El acceso a memoria no uniforme (NUMA) es una arquitectura de memoria compartida utilizada en los sistemas multiprocesamiento de hoy en día. A cada CPU se le asigna su propia memoria local y puede acceder a la memoria de otras CPU del sistema. El acceso a memoria local proporciona un rendimiento de ancho de banda de baja latencia y alto. Mientras que el acceso a la memoria propiedad de la otra CPU tiene una latencia más alta y un rendimiento de ancho de banda más bajo. Las aplicaciones y los sistemas operativos modernos, como ESXi, admiten NUMA de forma predeterminada, pero para proporcionar el mejor rendimiento, la configuración de la máquina virtual debe realizarse teniendo en cuenta la arquitectura NUMA. Si el diseño es incorrecto, se produce un comportamiento intrascendente o una degradación general del rendimiento para esa máquina virtual en particular o, en el peor de los casos, para todas las máquinas virtuales que se ejecutan en ese host ESXi.
Esta serie tiene como objetivo proporcionar información sobre la arquitectura de la CPU, el subsistema de memoria y el programador de CPU y memoria ESXi. Lo que le permite crear una plataforma de alto rendimiento que sienta las bases para servicios más altos y mayores ratios de consolidación. Antes de llegar a las arquitecturas informáticas modernas, es útil revisar el historial de las arquitecturas de multiprocesadores de memoria compartida para comprender por qué estamos utilizando sistemas NUMA hoy en día.
- La evolución de la arquitectura de multiprocesadores de memoria compartida en las últimas décadas
- Introducción de protocolos snoop de almacenamiento en caché
- Arquitectura de acceso a memoria uniforme
- Arquitectura de acceso a memoria no uniforme
- 1: Organización de acceso a memoria no uniforme
- 2: Interconexión punto a punto
- 3: Coherencia de caché escalable
- NUMA = SUMA no entrelazada habilitada
- Nehalem & Descripción general de la microarquitectura del núcleo
La evolución de la arquitectura de multiprocesadores de memoria compartida en las últimas décadas
Parece que una arquitectura llamada Acceso Uniforme a la memoria sería una mejor opción al diseñar una plataforma consistente de baja latencia y alto ancho de banda. Sin embargo, las arquitecturas de sistema modernas restringirán que sea verdaderamente uniforme. Para entender la razón detrás de esto, necesitamos retroceder en la historia para identificar los impulsores clave de la computación paralela.
Con la introducción de las bases de datos relacionales a principios de los años setenta, la necesidad de sistemas que pudieran dar servicio a múltiples operaciones de usuario simultáneas y generación de datos excesiva se convirtió en una tendencia generalizada. A pesar de la impresionante tasa de rendimiento de un procesador, los sistemas multiprocesador estaban mejor equipados para manejar esta carga de trabajo. Con el fin de proporcionar un sistema rentable, el espacio de direcciones de memoria compartida se convirtió en el foco de la investigación. Al principio, se defendieron los sistemas que usaban un interruptor de barra cruzada, sin embargo, con esta complejidad de diseño escalada junto con el aumento de procesadores, lo que hizo que el sistema basado en bus fuera más atractivo. A los procesadores de un sistema de bus se les permite acceder a todo el espacio de memoria mediante el envío de solicitudes en el bus, una forma muy rentable de utilizar la memoria disponible de la manera más óptima posible.
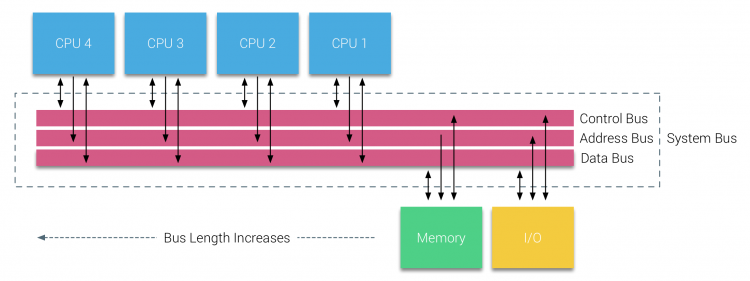
Sin embargo, los sistemas basados en bus tienen sus propios problemas de escalabilidad. El problema principal es la cantidad limitada de ancho de banda, esto restringe el número de procesadores que el bus puede acomodar. Agregar CPU al sistema introduce dos áreas principales de preocupación:
- El ancho de banda disponible por nodo disminuye a medida que se agrega cada CPU.
