La regresión por partes es un tipo especial de regresión lineal que surge cuando una sola línea no es suficiente para modelar un conjunto de datos. La regresión por partes rompe el dominio en potencialmente muchos» segmentos » y se ajusta a una línea separada a través de cada uno. Por ejemplo, en los gráficos a continuación, una sola línea no es capaz de modelar los datos, así como una regresión por partes con tres líneas:
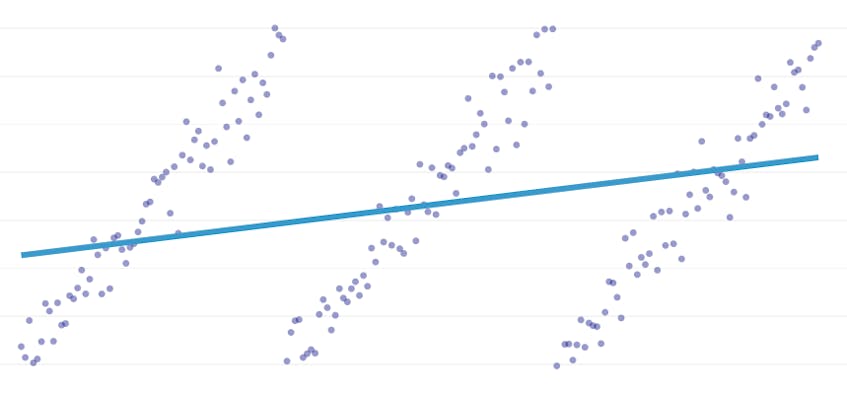
Este post presenta el enfoque de Datadog para automatizar la regresión por partes en datos de series temporales.
Objetivos
La regresión por partes puede significar cosas ligeramente diferentes en contextos diferentes, así que tomemos un minuto para aclarar qué es exactamente lo que estamos tratando de lograr con nuestro algoritmo de regresión por partes.
Detección automática de puntos de interrupción. En la literatura estadística clásica, la regresión por partes a menudo se sugiere durante el trabajo de análisis de regresión manual, donde es obvio a simple vista donde una tendencia lineal da paso a otra. En ese caso, un humano puede especificar el punto de interrupción entre segmentos por partes, dividir el conjunto de datos y realizar una regresión lineal en cada segmento de forma independiente. En nuestros casos de uso, queremos hacer cientos de regresiones por segundo, y no es factible que un humano especifique todos los puntos de interrupción. En su lugar, tenemos el requisito de que nuestro algoritmo de regresión por partes identifique sus propios puntos de interrupción.
Detección automática de recuento de segmentos. Si supiéramos que un conjunto de datos tiene exactamente dos segmentos, podríamos mirar fácilmente cada uno de los posibles pares de segmentos. Sin embargo, en la práctica, cuando se da una serie temporal arbitraria, no hay razón para creer que debe haber más de un segmento o menos de 3, 4 o 5. Nuestro algoritmo debe elegir un número apropiado de segmentos sin que sea especificado por el usuario.
Sin necesidad de continuidad. Algunos métodos para regresiones por partes generan segmentos conectados, donde el punto final de cada segmento es el punto de inicio del siguiente segmento. No imponemos tal requisito a nuestro algoritmo.
Desafíos
El desafío más obvio para implementar una regresión por partes con detección automática de puntos de interrupción es el gran tamaño del espacio de búsqueda de la solución; una búsqueda de fuerza bruta de todos los segmentos posibles es prohibitivamente costosa. El número de formas en que una serie temporal se puede dividir en segmentos es exponencial en la longitud de la serie temporal. Si bien la programación dinámica se puede usar para recorrer este espacio de búsqueda de manera mucho más eficiente que una implementación ingenua de fuerza bruta, en la práctica sigue siendo demasiado lenta. Se necesitará una heurística codiciosa para descartar rápidamente grandes áreas del espacio de búsqueda.
Un desafío más sutil es que necesitamos alguna forma de comparar la calidad de una solución con otra. Para nuestra versión del problema, con números y ubicaciones de segmentos desconocidos, necesitamos comparar soluciones potenciales con diferentes números de segmentos y diferentes puntos de interrupción. Nos encontramos tratando de equilibrar dos objetivos en competencia:
- Minimice los errores. Es decir, haga que la línea de regresión de cada segmento se acerque a los puntos de datos observados.
