En este tutorial vamos a explicar, una de las técnicas emergentes y prominentes de incrustación de palabras llamada Word2Vec propuesta por Mikolov et al. en 2013. Hemos recopilado este contenido de diferentes tutoriales y fuentes para facilitar a los lectores en un solo lugar. Espero que ayude.
Word2vec es una combinación de modelos utilizados para representar representaciones distribuidas de palabras en un corpus C. Word2Vec (W2V) es un algoritmo que acepta corpus de texto como entrada y genera una representación vectorial para cada palabra, como se muestra en el diagrama siguiente:

Hay dos versiones de este algoritmo a saber: CBOW y Skip-Gramo. Dado un conjunto de oraciones (también llamadas corpus), el modelo gira en las palabras de cada oración e intenta usar la palabra actual w para predecir sus vecinas (es decir, su contexto), este enfoque se llama «Omitir Gramo», o usa cada uno de estos contextos para predecir la palabra actual w, en ese caso el método se llama «Bolsa Continua de Palabras» (CBOW). Para limitar el número de palabras en cada contexto, se utiliza un parámetro llamado «tamaño de ventana».

Los vectores que usamos para representar palabras se llaman incrustaciones neuronales de palabras, y las representaciones son extrañas. Una cosa describe otra, aunque esas dos cosas son radicalmente diferentes. Como dijo Elvis Costello: «Escribir sobre música es como bailar sobre arquitectura.»Word2vec» vectoriza » las palabras, y al hacerlo hace que el lenguaje natural sea legible por computadora, podemos comenzar a realizar poderosas operaciones matemáticas en las palabras para detectar sus similitudes.
Por lo tanto, una incrustación de palabras neuronales representa una palabra con números. Es una traducción simple, aunque poco probable. Word2vec es similar a un autoencodificador, codificando cada palabra en un vector, pero en lugar de entrenar contra las palabras de entrada a través de la reconstrucción, como lo hace una máquina Boltzmann restringida, word2vec entrena palabras contra otras palabras que las rodean en el corpus de entrada.
Lo hace de una de dos maneras, ya sea usando contexto para predecir una palabra de destino (un método conocido como bolsa continua de palabras, o CBOW), o usando una palabra para predecir un contexto de destino, que se llama omitir gramo. Utilizamos este último método porque produce resultados más precisos en grandes conjuntos de datos.

Cuando el vector de entidad asignado a una palabra no se puede usar para predecir con precisión el contexto de esa palabra, se ajustan los componentes del vector. El contexto de cada palabra en el corpus es el profesor que envía señales de error para ajustar el vector de características. Los vectores de palabras juzgadas similares por su contexto son empujados más juntos ajustando los números en el vector. En este tutorial, nos vamos a centrar en el modelo de saltos de gramo que, en contraste con CBOW, considera la palabra central como entrada, como se muestra en la figura anterior y predice las palabras de contexto.
Descripción general del modelo
Entendimos que tenemos que alimentar una extraña red neuronal con algunos pares de palabras, pero no podemos hacer eso usando como entradas los caracteres reales, tenemos que encontrar alguna forma de representar estas palabras matemáticamente para que la red pueda procesarlas. Una forma de hacer esto es crear un vocabulario de todas las palabras en nuestro texto y luego codificar nuestra palabra como un vector de las mismas dimensiones de nuestro vocabulario. Cada dimensión se puede pensar como una palabra en nuestro vocabulario. Así que tendremos un vector con todos los ceros y un 1 que representa la palabra correspondiente en el vocabulario. Esta técnica de codificación se denomina codificación one-hot. Considerando nuestro ejemplo, si tenemos un vocabulario hecho de las palabras «el», «rápido», «marrón», «zorro», «salta», «sobre»,» el «» perezoso»,» perro», la palabra «marrón» está representada por este vector: .