- La longitud del bus aumenta al agregar más procesadores, lo que aumenta la latencia.
El crecimiento del rendimiento de la CPU y, específicamente, la brecha de velocidad entre el procesador y el rendimiento de la memoria fue, y en realidad sigue siendo, devastador para los multiprocesadores. Dado que se esperaba que la brecha de memoria entre el procesador y la memoria aumentara, se invirtió mucho esfuerzo en el desarrollo de estrategias efectivas para administrar los sistemas de memoria. Una de estas estrategias fue agregar caché de memoria, lo que introdujo una multitud de desafíos. Resolver estos desafíos sigue siendo el objetivo principal de hoy en día para los equipos de diseño de CPU, se realiza una gran cantidad de investigación sobre estructuras de almacenamiento en caché y algoritmos sofisticados para evitar errores de caché.
Introducción de protocolos snoop de almacenamiento en caché
Adjuntar una caché a cada CPU aumenta el rendimiento de muchas maneras. Acercar la memoria a la CPU reduce el tiempo promedio de acceso a la memoria y, al mismo tiempo, reduce la carga de ancho de banda en el bus de memoria. El desafío de agregar caché a cada CPU en una arquitectura de memoria compartida es que permite que existan varias copias de un bloque de memoria. Esto se denomina problema de coherencia de caché. Para resolver esto, se inventaron protocolos snoop de almacenamiento en caché que intentaban crear un modelo que proporcionara los datos correctos sin intentar consumir todo el ancho de banda del bus. El protocolo más popular, write invalidate, borra todas las demás copias de datos antes de escribir la caché local. Cualquier lectura posterior de estos datos por parte de otros procesadores detectará una falta de caché en su caché local y se atenderá desde la caché de otra CPU que contenga los datos modificados más recientemente. Este modelo ahorró mucho ancho de banda de bus y permitió que surgieran sistemas de Acceso a Memoria Uniformes a principios de la década de 1990. Los protocolos modernos de coherencia de caché se cubren con más detalle en la parte 3.
Arquitectura de acceso a memoria uniforme
Los procesadores de multiprocesadores basados en bus que experimentan el mismo tiempo de acceso uniforme a cualquier módulo de memoria en el sistema a menudo se conocen como sistemas de Acceso a Memoria Uniforme (UMA) o Multiprocesadores simétricos (SMPs).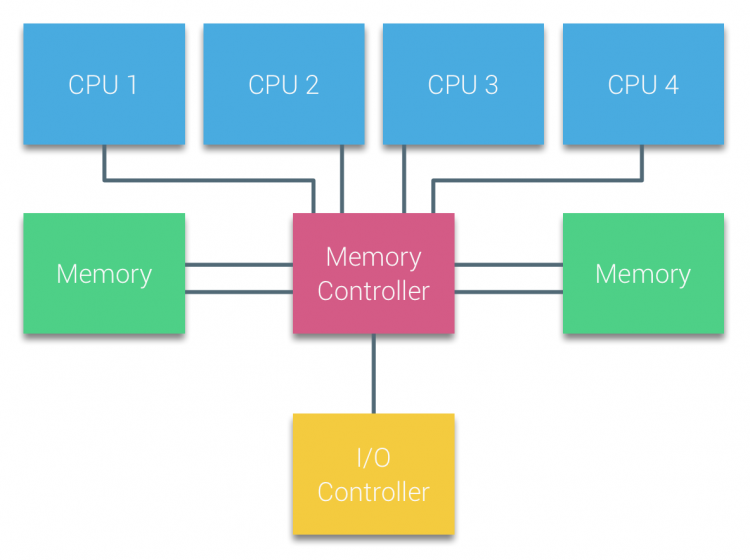
Con los sistemas UMA, las CPU se conectan a través de un bus del sistema (Bus Frontal) al puente Norte. El Puente Norte contiene el controlador de memoria y todas las comunicaciones desde y hacia la memoria deben pasar a través del Puente Norte. El controlador de E/S, responsable de administrar E/S a todos los dispositivos, está conectado al Puente Norte. Por lo tanto, cada E/S tiene que pasar por el puente Norte para llegar a la CPU.