- Utilice el menor número de segmentos que modele bien los datos. Siempre podríamos obtener cero errores creando un solo segmento para cada punto (o incluso un segmento por cada dos puntos). Sin embargo, eso frustraría el objetivo de hacer una regresión; no aprenderíamos nada sobre la relación general entre una marca de tiempo y su valor métrico asociado, y no podríamos usar fácilmente el resultado para interpolación o extrapolación.
Nuestra solución
Utilizamos el siguiente algoritmo codicioso para el problema de regresión por partes:
- Haga una regresión por partes con n / 2 segmentos, donde n es el número de observaciones en la serie temporal. La línea de regresión en cada segmento se ajusta mediante regresión de mínimos cuadrados ordinarios (OLS). Esta regresión inicial por partes no tendrá casi ningún error, pero superará gravemente el conjunto de datos.
- Iterativamente, hasta que solo haya un segmento:
- Para todos los pares de segmentos vecinos, evalúe el aumento en el error total que resultaría si los dos segmentos se combinaran, reemplazando sus dos líneas de regresión por una sola línea de regresión.
- Fusionar el par de segmentos que resultaría en el menor aumento de error.
- Si realizar esta fusión cumple con nuestros criterios de detención (definidos a continuación), es posible que hayamos ido demasiado lejos, fusionando dos segmentos que deberían permanecer separados. Si este es el caso, recuerde el estado de los segmentos de antes de la fusión de esta iteración.
- Si ninguna combinación resultó en recordar el estado de los segmentos en (2c) anterior, entonces la mejor solución es un segmento grande. De lo contrario, el último estado de segmento en el que se recordará (2c) es la mejor solución.
Criterios de detención
Consideramos que una fusión es un punto de detención potencial si aumenta la suma total de errores al cuadrado más que cualquier fusión anterior. Para evitar detenerse demasiado pronto en casos en los que debería haber solo un segmento, no consideraremos una fusión como un punto de parada potencial a menos que resulte en un aumento en el error total que sea inferior al 3% del error total de una regresión con un segmento. (El 3% es un umbral arbitrario, pero hemos comprobado que funciona bien en la práctica. A continuación se presentan un par de ejemplos para demostrar por qué funciona este criterio de detención.
En primer lugar, veamos un conjunto de datos que se generó agregando ruido distribuido normalmente a puntos a lo largo de una sola línea. El algoritmo se ajusta correctamente a un solo segmento a través de este conjunto de datos.
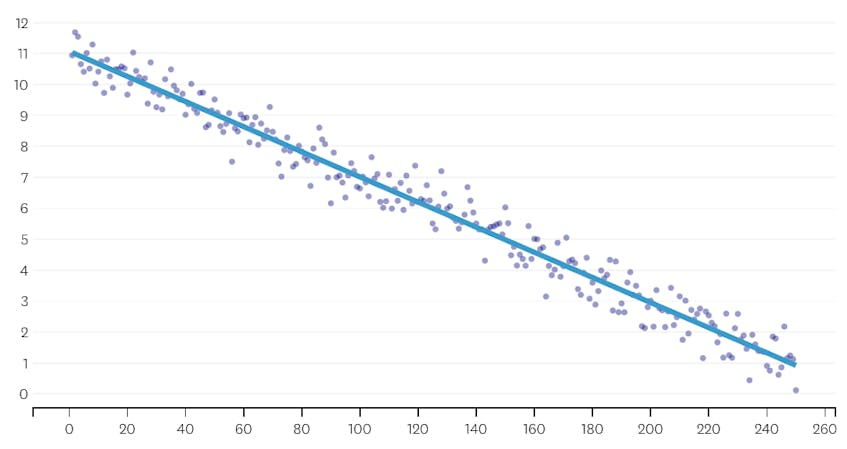
En este caso, ninguna combinación aumenta la suma total de errores al cuadrado en más de un 3%. Por lo tanto, ninguna fusión se considera un punto de parada adecuado, y usamos el estado final después de que se hayan ejecutado todas las fusiones. En la gráfica de abajo, vemos que las fusiones posteriores tienden a introducir más errores que las anteriores (lo que tiene sentido porque cada una afecta más puntos), pero el aumento del error solo aumenta gradualmente a medida que se fusionan más segmentos.
