- Introduction
- Pour en savoir plus:
- Suppression d’objets avec Hibernate
- Procédures stockées avec Hibernate
- Un aperçu des identifiants dans Hibernate/JPA
- Session en tant qu’implémentation de contexte de persistance
- 2.1. Gestion des instances d’entités
- 2.2. États des instances d’entité
- 2.3. La conformité à la spécification JPA
- Différences Entre les opérations
- 3.1. Persist
- 3.2. Save
- 3.3. Merge
- 3.4. Update
- 3.5. SaveOrUpdate
- Que faut-il utiliser?
- Conclusion
Introduction
Dans cet article, nous allons discuter des différences entre plusieurs méthodes de l’interface de session: save, persist, update, merge, saveOrUpdate.
Ce n’est pas une introduction à Hibernate et vous devriez déjà connaître les bases de la configuration, du mappage objet-relationnel et du travail avec les instances d’entité. Pour un article d’introduction à l’hibernation, visitez notre tutoriel sur Hibernate 4 avec Spring.
Pour en savoir plus:
Suppression d’objets avec Hibernate
Guide rapide pour supprimer une entité dans Hibernate.
En savoir plus →
Procédures stockées avec Hibernate
Cet article explique brièvement comment appeler les procédures de stockage depuis Hibernate.
En savoir plus →
Un aperçu des identifiants dans Hibernate/JPA
Apprenez à mapper les identifiants d’entité avec Hibernate.
En savoir plus →
Session en tant qu’implémentation de contexte de persistance
L’interface de session dispose de plusieurs méthodes qui aboutissent éventuellement à enregistrer des données dans la base de données : persist, save, update, merge, saveOrUpdate. Pour comprendre la différence entre ces méthodes, nous devons d’abord discuter du but de la Session en tant que contexte de persistance et de la différence entre les états des instances d’entité par rapport à la Session.
Nous devons également comprendre l’historique du développement d’Hibernate qui a conduit à certaines méthodes d’API en partie dupliquées.
2.1. Gestion des instances d’entités
Outre le mappage objet-relationnel lui-même, l’un des problèmes que Hibernate était destiné à résoudre est le problème de la gestion des entités pendant l’exécution. La notion de « contexte de persistance » est la solution d’Hibernate à ce problème. Le contexte de persistance peut être considéré comme un conteneur ou un cache de premier niveau pour tous les objets que vous avez chargés ou enregistrés dans une base de données au cours d’une session.
La session est une transaction logique, dont les limites sont définies par la logique métier de votre application. Lorsque vous travaillez avec la base de données via un contexte de persistance et que toutes vos instances d’entité sont attachées à ce contexte, vous devez toujours avoir une seule instance d’entité pour chaque enregistrement de base de données avec lequel vous avez interagi pendant la session.
Dans Hibernate, le contexte de persistance est représenté par org.hiberner.Instance de session. Pour JPA, c’est le javax.persistance.Gestionnaire d’entités. Lorsque nous utilisons Hibernate en tant que fournisseur JPA et opérons via l’interface EntityManager, l’implémentation de cette interface encapsule essentiellement l’objet Session sous-jacent. Cependant, la session Hibernate fournit une interface plus riche avec plus de possibilités, il est donc parfois utile de travailler directement avec la Session.
2.2. États des instances d’entité
Toute instance d’entité de votre application apparaît dans l’un des trois états principaux par rapport au contexte de persistance de session:
- transitoire — cette instance n’est pas, et n’a jamais été, attachée à une Session ; cette instance n’a pas de lignes correspondantes dans la base de données ; il s’agit généralement d’un nouvel objet que vous avez créé pour l’enregistrer dans la base de données;
- persistant — cette instance est associée à un objet de Session unique ; lors du vidage de la Session dans la base de données, cette entité est garantie d’avoir un enregistrement cohérent correspondant dans la base de données ;
- détaché — cette instance était autrefois attachée à une Session (dans un état persistant), mais maintenant ce n’est pas le cas ; une instance entre dans cet état si vous l’expulsez du contexte, effacez ou fermez la Session, ou soumettez l’instance à un processus de sérialisation/ désérialisation.
Voici un diagramme d’état simplifié avec des commentaires sur les méthodes de session qui effectuent les transitions d’état.