Se utilizan múltiples buses y canales de memoria para duplicar el ancho de banda disponible y reducir el cuello de botella del puente Norte. Para aumentar aún más el ancho de banda de la memoria, algunos sistemas conectaron controladores de memoria externos al puente Norte, mejorando el ancho de banda y el soporte de más memoria. Sin embargo, debido al ancho de banda interno del Puente Norte y la naturaleza de transmisión de los primeros protocolos de caché de snoopy, se consideró que UMA tenía una escalabilidad limitada. Con el uso actual de dispositivos flash de alta velocidad, que empujan cientos de miles de E / s por segundo, tenían toda la razón en que esta arquitectura no escalaría para cargas de trabajo futuras.
Arquitectura de acceso a memoria no uniforme
Para mejorar la escalabilidad y el rendimiento, se realizan tres cambios críticos en la arquitectura de multiprocesadores de memoria compartida;
- Organización de acceso a memoria no uniforme
- Topología de interconexión punto a punto
- Soluciones escalables de coherencia de caché
1: Organización de acceso a memoria no uniforme
NUMA se aleja de un conjunto centralizado de memoria e introduce propiedades topológicas. Al clasificar las bases de ubicación de la memoria en función de la longitud de la ruta de la señal desde el procesador hasta la memoria, se pueden evitar cuellos de botella de latencia y ancho de banda. Esto se hace rediseñando todo el sistema de procesador y chipset. Las arquitecturas NUMA ganaron popularidad a finales de los años 90 cuando se utilizó en supercomputadoras SGI como el Cray Origin 2000. NUMA ayudó a identificar la ubicación de la memoria, en este caso de estos sistemas, tuvieron que preguntarse qué región de memoria en qué chasis se encontraban los bits de memoria.
En la primera mitad de la década del milenio, AMD llevó a NUMA al panorama empresarial donde los sistemas UMA reinaban por encima de todo. En 2003 se introdujo la familia AMD Opteron, con controladores de memoria integrados con cada CPU que posee bancos de memoria designados. Cada CPU tiene ahora su propio espacio de direcciones de memoria. Un sistema operativo optimizado para NUMA, como ESXi, permite que la carga de trabajo consuma memoria de ambos espacios de direcciones de memoria al tiempo que optimiza el acceso a la memoria local. Usemos un ejemplo de un sistema de dos CPU para aclarar la distinción entre el acceso a la memoria local y remota dentro de un solo sistema.
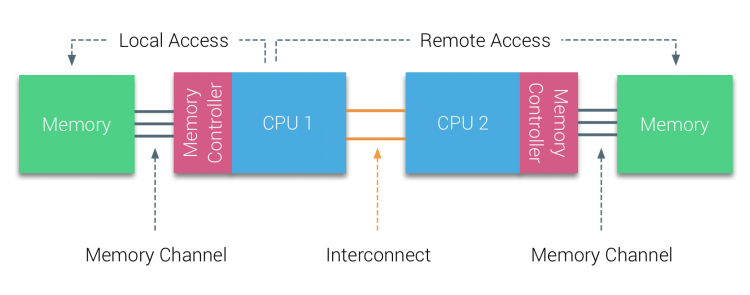
La memoria conectada al controlador de memoria de la CPU1 se considera memoria local. La memoria conectada a otro socket de CPU (CPU2) se considera externa o remota para la CPU1. El acceso a memoria remota tiene una sobrecarga de latencia adicional al acceso a memoria local, ya que tiene que atravesar una interconexión (enlace punto a punto) y conectarse al controlador de memoria remoto. Como resultado de las diferentes ubicaciones de memoria, este sistema experimenta un tiempo de acceso a la memoria «no uniforme».
