Das Hidden-Markov-Modell (HMM) ist ein statistisches Markov-Modell, bei dem angenommen wird, dass das zu modellierende System ein Markov-Prozess mit unbeobachteten (dh versteckten) Zuständen ist.
Hidden-Markov-Modelle sind besonders bekannt für ihre Anwendung im Reinforcement Learning und der zeitlichen Mustererkennung wie Sprache, Handschrift, Gestenerkennung, Part-of-Speech-Tagging, Partiturverfolgung, Teilentladungen und Bioinformatik.
Terminologie in HMM
bezieht sich der Begriff hidden auf den Markov-Prozess erster Ordnung hinter der Beobachtung. Beobachtung bezieht sich auf die Daten, die wir kennen und beobachten können. Der Markov-Prozess wird durch die Wechselwirkung zwischen „Regnerisch“ und „Sonnig“ im folgenden Diagramm gezeigt, und jeder dieser Zustände ist VERBORGEN.

BEOBACHTUNGEN sind bekannte Daten und beziehen sich im obigen Diagramm auf „Gehen“, „Einkaufen“ und „Reinigen“. Im Sinne des maschinellen Lernens ist Beobachtung unsere Trainingsdaten, und die Anzahl der verborgenen Zustände ist unser Hyper-Parameter für unser Modell. Die Bewertung des Modells wird später besprochen.

T = habe noch keine Beobachtung, N = 2, M = 3, Q = {„Rainy“, „Sunny“}, V = {„Walk“, „Shop“, „Clean“}
Zustandsübergangswahrscheinlichkeiten sind die Pfeile, die auf jeden versteckten Zustand zeigen. Beobachtungswahrscheinlichkeitsmatrix sind die blauen und roten Pfeile, die auf jede Beobachtung aus jedem verborgenen Zustand zeigen. Die Matrix ist zeilenstochastisch, dh die Zeilen addieren sich zu 1.


Die Matrix erklärt, wie hoch die Wahrscheinlichkeit ist, von einem Zustand in einen anderen oder von einem Zustand in eine Beobachtung zu wechseln.
Die Anfangszustandsverteilung bringt das Modell in Gang, indem sie mit einem versteckten Zustand beginnt.
Vollständiges Modell mit bekannten Zustandsübergangswahrscheinlichkeiten, Beobachtungswahrscheinlichkeitsmatrix und Anfangszustandsverteilung wird als markiert,
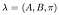
Wie können wir das obige Modell in Python erstellen?
Im obigen Fall sind die Emissionen diskret {„Gehen“, „Einkaufen“, „Reinigen“}. Für das obige Modell wird MultinomialHMM aus der hmmlearn-Bibliothek verwendet. GaussianHMM und GMMHMM sind weitere Modelle in der Bibliothek.
Was sind nun mit dem HMM einige Schlüsselprobleme zu lösen?
- Problem 1: Wie hoch ist die Wahrscheinlichkeit, dass Sequenz O auftritt, wenn ein bekanntes Modell vorliegt?
- Problem 2: Was ist bei einem bekannten Modell und einer bekannten Sequenz O die optimale versteckte Zustandssequenz? Dies wird nützlich sein, wenn wir wissen wollen, ob das Wetter „regnerisch“ oder „sonnig“ ist
- Problem 3, Gegebene Sequenz O und Anzahl der versteckten Zustände, was ist das optimale Modell, das die Wahrscheinlichkeit von O maximiert?
Problem 1 in Python
Die Wahrscheinlichkeit, dass die erste Beobachtung „Walk“ ist, entspricht der Multiplikation der Anfangszustandsverteilung und der Emissionswahrscheinlichkeitsmatrix. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). Die Protokolldatei wird vom Aufruf bereitgestellt.Ergebnis.
Problem 2 in Python

Angesichts des bekannten Modells und der Beobachtung {„Shop“, „Clean“, „Walk“} war das Wetter höchstwahrscheinlich {„Rainy“, „Rainy“, „Sunny“} mit ~ 1,5% Wahrscheinlichkeit.
Angesichts des bekannten Modells und der Beobachtung {„Sauber“, „Sauber“, „Sauber“} war das Wetter höchstwahrscheinlich {„Regnerisch“, „Regnerisch“, „Regnerisch“} mit ~ 3,6% Wahrscheinlichkeit.
Intuitiv wird das Wetter beim „Gehen“ höchstwahrscheinlich nicht „regnerisch“ sein.
Problem 3 in Python
Spracherkennung mit Audiodatei: Sagen Sie diese Wörter voraus

Amplitude kann als BEOBACHTUNG für HMM verwendet werden, aber Feature Engineering wird uns mehr Leistung geben.

Funktion stft und peakfind erzeugt Funktion für Audiosignal.
Das obige Beispiel wurde von hier übernommen . Kyle Kastner hat eine HMM-Klasse erstellt, die 3D-Arrays aufnimmt, ich verwende hmmlearn, das nur 2D-Arrays zulässt. Aus diesem Grund reduziere ich die von Kyle Kastner generierten Funktionen als X_test .mittelwert (Achse = 2).
Diese Modellierung durchzugehen, brauchte viel Zeit, um sie zu verstehen. Ich hatte den Eindruck, dass die Zielvariable die Beobachtung sein muss. Dies gilt für Zeitreihen. Die Klassifizierung erfolgt, indem Sie HMM für jede Klasse erstellen und die Ausgabe vergleichen, indem Sie das logprob für Ihre Eingabe berechnen.
Mathematische Lösung zu Problem 1: Vorwärtsalgorithmus

Alpha-Pass ist die Wahrscheinlichkeit der Beobachtung und Zustandssequenz gegeben Modell.
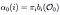
Alpha-Pass zum Zeitpunkt (t) = 0, Anfangszustandsverteilung zu i und von dort zur ersten Beobachtung O0.
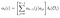
Alpha-Pass zum Zeitpunkt (t) = t, Summe des letzten Alpha-Passes zu jedem versteckten Zustand multipliziert mit Emission zu Ot.
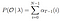
Mathematische Lösung für Problem 2: Rückwärts Algorithmus


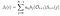

Gegebenes Modell und Beobachtung, Wahrscheinlichkeit, zum Zeitpunkt t im Zustand qi zu sein.
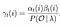
Mathematische Lösung für Problem 3: Vorwärts-Rückwärts-Algorithmus


Wahrscheinlichkeit des Zustands qi zu qj zum Zeitpunkt t mit gegebenem Modell und gegebener Beobachtung
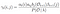
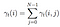
Summe aller Übergangswahrscheinlichkeiten von i nach j.
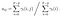
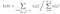
Transitions- und Emissionswahrscheinlichkeitsmatrix werden mit Di-Gamma geschätzt.
Iterieren, wenn die Wahrscheinlichkeit für P(O|Modell) zunimmt