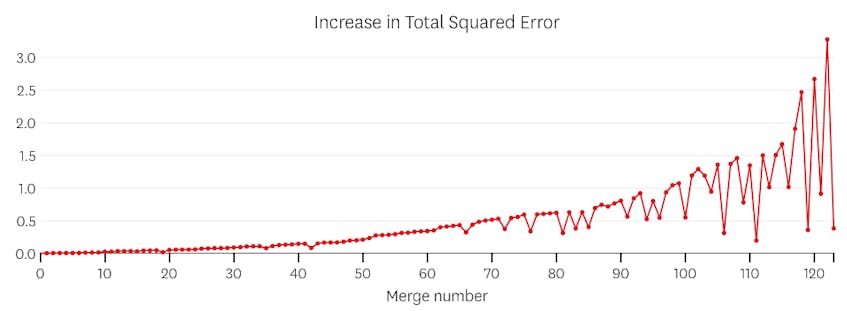
En segundo lugar, veamos un ejemplo donde hay siete segmentos distintos en el conjunto de datos.
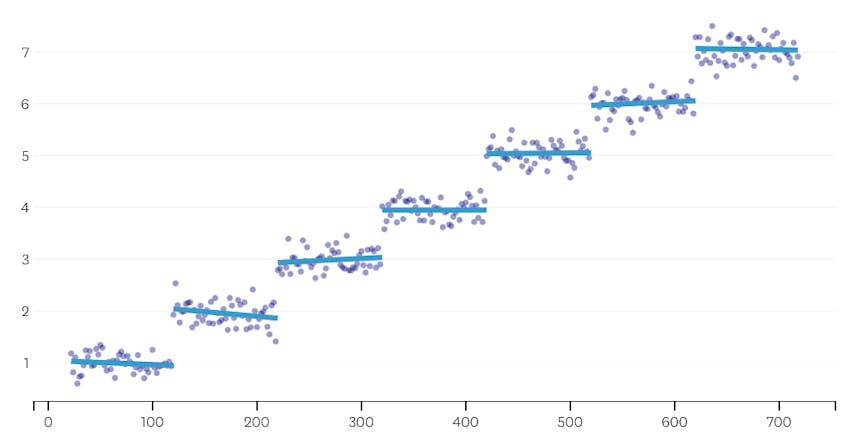
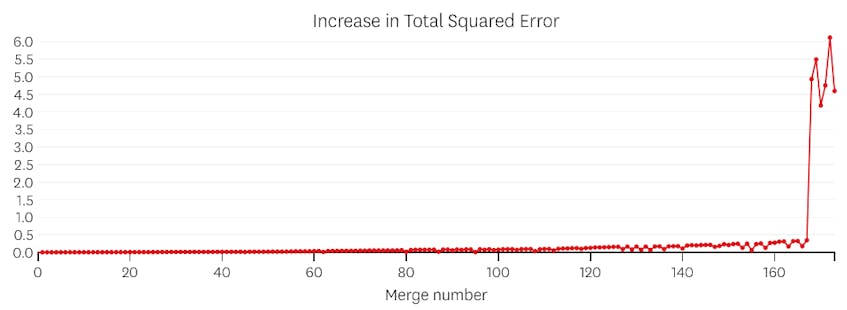
En este caso, cuando miramos la trama de errores introducidos por cada fusión, vemos que las últimas seis fusiones introdujeron mucho más error que cualquiera de las fusiones anteriores. Por lo tanto, nuestro algoritmo recordó el estado de los segmentos de antes de la sexta a última fusión y lo usó como solución final.
El código
En el repositorio de Github de Datadog/piecewise, encontrará nuestra implementación del algoritmo en Python. La función piecewise() es donde ocurre el levantamiento pesado; dado un conjunto de datos, devolverá los coeficientes de ubicación y regresión para cada uno de los segmentos ajustados.
También se incluye en el gist plot_data_with_regression(), una función de envoltura para un trazado rápido y fácil. Un ejemplo rápido de cómo se puede usar esto:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)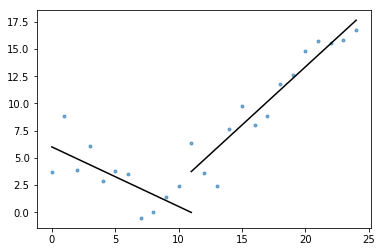
Si bien esta implementación utiliza regresión lineal OLS, el mismo marco se puede adaptar para resolver problemas relacionados. Al reemplazar el error cuadrado con error absoluto o pérdida de Huber, la regresión se puede hacer robusta. O bien, se puede ajustar una función escalonada asignando a cada segmento un valor constante igual al promedio de las observaciones en su dominio.