El Skip-gramo modelo toma en un corpus de texto y crea un hot-vector para cada palabra. Un vector caliente es una representación vectorial de una palabra donde el vector es el tamaño del vocabulario (palabras únicas totales). Todas las dimensiones se establecen en 0, excepto la dimensión que representa la palabra que se usa como entrada en ese momento. Aquí hay un ejemplo de un vector caliente:

La entrada anterior se da a una red neuronal con una sola capa oculta.
Vamos a representar una palabra de entrada como «hormigas»como un vector único. Este vector tendrá 10.000 componentes (uno por cada palabra de nuestro vocabulario) y colocaremos un «1» en la posición correspondiente a la palabra «hormigas», y 0s en todas las demás posiciones. La salida de la red es un único vector (también con 10.000 componentes) que contiene, para cada palabra de nuestro vocabulario, la probabilidad de que una palabra cercana seleccionada al azar sea esa palabra de vocabulario.
En word2vec, se utiliza una representación distribuida de una palabra. Tome un vector con varios cientos de dimensiones (digamos 1000). Cada palabra está representada por una distribución de pesos entre esos elementos. Así que en lugar de un mapeo uno a uno entre un elemento en el vector y una palabra, la representación de una palabra se extiende a través de todos los elementos en el vector, y cada elemento en el vector contribuye a la definición de muchas palabras.
Si etiqueta las dimensiones en un vector de palabras hipotético (no hay tales etiquetas preasignadas en el algoritmo, por supuesto), podría verse un poco como esto:

Tal vector viene a representar de alguna manera abstracta el ‘significado’ de una palabra. Y como veremos a continuación, simplemente examinando un corpus grande es posible aprender vectores de palabras que son capaces de capturar las relaciones entre palabras de una manera sorprendentemente expresiva. También podemos usar los vectores como entradas a una red neuronal. Dado que nuestros vectores de entrada son uno caliente, multiplicar un vector de entrada por la matriz de peso W1 equivale simplemente a seleccionar una fila de W1.
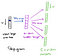

Desde la capa oculta hasta la capa de salida, la segunda matriz de peso W2 se puede usar para calcular una puntuación para cada palabra del vocabulario, y softmax se puede usar para obtener la distribución posterior de las palabras. El modelo skip-gram es lo opuesto al modelo CBOW. Se construye con la palabra de enfoque como vector de entrada único, y las palabras de contexto de destino se encuentran ahora en la capa de salida. La función de activación para la capa oculta simplemente equivale a copiar la fila correspondiente de la matriz de pesos W1 (lineal) como vimos antes. En la capa de salida, ahora generamos distribuciones multinomiales C en lugar de solo una. El objetivo de la formación es mimetizar el error de predicción sumada en todas las palabras de contexto de la capa de salida. En nuestro ejemplo, la entrada sería el «aprendizaje», y esperamos a ver («un», «eficiente», «método», «para», «alto», «calidad», «distribuido», «vector») en la capa de salida.
Aquí está la arquitectura de nuestra red neuronal.

Para nuestro ejemplo, vamos a decir que estamos aprendiendo vectores de palabras con 300 características. Así que la capa oculta va a estar representada por una matriz de peso con 10.000 filas (una por cada palabra de nuestro vocabulario) y 300 columnas (una por cada neurona oculta). 300 funciones es lo que Google usó en su modelo publicado entrenado en el conjunto de datos de Google News (puede descargarlo desde aquí). El número de características es un «hiper parámetro» que solo tendría que ajustar a su aplicación (es decir, probar diferentes valores y ver qué produce los mejores resultados).
Si nos fijamos en las filas de esta matriz de peso, ¡estos son nuestros vectores de palabras!

Así que el objetivo final de todo esto es realmente aprender esta matriz de peso de capa oculta: la capa de salida que tiraremos cuando hayamos terminado. El vector de 1 x 300 palabras para «hormigas» se alimenta a la capa de salida. La capa de salida es un clasificador de regresión softmax. Específicamente, cada neurona de salida tiene un vector de peso que se multiplica contra el vector de palabras de la capa oculta, luego aplica la función exp (x) al resultado. Finalmente, para que las salidas sumen 1, dividimos este resultado por la suma de los resultados de los 10.000 nodos de salida. Aquí hay una ilustración del cálculo de la salida de la neurona de salida para la palabra «coche».

