El Modelo de Markov oculto (HMM) es un modelo estadístico de Markov en el que se asume que el sistema que se está modelando es un proceso de Markov con estados no observados (es decir, ocultos).
Los modelos de Markov ocultos son especialmente conocidos por su aplicación en el aprendizaje por refuerzo y el reconocimiento de patrones temporales, como el habla, la escritura a mano, el reconocimiento de gestos, el etiquetado de parte del habla, el seguimiento de partituras musicales, las descargas parciales y la bioinformática.
Terminología en HMM
El término oculto se refiere al proceso de Markov de primer orden detrás de la observación. La observación se refiere a los datos que conocemos y podemos observar. El proceso de Markov se muestra por la interacción entre «Lluvioso» y «Soleado» en el diagrama de abajo y cada uno de estos son ESTADOS OCULTOS.

las OBSERVACIONES son datos conocidos y se refiere a «Caminar», «Tienda», y «Limpio» en el diagrama de arriba. En el sentido del aprendizaje automático, la observación es nuestros datos de entrenamiento, y el número de estados ocultos es nuestro hiperparámetro para nuestro modelo. La evaluación del modelo se discutirá más adelante.

T = no tiene observación todavía, N = 2, M = 3, Q = {«Lluvioso», «Soleado»}, V = {«Caminar», «Comprar», «Limpiar»}
Las probabilidades de transición de estado son las flechas que apuntan a cada estado oculto. La matriz de probabilidad de observación son las flechas azules y rojas que apuntan a cada observación de cada estado oculto. La matriz es estocástica de filas, lo que significa que las filas suman 1.


La matriz se explica lo que es la probabilidad de ir de un estado a otro, o van de un estado a una observación.
La distribución de estado inicial pone en marcha el modelo comenzando en un estado oculto.
El modelo completo con probabilidades de transición de estado conocidas, matriz de probabilidad de observación y distribución de estado inicial se marca como,
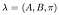
¿Cómo podemos construir el modelo anterior en Python?
En el caso anterior, las emisiones son discretas {«Caminar», «Comprar», «Limpiar»}. MultinomialHMM de la biblioteca hmmlearn se utiliza para el modelo anterior. GaussianHMM y GMMHMM son otros modelos de la biblioteca.
Ahora con el HMM, ¿cuáles son algunos problemas clave a resolver?
- Problema 1, Dado un modelo conocido ¿cuál es la probabilidad de que ocurra la secuencia O?
- Problema 2, Dado un modelo y secuencia conocidos O, ¿cuál es la secuencia de estado oculto óptima? Esto será útil si queremos saber si el clima es «Lluvioso» o «Soleado»
- Problema 3, Dada la secuencia O y el número de estados ocultos, ¿cuál es el modelo óptimo que maximiza la probabilidad de O?
Problema 1 en Python
La probabilidad de que la primera observación sea «A pie» es igual a la multiplicación de la matriz de distribución de estado inicial y probabilidad de emisión. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). La probabilidad de registro se proporciona desde la llamada .puntaje.
Problema 2 en Python

Dado que se conoce el modelo y la observación {«Tienda», «Limpio», «Caminar»}, el clima era más probable {«Lluvioso», «Lluvia», «Sunny»} con ~1.5% de probabilidad.
Dado el modelo conocido y la observación {«Limpio», «Limpio», «Limpio»}, el clima era más probable {«Lluvioso», «Lluvioso», «Lluvioso»} con ~3,6% de probabilidad.
Intuitivamente, cuando se produce «Caminar», el clima probablemente no será»lluvioso».
Problema 3 en Python
Reconocimiento de voz con Archivo de audio: Predecir estas palabras

La amplitud se puede usar como OBSERVACIÓN para HMM, pero la ingeniería de características nos dará más rendimiento.

Función de la stft y peakfind genera característica de la señal de audio.
El ejemplo anterior fue tomado de aquí. Kyle Kastner construyó la clase HMM que toma matrices 3d, estoy usando hmmlearn que solo permite matrices 2d. Es por eso que estoy reduciendo las características generadas por Kyle Kastner como X_test.media(eje=2).
Pasar por este modelado tomó mucho tiempo para entenderlo. Tenía la impresión de que la variable objetivo debía ser la observación. Esto es cierto para las series temporales. La clasificación se realiza construyendo HMM para cada clase y compara la salida calculando el logprob para tu entrada.
Solución matemática al Problema 1: Algoritmo de avance

El paso alfa es la probabilidad de OBSERVACIÓN y secuencia de ESTADOS del modelo dado.
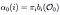
Paso alfa en el tiempo (t) = 0, distribución de estado inicial a i y de ahí a la primera observación O0.
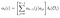
Paso alfa en el tiempo ( t) = t, suma del último paso alfa a cada estado oculto multiplicado por la emisión a Ot.
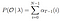
Solución Matemática del Problema 2: Atrás Algoritmo


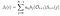

Dado el modelo y la observación, la probabilidad de estar en el estado de qi en el tiempo t.
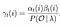
Solución Matemática al Problema 3: Adelante-Atrás Algoritmo


Probabilidad de que desde el estado qi qj en el tiempo t con determinado modelo y la observación
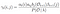
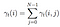
Suma de todos los probabilidad de transición de i a j.
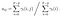
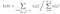
la Transición de emisión y la probabilidad de la matriz se calcula con di-gamma.
Iterar si la probabilidad de P (O / modelo) aumenta