Die stückweise Regression ist eine spezielle Art der linearen Regression, die auftritt, wenn eine einzelne Zeile nicht ausreicht, um einen Datensatz zu modellieren. Stückweise Regression bricht die Domäne in potenziell viele „Segmente“ und passt eine separate Linie durch jedes. In den folgenden Diagrammen ist beispielsweise eine einzelne Zeile nicht in der Lage, die Daten sowie eine stückweise Regression mit drei Zeilen zu modellieren:
In diesem Beitrag wird der Ansatz von Datadog zur Automatisierung der stückweisen Regression von Zeitreihendaten vorgestellt.
Stückweise Regression kann in verschiedenen Kontexten etwas anderes bedeuten, also nehmen wir uns eine Minute Zeit, um zu klären, was genau wir mit unserem stückweisen Regressionsalgorithmus erreichen wollen.
Automatische Haltepunkterkennung. In der klassischen Statistikliteratur wird bei der manuellen Regressionsanalyse häufig eine stückweise Regression vorgeschlagen, bei der es mit bloßem Auge offensichtlich ist, wo ein linearer Trend einem anderen weicht. In diesem Fall kann ein Mensch den Haltepunkt zwischen stückweisen Segmenten angeben, den Datensatz aufteilen und für jedes Segment unabhängig eine lineare Regression durchführen. In unseren Anwendungsfällen möchten wir Hunderte von Regressionen pro Sekunde durchführen, und es ist nicht möglich, dass ein Mensch alle Haltepunkte angibt. Stattdessen haben wir die Anforderung, dass unser stückweiser Regressionsalgorithmus seine eigenen Haltepunkte identifiziert.
Automatische Erkennung der Segmentanzahl. Wenn wir wüssten, dass ein Datensatz genau zwei Segmente hat, könnten wir leicht jedes der möglichen Segmentpaare betrachten. In der Praxis gibt es jedoch bei einer beliebigen Zeitreihe keinen Grund zu der Annahme, dass es mehr als ein Segment oder weniger als 3 oder 4 oder 5 geben muss. Unser Algorithmus muss eine angemessene Anzahl von Segmenten auswählen, ohne dass diese vom Benutzer angegeben werden.
Keine kontinuität anforderung. Einige Methoden für stückweise Regressionen erzeugen verbundene Segmente, wobei der Endpunkt jedes Segments der Startpunkt des nächsten Segments ist. Wir stellen keine solche Anforderung an unseren Algorithmus.
Herausforderungen
Die offensichtlichste Herausforderung bei der Implementierung einer stückweisen Regression mit automatisierter Haltepunkterkennung ist die große Größe des Lösungssuchraums; Eine Brute-Force-Suche aller möglichen Segmente ist unerschwinglich teuer. Die Anzahl der Möglichkeiten, wie eine Zeitreihe in Segmente unterteilt werden kann, ist exponentiell in der Länge der Zeitreihe. Während dynamische Programmierung verwendet werden kann, um diesen Suchraum viel effizienter als eine naive Brute-Force-Implementierung zu durchlaufen, ist es in der Praxis immer noch zu langsam. Eine gierige Heuristik wird benötigt, um große Bereiche des Suchraums schnell zu verwerfen.
Eine subtilere Herausforderung besteht darin, dass wir die Qualität einer Lösung mit einer anderen vergleichen müssen. Für unsere Version des Problems mit unbekannter Anzahl und Position von Segmenten müssen wir mögliche Lösungen mit einer unterschiedlichen Anzahl von Segmenten und unterschiedlichen Haltepunkten vergleichen. Wir versuchen, zwei konkurrierende Ziele auszugleichen:
- Minimieren Sie die Fehler. Das heißt, machen Sie die Regressionslinie jedes Segments nahe an den beobachteten Datenpunkten.
- Verwenden Sie die geringste Anzahl von Segmenten, die die Daten gut modellieren. Wir könnten immer null Fehler erhalten, indem wir ein einzelnes Segment für jeden Punkt (oder sogar ein Segment für jeweils zwei Punkte) erstellen. Wir würden nichts über die allgemeine Beziehung zwischen einem Zeitstempel und dem zugehörigen Metrikwert erfahren, und wir könnten das Ergebnis nicht einfach für die Interpolation oder Extrapolation verwenden.
Unsere Lösung
Wir verwenden den folgenden Greedy-Algorithmus für das stückweise Regressionsproblem:
- Führen Sie eine stückweise Regression mit n / 2 Segmenten durch, wobei n die Anzahl der Beobachtungen in der Zeitreihe ist. Die Regressionsgerade in jedem Segment wird mithilfe der OLS-Regression (Ordinary Least Squares) angepasst. Diese anfängliche stückweise Regression weist kaum Fehler auf, passt jedoch stark zum Datensatz.