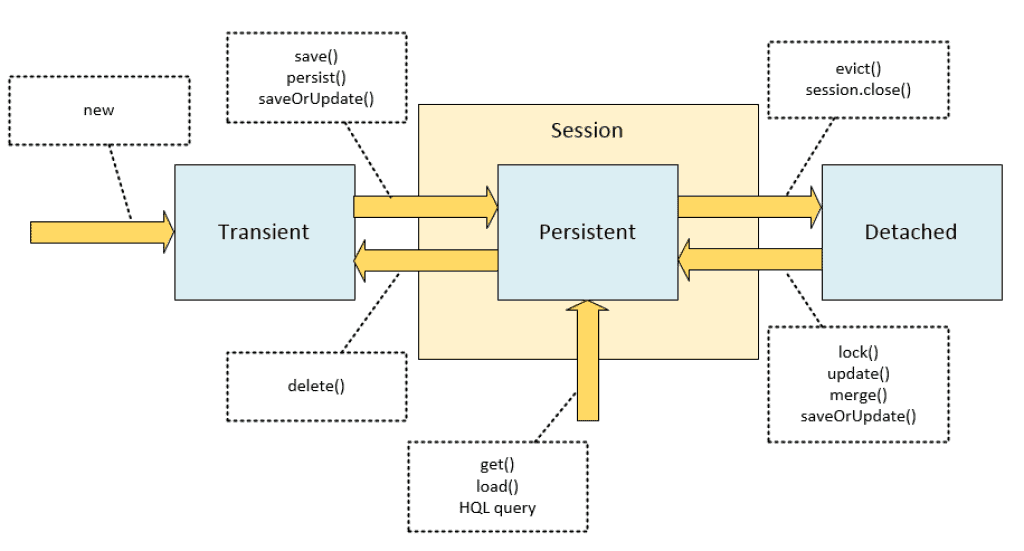
Lorsque l’instance d’entité est à l’état persistant, toutes les modifications que vous apportez aux champs mappés de cette instance seront appliquées aux enregistrements et champs de base de données correspondants lors du vidage de la session. L’instance persistante peut être considérée comme » en ligne « , alors que l’instance détachée est devenue » hors ligne » et n’est pas surveillée pour les modifications.
Cela signifie que lorsque vous modifiez des champs d’un objet persistant, vous n’avez pas besoin d’appeler save, update ou l’une de ces méthodes pour obtenir ces modifications dans la base de données: tout ce dont vous avez besoin est de valider la transaction, ou de vider ou de fermer la session, lorsque vous en avez terminé.
2.3. La conformité à la spécification JPA
Hibernate était l’implémentation Java ORM la plus réussie. Pas étonnant que la spécification de l’API de persistance Java (JPA) ait été fortement influencée par l’API Hibernate. Malheureusement, il y avait aussi de nombreuses différences: certaines majeures, d’autres plus subtiles.
Pour servir d’implémentation de la norme JPA, les API Hibernate ont dû être révisées. Plusieurs méthodes ont été ajoutées à l’interface de session pour correspondre à l’interface EntityManager. Ces méthodes servent le même but que les méthodes « originales », mais sont conformes à la spécification et présentent donc quelques différences.
Différences Entre les opérations
Il est important de comprendre dès le début que toutes les méthodes (persist, save, update, merge, saveOrUpdate) n’entraînent pas immédiatement les instructions SQL UPDATE ou INSERT correspondantes. L’enregistrement réel des données dans la base de données se produit lors de la validation de la transaction ou du vidage de la session.
Les méthodes mentionnées gèrent essentiellement l’état des instances d’entité en les faisant passer d’un état à l’autre tout au long du cycle de vie.
En tant qu’entité d’exemple, nous utiliserons une personne d’entité simple mappée par annotation:
@Entitypublic class Person { @Id @GeneratedValue private Long id; private String name; // ... getters and setters}3.1. Persist
La méthode persist est destinée à ajouter une nouvelle instance d’entité au contexte de persistance, c’est-à-dire à faire passer une instance d’un état transitoire à un état persistant.