Si dos palabras diferentes tienen «contextos» muy similares (es decir, qué palabras es probable que aparezcan a su alrededor), entonces nuestro modelo necesita producir resultados muy similares para estas dos palabras. Y una forma de que la red genere predicciones de contexto similares para estas dos palabras es si los vectores de palabras son similares. Por lo tanto, si dos palabras tienen contextos similares, entonces nuestra red está motivada para aprender vectores de palabras similares para estas dos palabras. Ta da!
Cada dimensión de la entrada pasa a través de cada nodo de la capa oculta. La dimensión se multiplica por el peso que la lleva a la capa oculta. Debido a que la entrada es un vector caliente, solo uno de los nodos de entrada tendrá un valor distinto de cero (es decir, el valor de 1). Esto significa que para una palabra solo se activarán los pesos asociados con el nodo de entrada con valor 1, como se muestra en la imagen de arriba.
Como la entrada en este caso es un vector caliente, solo uno de los nodos de entrada tendrá un valor distinto de cero. Esto significa que solo los pesos conectados a ese nodo de entrada se activarán en los nodos ocultos. A continuación se muestra un ejemplo de los pesos que se tendrán en cuenta para la segunda palabra del vocabulario:
La representación vectorial de la segunda palabra del vocabulario (que se muestra en la red neuronal de arriba) se verá de la siguiente manera, una vez activada en la capa oculta:
Esos pesos comienzan como valores aleatorios. La red se entrena entonces para ajustar los pesos para representar las palabras de entrada. Aquí es donde la capa de salida se vuelve importante. Ahora que estamos en la capa oculta con una representación vectorial de la palabra, necesitamos una forma de determinar qué tan bien hemos predicho que una palabra encajará en un contexto particular. El contexto de la palabra es un conjunto de palabras dentro de una ventana a su alrededor, como se muestra a continuación:

La imagen de arriba muestra que el contexto del viernes incluye palabras como «gato» y «es». El objetivo de la red neuronal es predecir que el «viernes» entra en este contexto.
Activamos la capa de salida multiplicando el vector que pasamos a través de la capa oculta (que era el vector caliente de entrada * pesos que ingresan al nodo oculto) con una representación vectorial de la palabra de contexto (que es el vector caliente para la palabra de contexto * pesos que ingresan al nodo de salida). El estado de la capa de salida de la primera palabra de contexto se puede visualizar a continuación:

La multiplicación anterior se realiza para cada par de palabras de palabra a contexto. A continuación, calculamos la probabilidad de que una palabra pertenezca a un conjunto de palabras de contexto utilizando los valores resultantes de las capas oculta y de salida. Por último, aplicamos el descenso de gradiente estocástico para cambiar los valores de los pesos con el fin de obtener un valor más deseable para la probabilidad calculada.
En descenso de gradiente necesitamos calcular el gradiente de la función que se está optimizando en el punto que representa el peso que estamos cambiando. El gradiente se utiliza para elegir la dirección en la que se realiza un paso para avanzar hacia el óptimo local, como se muestra en el ejemplo de minimización a continuación.
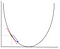
El peso va a ser cambiado haciendo un paso en la dirección del punto óptimo (en el ejemplo anterior, el punto más bajo en el gráfico). El nuevo valor se calcula restando del valor de peso actual la función derivada en el punto del peso escalado por la tasa de aprendizaje. El siguiente paso es usar Backpropagation, para ajustar los pesos entre varias capas. El error que se calcula al final de la capa de salida se devuelve de la capa de salida a la capa oculta aplicando la Regla de cadena. El descenso de gradiente se utiliza para actualizar los pesos entre estas dos capas. El error se ajusta en cada capa y se envía de vuelta. Aquí hay un diagrama para representar la contrapropagación:

