifen möchten. Um skalieren zu können, hat die Sandy Bridge-Architektur den L3-Cache aus dem Uncore entfernt und die skalierbare Ring-on-Die-Verbindung eingeführt. Dies ermöglichte es Intel, den L3-Cache in gleichen Abschnitten zu partitionieren und zu verteilen. Dies bietet eine höhere Bandbreite und Assoziativität. Jedes Slice ist 2,5 MB groß und jedem Core ist ein Slice zugeordnet. Der Ring ermöglicht jedem Kern, auch auf jede andere Scheibe zuzugreifen. Unten abgebildet ist die Die-Konfiguration einer Low Core Count (LCC) Xeon-CPU der Broadwell-Mikroarchitektur (v4) (2016).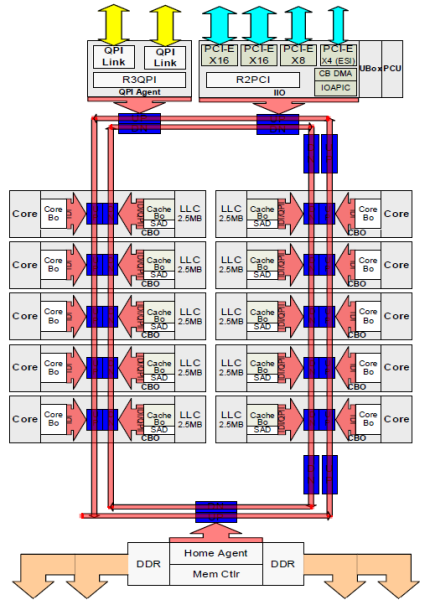
Diese Caching-Architektur erfordert ein Snooping-Protokoll, das sowohl den verteilten lokalen Cache als auch die anderen Prozessoren im System enthält, um die Cache-Kohärenz sicherzustellen. Mit dem Hinzufügen von mehr Kernen im System wächst die Menge an Snoop-Verkehr, da jeder Kern seinen eigenen stetigen Strom von Cache-Fehlern hat. Dies wirkt sich auf den Verbrauch der QPI-Links und der Caches der letzten Ebene aus und erfordert eine kontinuierliche Entwicklung der Snoop-Kohärenzprotokolle. In Teil 3 wird ein detaillierter Überblick über die Uncore-, skalierbare Ring-on-Die-Verbindung und die Bedeutung des Zwischenspeicherns von Snoop-Protokollen für die NUMA-Leistung gegeben.
Nicht verschachtelt aktiviert NUMA = SUMA
Der physische Speicher ist über das Motherboard verteilt, das System kann jedoch einen einzelnen Speicheradressraum bereitstellen, indem der Speicher zwischen den beiden NUMA-Knoten verschachtelt wird. Dies nennt man Node-Interleaving (Einstellung wird in Teil 2 behandelt). Wenn die Knotenverschachtelung aktiviert ist, wird das System zu einer ausreichend einheitlichen Speicherarchitektur (SUMA). Anstatt die Topologieinformationen und die Art der Prozessoren und des Speichers im System an das Betriebssystem weiterzuleiten, unterteilt das System den gesamten Speicherbereich in adressierbare 4-KB-Bereiche und ordnet sie von jedem Knoten aus in einer Round-Robin-Methode zu. Dies stellt eine verschachtelte Speicherstruktur bereit, bei der der Speicheradressraum über die Knoten verteilt ist. Wenn ESXi der virtuellen Maschine Arbeitsspeicher zuweist, wird physischer Arbeitsspeicher von zwei verschiedenen Knoten zugewiesen Wenn die physische CPU in Knoten 0 den Arbeitsspeicher von Knoten 1 abrufen muss, durchläuft der Arbeitsspeicher die QPI-Links.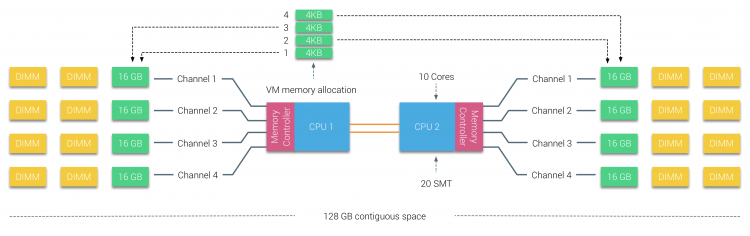
Das Interessante ist, dass das SUMA-System eine einheitliche Speicherzugriffszeit bietet. Nur nicht die optimalste und hängt stark von den Konfliktstufen in der QPI-Architektur ab. Der Intel Memory Latency Checker wurde verwendet, um die Unterschiede zwischen der NUMA- und der SUMA-Konfiguration auf demselben System zu demonstrieren.