2: Interconexión punto a punto
AMD introdujo su hipertransporte de conexión punto a punto con la microarquitectura AMD Opteron. Intel se alejó de su arquitectura de bus independiente dual en 2007 al introducir la arquitectura QuickPath en el diseño de su familia de procesadores Nehalem.
La arquitectura Nehalem fue un cambio de diseño significativo dentro de la microarquitectura Intel y se considera la primera generación verdadera de la serie Intel Core. La arquitectura Broadwell actual es la 4a generación de la marca Intel Core (Intel Xeon E5 v4), el último párrafo contiene más información sobre las generaciones de microarquitectura. Dentro de la arquitectura QuickPath, los controladores de memoria se trasladaron a la CPU e introdujeron la interconexión punto a punto (QPI) de QuickPath como enlaces de datos entre las CPU del sistema.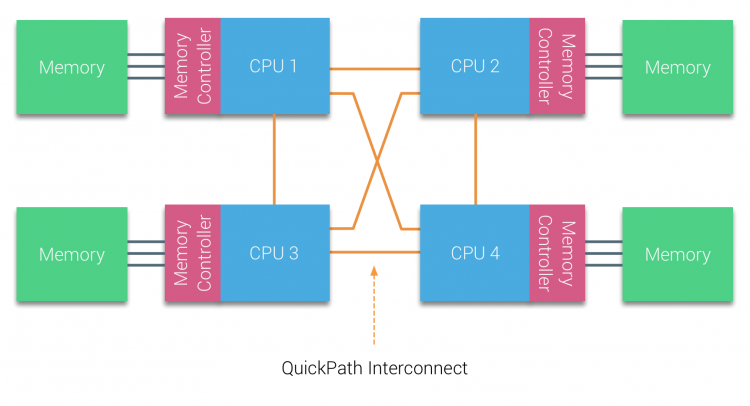
La microarquitectura Nehalem no solo reemplazó el bus frontal heredado, sino que reorganizó todo el subsistema en un diseño modular para CPU de servidor. Este diseño modular se introdujo como el «Uncore» y crea una biblioteca de bloques de construcción para el almacenamiento en caché y las velocidades de interconexión. La eliminación del bus frontal mejora los problemas de escalabilidad del ancho de banda, pero la comunicación intra e interprocesador debe resolverse cuando se trata de enormes cantidades de capacidad de memoria y ancho de banda. Tanto el controlador de memoria integrado como las interconexiones QuickPath forman parte del Uncore y son Registros Específicos del Modelo (MSR) ). Se conectan a un MSR que proporciona la comunicación intra e interprocesador. La modularidad del Uncore también permite a Intel ofrecer diferentes velocidades de QPI, en el momento de escribir la microarquitectura Intel Broadwell-EP (2016) ofrece 6,4 Giga-transferencias por segundo (GT/s), 8,0 GT/s y 9,6 GT/s. Respectivamente, proporcionando un ancho de banda máximo teórico de 25,6 GB/s, 32 GB/s y 38,4 GB/s entre las CPU. Para poner esto en perspectiva, el último bus frontal utilizado proporcionó 1,6 GT/s o 12,8 GB/s de ancho de banda de la plataforma. Al introducir Sandy Bridge Intel renombrado Uncore en System Agent, sin embargo, el término Uncore todavía se usa en la documentación actual. Puede encontrar más información sobre QuickPath y el Uncore en la parte 2.