Comprender el uso de Ejemplo
Word2vec utiliza una sola capa oculta, una red neuronal completamente conectada, como se muestra a continuación. Las neuronas de la capa oculta son todas neuronas lineales. La capa de entrada está configurada para tener tantas neuronas como palabras en el vocabulario para el entrenamiento. El tamaño de capa oculta se establece en la dimensionalidad de los vectores de palabras resultantes. El tamaño de la capa de salida es el mismo que el de la capa de entrada. Por lo tanto, si el vocabulario para aprender vectores de palabras consiste en V palabras y N para ser la dimensión de vectores de palabras, la entrada a las conexiones de capas ocultas se puede representar mediante una matriz WI de tamaño VxN con cada fila representando una palabra de vocabulario. De la misma manera, las conexiones de la capa oculta a la capa de salida se pueden describir mediante matriz WO de tamaño NxV. En este caso, cada columna de la matriz WO representa una palabra del vocabulario dado.

La entrada a la red se codifica utilizando la representación «1-out of-V», lo que significa que solo una línea de entrada se establece en una y el resto de las líneas de entrada se establecen en cero.
Supongamos que tenemos un corpus de entrenamiento con las siguientes frases:
«el perro vio un gato»,» el perro persiguió al gato»,»el gato se subió a un árbol»
El vocabulario del corpus tiene ocho palabras. Una vez ordenada alfabéticamente, cada palabra puede ser referenciada por su índice. Para este ejemplo, nuestra red neuronal tendrá ocho neuronas de entrada y ocho de salida. Supongamos que decidimos usar tres neuronas en la capa oculta. Esto significa que WI y WO serán matrices de 8×3 y 3×8, respectivamente. Antes de comenzar el entrenamiento, estas matrices se inicializan a pequeños valores aleatorios, como es habitual en el entrenamiento de redes neuronales. Solo por el bien de la ilustración, asumamos que WI y WO se inicializarán a los siguientes valores:

Supongamos que queremos que la red para aprender la relación entre las palabras «gato» y «subió». Es decir, la red debe mostrar una alta probabilidad de» escalado «cuando se ingresa «gato» a la red. En la terminología de incrustación de palabras, la palabra «gato «se refiere como la palabra de contexto y la palabra» escalado » se refiere como la palabra objetivo. En este caso, el vector de entrada X será t. Observe que solo el segundo componente del vector es 1. Esto se debe a que la palabra de entrada es «gato», que mantiene la posición número dos en la lista ordenada de palabras del corpus. Dado que la palabra objetivo es «escalado», el vector objetivo se verá como t. Con el vector de entrada que representa «gato», la salida en las neuronas de la capa oculta se puede calcular como:
Ht = XtWI =
No debería sorprendernos que el vector H de las salidas de neuronas ocultas imite los pesos de la segunda fila de la matriz WI debido a la representación de 1 fuera de V. Por lo tanto, la función de las conexiones de entrada a capa oculta es básicamente copiar el vector de palabra de entrada a la capa oculta. Llevando a cabo manipulaciones similares para la capa oculta a la de salida, el vector de activación para las neuronas de la capa de salida se puede escribir como
HtWO =
Ya que, el objetivo es producir probabilidades para palabras en la capa de salida, Pr(wordk|wordcontext) para k = 1, V, para reflejar su siguiente relación de palabras con la palabra de contexto en la entrada, necesitamos la suma de salidas de neuronas en la capa de salida para agregar a una. Word2vec logra esto convirtiendo los valores de activación de las neuronas de la capa de salida en probabilidades usando la función softmax. Por lo tanto, la salida de la neurona k-ésima se calcula mediante la siguiente expresión donde la activación (n) representa el valor de activación de la neurona de la capa de salida n-ésima:
Por lo tanto, las probabilidades de ocho palabras en el corpus son:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
La probabilidad en negrita es para la palabra objetivo elegida «escalado». Dado el vector de destino t, el vector de error para la capa de salida se calcula fácilmente restando el vector de probabilidad del vector de destino. Una vez que se conoce el error, los pesos en las matrices WO y WI se pueden actualizar utilizando backpropagation. Por lo tanto, el entrenamiento puede proceder presentando diferentes pares de palabras de contexto-objetivo del corpus. Así es como Word2vec aprende las relaciones entre palabras y en el proceso desarrolla representaciones vectoriales para palabras en el corpus.
La idea detrás de word2vec es representar palabras por un vector de números reales de dimensión d. Por lo tanto, la segunda matriz es la representación de esas palabras. La i-ésima línea de esta matriz es la representación vectorial de la i-ésima palabra. Digamos que en tu ejemplo tienes 5 palabras:, entonces el primer vector significa que estás considerando la palabra «Caballo «y así es la representación de» Caballo». Del mismo modo, es la representación de la palabra «León».