- Iterativ, bis nur noch ein Segment vorhanden ist:
- Bewerten Sie für alle Paare benachbarter Segmente den Anstieg des Gesamtfehlers, der sich ergeben würde, wenn die beiden Segmente kombiniert würden, wobei ihre beiden Regressionslinien durch eine einzige Regressionslinie ersetzt würden.
- Füge das Segmentpaar zusammen, das zu der geringsten Fehlerzunahme führen würde.
- Wenn diese Zusammenführung unsere Stoppkriterien (unten definiert) erfüllt, sind wir möglicherweise zu weit gegangen und haben zwei Segmente zusammengeführt, die getrennt bleiben sollten. Wenn dies der Fall ist, merken Sie sich den Status der Segmente vor dem Zusammenführen dieser Iteration.
- Wenn keine Zusammenführung dazu führte, dass der Status der Segmente in (2c) oben gespeichert wurde, ist die beste Lösung ein großes Segment. Andernfalls ist der letzte Segmentstatus, der in (2c) gespeichert werden soll, die beste Lösung.
Stoppkriterien
Wir betrachten eine Zusammenführung als potenziellen Stopppunkt, wenn sie die Gesamtsumme der quadratischen Fehler um mehr erhöht als jede vorherige Zusammenführung. Um zu verhindern, dass in Fällen, in denen nur ein Segment vorhanden sein sollte, ein zu frühes Anhalten erfolgt, betrachten wir eine Zusammenführung nicht als potenziellen Haltepunkt, es sei denn, dies führt zu einem Anstieg des Gesamtfehlers, der weniger als 3% des Gesamtfehlers einer Regression beträgt mit einem Segment. (Die 3% sind eine willkürliche Schwelle, aber wir haben festgestellt, dass sie in der Praxis gut funktioniert.) Im Folgenden finden Sie einige Beispiele, um zu demonstrieren, warum dieses Stoppkriterium funktioniert.
Betrachten wir zunächst einen Datensatz, der durch Hinzufügen von normalverteiltem Rauschen zu Punkten entlang einer einzelnen Linie generiert wurde. Der Algorithmus passt nur ein einzelnes Segment korrekt durch diesen Datensatz.
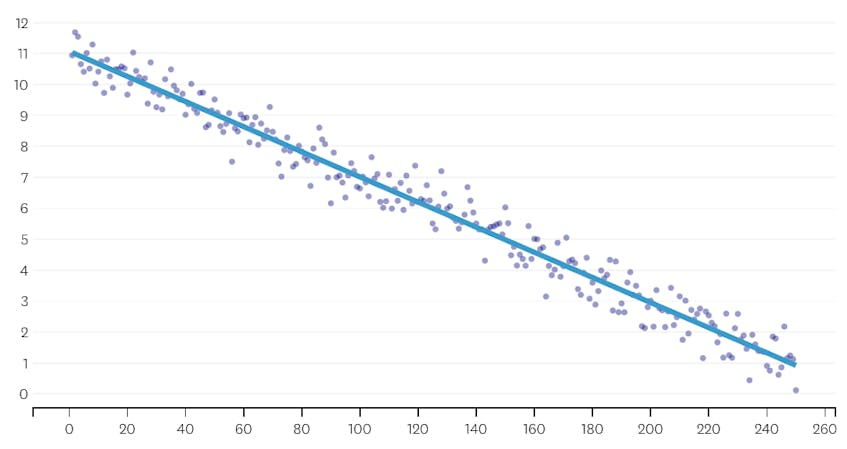
In diesem Fall erhöht keine Zusammenführung die Gesamtsumme der quadratischen Fehler um mehr als 3%. Daher wird keine Zusammenführung als angemessener Haltepunkt angesehen, und wir verwenden den Endzustand, nachdem alle Zusammenführungen ausgeführt wurden. In der folgenden Darstellung sehen wir, dass spätere Zusammenführungen tendenziell mehr Fehler verursachen als frühere (was sinnvoll ist, da sie jeweils mehr Punkte betreffen), aber die Zunahme des Fehlers nimmt nur allmählich zu, wenn mehr Segmente zusammengeführt werden.