3: Coherencia de caché escalable
Cada núcleo tenía una ruta privada a la caché L3. Cada ruta consistía en mil cables y puede imaginar que esto no se escala bien si desea disminuir el proceso de fabricación de nanómetros al tiempo que aumenta los núcleos que desean acceder a la caché. Para poder escalar, la arquitectura de Sandy Bridge movió la caché L3 fuera del Núcleo e introdujo la interconexión escalable de anillo en matriz. Esto permitió que Intel particionara y distribuyera la caché L3 en segmentos iguales. Esto proporciona un mayor ancho de banda y asociatividad. Cada segmento es de 2,5 MB y un segmento está asociado a cada núcleo. El anillo permite que cada núcleo acceda a cada otra rebanada también. En la imagen siguiente se muestra la configuración del troquel de una CPU Xeon de Bajo Recuento de núcleos (LCC) de la Microarquitectura de Broadwell (v4) (2016).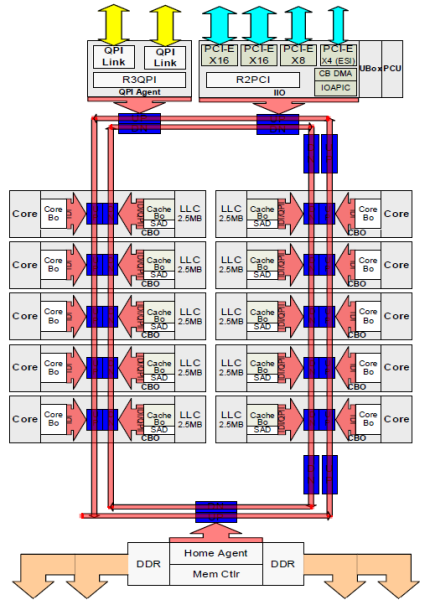
Esta arquitectura de almacenamiento en caché requiere un protocolo de espionaje que incorpore tanto la caché local distribuida como los demás procesadores del sistema para garantizar la coherencia de la caché. Con la adición de más núcleos en el sistema, la cantidad de tráfico de snoop crece, ya que cada núcleo tiene su propio flujo constante de errores de caché. Esto afecta el consumo de los enlaces QPI y las cachés de último nivel, lo que requiere un desarrollo continuo en los protocolos de coherencia de snoop. En la parte 3 se incluirá una vista en profundidad de la interconexión de anillo en matriz sin núcleo y escalable y la importancia del almacenamiento en caché de los protocolos snoop en el rendimiento de NUMA.
NUMA = SUMA no entrelazada habilitada
La memoria física se distribuye a través de la placa base, sin embargo, el sistema puede proporcionar un único espacio de direcciones de memoria intercalando la memoria entre los dos nodos NUMA. Esto se denomina entrelazado de nodos (el ajuste se trata en la parte 2). Cuando se habilita el entrelazado de nodos, el sistema se convierte en una Arquitectura de Memoria Suficientemente Uniforme (SUMA). En lugar de transmitir la información de la topología y la naturaleza de los procesadores y la memoria del sistema al sistema operativo, el sistema descompone todo el rango de memoria en regiones direccionables de 4 KB y las mapea de forma conjunta desde cada nodo. Esto proporciona una estructura de memoria’ intercalada ‘ donde el espacio de direcciones de memoria se distribuye a través de los nodos. Cuando ESXi asigna memoria a una máquina virtual, asigna memoria física ubicada en dos nodos diferentes cuando la CPU física ubicada en el nodo 0 necesita recuperar la memoria del nodo 1, la memoria recorrerá los enlaces de QPI.
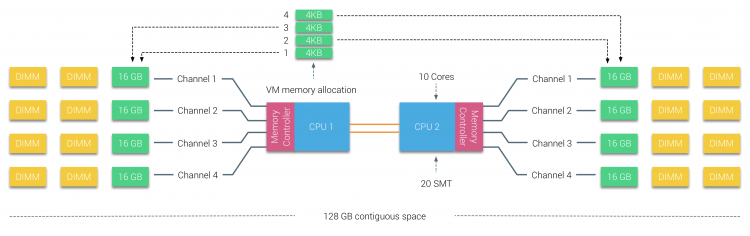
Lo interesante es que el sistema SUMA proporciona un tiempo de acceso a la memoria uniforme. Solo que no es el más óptimo y depende en gran medida de los niveles de contención en la arquitectura QPI. El comprobador de latencia de memoria Intel se utilizó para demostrar las diferencias entre la configuración de NUMA y SUMA en el mismo sistema.