Dieser Test misst die Leerlauflatenzen (in Nanosekunden) von jedem Socket zum anderen Socket im System. Die von Socket 0 gemeldete Latenz des Speicherknotens 0 ist ein lokaler Speicherzugriff, der Speicherzugriff von Socket 0 des Speicherknotens 1 ist ein Remotespeicherzugriff in dem als NUMA konfigurierten System.
| NUMA | Speicherknoten 0 | Speicherknoten 1 | – | SUMA | Speicherknoten 0 | Speicherknoten 1 |
| Sockel 0 | 75.7 | 132.0 | – | Buchse 0 | 105.5 | 106.4 |
| Sockel 1 | 131.9 | 75.8 | – | Sockel 1 | 106.0 | 104.6 |
Wie erwartet wird die Verschachtelung durch konstantes Durchlaufen der QPI-Links beeinflusst. Der Leerlaufspeichertest ist das beste Szenario, ein interessanterer Test misst geladene Latenzen. Es wäre eine schlechte Investition gewesen, wenn Ihre ESXi-Server im Leerlauf wären, daher können Sie davon ausgehen, dass ein ESXi-System Daten verarbeitet. Die Messung der geladenen Latenzen bietet einen besseren Einblick in die Leistung des Systems unter normaler Last. Während des Tests werden die Load Injection Delays automatisch alle 2 Sekunden geändert und sowohl die Bandbreite als auch die entsprechende Latenz auf diesem Niveau gemessen. Dieser Test verwendet 100% Leseverkehr.NUMA-Testergebnisse links, SUMA-Testergebnisse rechts.
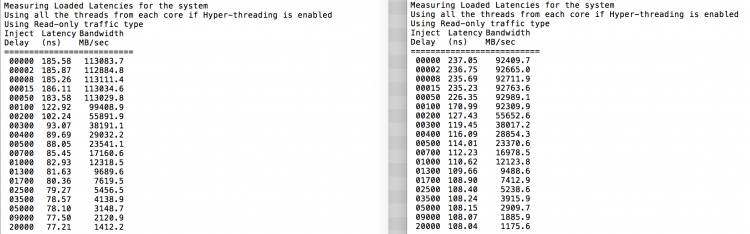
Die gemeldete Bandbreite für das SUMA-System ist niedriger, während eine höhere Latenz beibehalten wird als für das als NUMA konfigurierte System. Daher sollte der Fokus auf der Optimierung der VM-Größe liegen, um die NUMA-Eigenschaften des Systems zu nutzen.
Nehalem & Überblick über die Kernmikroarchitektur
Mit der Einführung der Nehalem-Mikroarchitektur im Jahr 2008 entfernte sich Intel von der Netburst-Architektur. Die Nehalem-Mikroarchitektur führte Intel-Kunden in NUMA ein. Im Laufe der Jahre führte Intel nach seinem berühmten Tick-Tock-Modell neue Mikroarchitekturen und Optimierungen ein. Mit jedem Tick findet eine Optimierung statt, schrumpft die Prozesstechnologie und mit jedem Tick wird eine neue Mikroarchitektur eingeführt. Obwohl Intel seit 2012 ein konsistentes Branding-Modell bietet, neigen die Leute zu Intel-Architektur-Codenamen, um die CPU-Tick- und Tock-Generationen zu diskutieren. Sogar die EVC-Baselines listen diese internen Intel-Codenamen auf, Sowohl Markennamen als auch Architektur-Codenamen werden in dieser Serie verwendet:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4 x ddr3-2133 | Tock | 22 nm |
| Broadwells | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4 x DDR3-2400 | Tick | 14 nm |
Als nächstes Teil 2: Systemarchitektur
Die NUMA Deep Dive-Serie 2016:
Teil 0: Einführung NUMA Deep Dive-Serie
Teil 1: Von UMA zu NUMA
Teil 2: Systemarchitektur
Teil 3: Cache-Kohärenz
Teil 4: Optimierung des lokalen Speichers
Teil 5: ESXi VMkernel NUMA-Konstrukte