A mi conocimiento, no existe ningún «sentido humano» específicamente para cada uno de los números en estas representaciones. Un número no representa si la palabra es un verbo o no, un adjetivo o no It Son solo los pesos que cambia para resolver su problema de optimización para aprender la representación de sus palabras.
Un diagrama visual que mejor elabora el proceso de multiplicación de matrices de word2vec se representa en la siguiente figura:

La primera matriz representa el vector de entrada en un formato caliente. La segunda matriz representa los pesos sinápticos de las neuronas de la capa de entrada a las neuronas de la capa oculta. Observe especialmente la esquina superior izquierda donde la matriz de capas de entrada se multiplica con la matriz de peso. Ahora mira arriba a la derecha. Esta capa de entrada de multiplicación de matrices producida por puntos con pesos Transpuestos es solo una forma práctica de representar la red neuronal en la parte superior derecha.
La primera parte, representa la palabra de entrada como un vector caliente y la otra matriz representa el peso para la conexión de cada una de las neuronas de la capa de entrada a las neuronas de la capa oculta. A medida que Word2Vec entrena, se propaga hacia atrás (utilizando el descenso de gradiente) en estos pesos y los cambia para dar mejores representaciones de las palabras como vectores. Una vez que se ha completado el entrenamiento, se utiliza solo esta matriz de peso, se toma por ejemplo ‘perro’ y se multiplica con la matriz de peso mejorada para obtener la representación vectorial de ‘perro’ en una dimensión = no de neuronas de capa oculta. En el diagrama, el número de neuronas de capa oculta es 3.
En pocas palabras, el modelo Skip-gram invierte el uso de palabras de destino y de contexto. En este caso, la palabra de destino se alimenta en la entrada, la capa oculta permanece igual y la capa de salida de la red neuronal se replica varias veces para acomodar el número elegido de palabras de contexto. Tomando el ejemplo de «gato » y» árbol «como palabras de contexto y» escalado » como la palabra objetivo, el vector de entrada en el modelo de gramo descremado sería t, mientras que las dos capas de salida tendrían t y t como vectores objetivo respectivamente. En lugar de producir un vector de probabilidades, se producirían dos de estos vectores para el ejemplo actual. El vector de error para cada capa de salida se produce de la manera descrita anteriormente. Sin embargo, los vectores de error de todas las capas de salida se suman para ajustar los pesos mediante contrapropagación. Esto garantiza que la matriz de peso WO para cada capa de salida permanezca idéntica durante todo el entrenamiento.
Necesitamos algunas modificaciones adicionales al modelo básico de salto de gramo que son importantes para que sea factible entrenar. Ejecutar el descenso de gradiente en una red neuronal tan grande va a ser lento. Y para empeorar las cosas, necesita una gran cantidad de datos de entrenamiento para ajustar tantos pesos y evitar un ajuste excesivo. millones de pesos multiplicados por miles de millones de muestras de entrenamiento significa que entrenar este modelo va a ser una bestia. Para ello, los autores han propuesto dos técnicas llamadas submuestreo y muestreo negativo en las que se eliminan palabras insignificantes y se actualiza solo una muestra específica de pesos.
Mikolov et al. también use un enfoque de submuestreo simple para contrarrestar el desequilibrio entre las palabras raras y frecuentes en el conjunto de capacitación (por ejemplo, «en», «la» y «a» proporcionan menos valor de información que las palabras raras). Cada palabra en el conjunto de entrenamiento se descarta con probabilidad P (wi) donde