Nous l’appelons généralement lorsque nous voulons ajouter un enregistrement à la base de données (persister une instance d’entité):
Person person = new Person();person.setName("John");session.persist(person);Que se passe-t-il après l’appel de la méthode persist ? L’objet personne est passé de l’état transitoire à l’état persistant. L’objet est maintenant dans le contexte de persistance, mais n’est pas encore enregistré dans la base de données. La génération d’instructions INSERT n’aura lieu qu’au moment de l’engagement de la transaction, du vidage ou de la fermeture de la session.
Notez que la méthode persist a un type de retour void. Il fonctionne sur l’objet passé « en place », changeant son état. La variable person fait référence à l’objet persistant réel.
Cette méthode est un ajout ultérieur à l’interface de session. La principale caractéristique de différenciation de cette méthode est qu’elle est conforme à la spécification JSR-220 (persistance EJB). La sémantique de cette méthode est strictement définie dans la spécification, qui stipule essentiellement que:
- une instance transitoire devient persistante (et l’opération tombe en cascade sur toutes ses relations avec cascade=PERSIST ou cascade=ALL),
- si une instance est déjà persistante, cet appel n’a aucun effet pour cette instance particulière (mais il tombe toujours en cascade sur ses relations avec cascade=PERSIST ou cascade=ALL),
- si une instance est détachée, vous devez vous attendre à une exception, soit en appelant cette méthode, soit en validant ou en vidant la session .
Notez qu’il n’y a rien ici qui concerne l’identifiant d’une instance. La spécification n’indique pas que l’id sera généré immédiatement, quelle que soit la stratégie de génération d’id. La spécification de la méthode persist permet à l’implémentation d’émettre des instructions pour générer l’id lors de la validation ou du vidage, et l’id n’est pas garanti non null après avoir appelé cette méthode, vous ne devez donc pas vous y fier.
Vous pouvez appeler cette méthode sur une instance déjà persistante, et rien ne se passe. Mais si vous essayez de conserver une instance détachée, l’implémentation est obligée de lever une exception. Dans l’exemple suivant, nous persistons l’entité, l’expulsons du contexte pour qu’elle se détache, puis essayons de persister à nouveau. Le deuxième appel à la session.persist() provoque une exception, donc le code suivant ne fonctionnera pas:
Person person = new Person();person.setName("John");session.persist(person);session.evict(person);session.persist(person); // PersistenceException!3.2. Save
La méthode save est une méthode d’Hibernation « originale » qui n’est pas conforme à la spécification JPA.
Son but est fondamentalement le même que persist, mais il a des détails d’implémentation différents. La documentation de cette méthode indique strictement qu’il persiste l’instance, « attribuant d’abord un identifiant généré ». La méthode est garantie de renvoyer la valeur sérialisable de cet identifiant.
Person person = new Person();person.setName("John");Long id = (Long) session.save(person);L’effet de l’enregistrement d’une instance déjà persistante est le même qu’avec persist. La différence survient lorsque vous essayez d’enregistrer une instance détachée:
Person person = new Person();person.setName("John");Long id1 = (Long) session.save(person);session.evict(person);Long id2 = (Long) session.save(person);La variable id2 sera différente de id1. L’appel de save sur une instance détachée crée une nouvelle instance persistante et lui attribue un nouvel identifiant, ce qui entraîne un enregistrement en double dans une base de données lors de la validation ou du vidage.
3.3. Merge
L’intention principale de la méthode merge est de mettre à jour une instance d’entité persistante avec de nouvelles valeurs de champ à partir d’une instance d’entité détachée.
Par exemple, supposons que vous ayez une interface RESTful avec une méthode pour récupérer un objet sérialisé JSON par son id à l’appelant et une méthode qui reçoit une version mise à jour de cet objet de l’appelant. Une entité qui a traversé une telle sérialisation / désérialisation apparaîtra dans un état détaché.
Après avoir désérialisé cette instance d’entité, vous devez obtenir une instance d’entité persistante à partir d’un contexte de persistance et mettre à jour ses champs avec de nouvelles valeurs à partir de cette instance détachée. Donc, la méthode de fusion fait exactement cela:
- recherche une instance d’entité par id extrait de l’objet transmis (soit une instance d’entité existante du contexte de persistance est récupérée, soit une nouvelle instance chargée à partir de la base de données) ;
- copie les champs de l’objet transmis vers cette instance ;
- renvoie une instance nouvellement mise à jour.