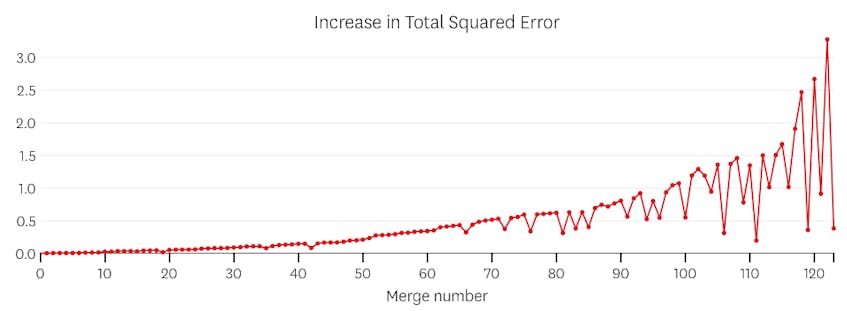
Zweitens schauen wir uns ein Beispiel an, in dem der Datensatz sieben verschiedene Segmente enthält.
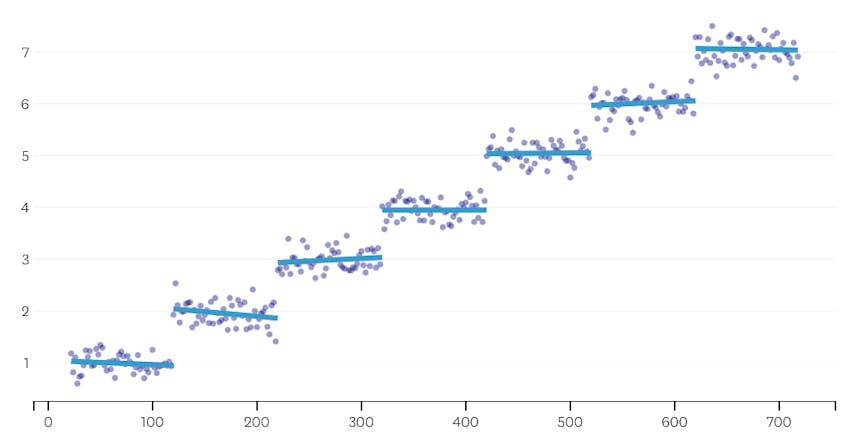
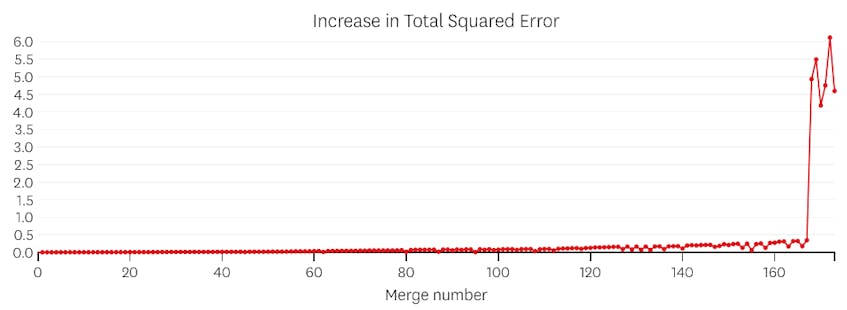
Wenn wir uns in diesem Fall die Darstellung der Fehler ansehen, die durch jede Zusammenführung verursacht wurden, sehen wir, dass die letzten sechs Zusammenführungen viel mehr Fehler verursacht haben als jede der vorherigen Zusammenführungen. Daher erinnerte sich unser Algorithmus an den Status der Segmente vor der 6. bis letzten Zusammenführung und verwendete dies als endgültige Lösung.
Der Code
Im Datadog / piecewise Github Repo finden Sie unsere Python-Implementierung des Algorithmus. Die Funktion piecewise() ist der Ort, an dem das schwere Heben stattfindet. Bei einem Datensatz werden die Position und die Regressionskoeffizienten für jedes der angepassten Segmente zurückgegeben.
Ebenfalls im Gist enthalten ist plot_data_with_regression() – eine Wrapper-Funktion für schnelles und einfaches Plotten. Ein kurzes Beispiel, wie dies verwendet werden könnte:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)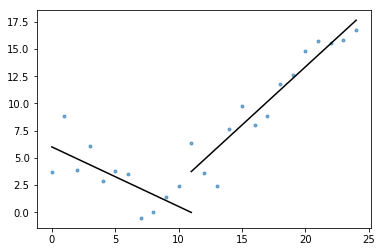
Während diese Implementierung die lineare OLS-Regression verwendet, kann dasselbe Framework angepasst werden, um verwandte Probleme zu lösen. Durch Ersetzen des quadratischen Fehlers durch absoluten Fehler oder absoluten Verlust kann die Regression robust gemacht werden. Oder eine Schrittfunktion kann angepasst werden, indem jedem Segment ein konstanter Wert zugewiesen wird, der dem Durchschnitt der Beobachtungen in seiner Domäne entspricht.