f (wi) es la frecuencia de la palabra wi y t es un umbral elegido, típicamente alrededor de 10-5.
Detalles de implementación
Word2vec se ha implementado en varios idiomas, pero aquí nos centraremos especialmente en Java, p. ej., DeepLearning4j, darks-learning y python . Se han implementado varios algoritmos de redes neuronales en DL4j, el código está disponible en GitHub.
Para implementarlo en DL4j, pasaremos por algunos pasos que se indican a continuación:
a) Configuración de Word2Vec
Cree un nuevo proyecto en IntelliJ usando Maven. A continuación, especifique propiedades y dependencias en el POM.archivo xml en el directorio raíz de tu proyecto.
b) Cargar datos
Ahora cree y nombre una nueva clase en Java. Después de eso, tomarás las oraciones crudas en tu .archivo txt, atraviéselos con su iterador y sométalos a algún tipo de procesamiento previo, como convertir todas las palabras a minúsculas.
String filePath = new ClassPathResource («raw_sentences.txt»).getFile().getAbsolutePath ();
log.info («Cargar & Vectorizar oraciones….»);
// Elimine espacios en blanco antes y después de cada línea
SentenceIterator iter = new BasicLineIterator (ruta de archivo);
Si desea cargar un archivo de texto además de las oraciones proporcionadas en nuestro ejemplo, haría esto:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenizar los datos
Word2vec necesita palabras en lugar de oraciones completas, por lo que el siguiente paso es tokenizar los datos. Tokenizar un texto es dividirlo en sus unidades atómicas, creando un nuevo token cada vez que golpeas un espacio en blanco, por ejemplo.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Entrenando el modelo
Ahora que los datos están listos, puede configurar la red neuronal Word2vec y alimentar los tokens.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Esta configuración acepta varios hiperparámetros. Algunos requieren alguna explicación:
- El tamaño de lote es la cantidad de palabras que procesa a la vez.
- minWordFrequency es el número mínimo de veces que una palabra debe aparecer en el corpus. Aquí, si aparece menos de 5 veces, no se aprende. Las palabras deben aparecer en múltiples contextos para aprender características útiles sobre ellas. En cuerpos muy grandes, es razonable elevar el mínimo.
- useAdaGrad-Adagrad crea un degradado diferente para cada función. Aquí no nos preocupa eso.
- layerSize especifica el número de entidades en el vector de palabras. Esto es igual al número de dimensiones en el espacio de características. Las palabras representadas por 500 entidades se convierten en puntos en un espacio de 500 dimensiones.
- learningRate es el tamaño de paso para cada actualización de los coeficientes, ya que las palabras se reposicionan en el espacio de entidades.
- minLearningRate es el nivel mínimo de la tasa de aprendizaje. La tasa de aprendizaje decae a medida que disminuye el número de palabras en las que entrenas. Si la tasa de aprendizaje se reduce demasiado, el aprendizaje de la red ya no es eficiente. Esto mantiene los coeficientes en movimiento.
- iterar indica a la red en qué lote del conjunto de datos está entrenando.
- tokenizer alimenta las palabras del lote actual.
- vec.fit() indica a la red configurada que comience el entrenamiento.
e) Evaluar el Modelo, utilizando Word2vec
El siguiente paso es evaluar la calidad de sus vectores de entidades.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
La línea vec.similarity("word1","word2") devolverá la similitud de coseno de las dos palabras que introduzca. Cuanto más cerca esté de 1, más similar percibirá la red que son esas palabras (véase el ejemplo de Suecia-Noruega más arriba). Por ejemplo:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
Con vec.wordsNearest("word1", numWordsNearest), las palabras impresas en la pantalla le permiten ver si la red tiene palabras semánticamente similares agrupadas. Puede establecer el número de palabras más cercanas que desee con el segundo parámetro de wordsNearest. Por ejemplo:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec en Java http://deeplearning4j.org/word2vec.html
7) Word2Vec y Doc2Vec en Python en genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html