Esta prueba mide las latencias inactivas (en nanosegundos) de cada toma a la otra toma del sistema. La latencia reportada del nodo de memoria 0 por el Socket 0 es el acceso a la memoria local, el acceso a la memoria desde el socket 0 del nodo de memoria 1 es el acceso a la memoria remota en el sistema configurado como NUMA.
| NUMA | Nodo de Memoria 0 | Nodo de Memoria 1 | – | SUMA | Nodo de Memoria 0 | Nodo de Memoria 1 |
| Zócalo 0 | 75.7 | 132.0 | – | Socket 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
Como se espera, el entrelazado se ve afectado por el recorrido constante de los enlaces QPI. La prueba de memoria inactiva es el mejor de los casos, una prueba más interesante es medir las latencias cargadas. Habría sido una mala inversión si sus servidores ESXi estuvieran en ralentí, por lo que puede suponer que un sistema ESXi está procesando datos. La medición de latencias cargadas proporciona una mejor visión de cómo funcionará el sistema con carga normal. Durante la prueba, los retrasos de inyección de carga se cambian automáticamente cada 2 segundos y tanto el ancho de banda como la latencia correspondiente se miden en ese nivel. Esta prueba utiliza 100% de tráfico de lectura.Resultados de la prueba NUMA a la izquierda, resultados de la prueba SUMA a la derecha.
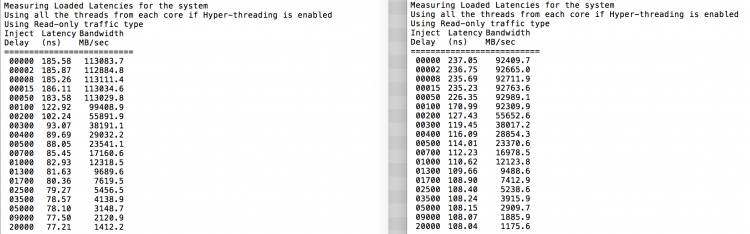
El ancho de banda reportado para el sistema SUMA es más bajo mientras se mantiene una latencia más alta que el sistema configurado como NUMA. Por lo tanto, el enfoque debe centrarse en optimizar el tamaño de la máquina virtual para aprovechar las características NUMA del sistema.
Nehalem & Descripción general de la microarquitectura del núcleo
Con la introducción de la microarquitectura de Nehalem en 2008, Intel se alejó de la arquitectura Netburst. La microarquitectura de Nehalem introdujo a los clientes de Intel en NUMA. A lo largo de los años, Intel introdujo nuevas microarquitecturas y optimizaciones, de acuerdo con su famoso modelo Tick-Tock. Con cada Tick, se lleva a cabo la optimización, reduciendo la tecnología de proceso y con cada Toque se introduce una nueva microarquitectura. A pesar de que Intel proporciona un modelo de marca consistente desde 2012, la gente tiende a usar nombres en código de la arquitectura Intel para hablar de las generaciones de tick y tock de la CPU. Incluso las líneas de base de EVC enumeran estos nombres en clave internos de Intel, tanto los nombres de marca como los nombres en clave de arquitectura se utilizarán a lo largo de esta serie:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDdr3-2133 | Tock | 22nm |
| Broadwell | E5 – 26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDdr3-2400 | Tick | 14 nm |
A continuación, Parte 2: Arquitectura del sistema
La Serie NUMA Deep Dive de 2016:
Parte 0: Introducción a la Serie NUMA Deep Dive
Parte 1: De UMA a NUMA
Parte 2: Arquitectura del sistema
Parte 3: Coherencia de caché
Parte 4: Optimización de la memoria Local
Parte 5: Construcciones ESXi VMkernel NUMA