Dans l’exemple suivant, nous expulsons (détachons) l’entité enregistrée du contexte, modifions le champ nom, puis fusionnons l’entité détachée.
Person person = new Person(); person.setName("John"); session.save(person);session.evict(person);person.setName("Mary");Person mergedPerson = (Person) session.merge(person);Notez que la méthode merge renvoie un objet — il s’agit de l’objet mergedPerson qui a été chargé dans le contexte de persistance et mis à jour, et non de l’objet person que vous avez passé en argument. Ce sont deux objets différents, et l’objet personne doit généralement être supprimé (de toute façon, ne comptez pas sur le fait qu’il soit attaché au contexte de persistance).
Comme avec la méthode persist, la méthode de fusion est spécifiée par JSR-220 pour avoir certaines sémantiques sur lesquelles vous pouvez compter:
- si l’entité est détachée, elle est copiée sur une entité persistante existante ;
- si l’entité est transitoire, elle est copiée sur une entité persistante nouvellement créée ;
- cette opération est en cascade pour toutes les relations avec cascade=MERGE ou cascade=ALL mapping ;
- si l’entité est persistante, cet appel de méthode n’a pas d’effet sur elle (mais la cascade a toujours lieu).
3.4. Update
Comme pour persist et save, la méthode update est une méthode d’Hibernation « originale » qui était présente bien avant l’ajout de la méthode de fusion. Sa sémantique diffère en plusieurs points clés:
- il agit sur l’objet passé (son type de retour est nul) ; la méthode update fait passer l’objet passé de l’état détaché à l’état persistant ;
- cette méthode lève une exception si vous lui transmettez une entité transitoire.
Dans l’exemple suivant, nous sauvegardons l’objet, puis l’expulsons (le détachons) du contexte, puis changeons son nom et appelons update. Notez que nous ne mettons pas le résultat de l’opération de mise à jour dans une variable distincte, car la mise à jour a lieu sur l’objet personne lui-même. Fondamentalement, nous rattachons à nouveau l’instance d’entité existante au contexte de persistance — ce que la spécification JPA ne nous permet pas de faire.
Person person = new Person();person.setName("John");session.save(person);session.evict(person);person.setName("Mary");session.update(person);Essayer d’appeler update sur une instance transitoire entraînera une exception. Ce qui suit ne fonctionnera pas:
Person person = new Person();person.setName("John");session.update(person); // PersistenceException!3.5. SaveOrUpdate
Cette méthode apparaît uniquement dans l’API Hibernate et n’a pas sa contrepartie standardisée. Similaire à update, il peut également être utilisé pour rattacher des instances.
En fait, la classe interne DefaultUpdateEventListener qui traite la méthode de mise à jour est une sous-classe de DefaultSaveOrUpdateListener, remplaçant simplement certaines fonctionnalités. La principale différence de la méthode saveOrUpdate est qu’elle ne lève pas d’exception lorsqu’elle est appliquée à une instance transitoire ; au lieu de cela, elle rend cette instance transitoire persistante. Le code suivant persistera une instance de Person nouvellement créée:
Person person = new Person();person.setName("John");session.saveOrUpdate(person);Vous pouvez considérer cette méthode comme un outil universel pour rendre un objet persistant quel que soit son état qu’il soit transitoire ou détaché.
Que faut-il utiliser?
Si vous n’avez pas d’exigences particulières, en règle générale, vous devez vous en tenir aux méthodes persist et merge, car elles sont standardisées et garanties conformes à la spécification JPA.
Ils sont également portables au cas où vous décidiez de passer à un autre fournisseur de persistance, mais ils peuvent parfois sembler moins utiles que les méthodes Hibernate « originales », save, update et saveOrUpdate.
Conclusion
Nous avons discuté de l’objectif des différentes méthodes de session d’Hibernation en relation avec la gestion des entités persistantes en cours d’exécution. Nous avons appris comment ces méthodes transitent les instances d’entités tout au long de leur cycle de vie et pourquoi certaines de ces méthodes ont des fonctionnalités dupliquées.