Par Doble Engineering Company in Enterprise Asset Management / Juin 25, 2020
Partagez ça…Facebook

Pinterest

Twitter

Linkedin
Le monde des données et de l’analyse est en constante évolution. Dans ses jours les plus simples, l’organisation typique des données consistait en certains fichiers, bases de données applicatives ou transactionnelles, entrepôts de données et dépôts de données de reporting. Alors que les sources de données, les volumes, les vitesses de génération et le processus de collecte ont augmenté au fil des ans, l’environnement informatique d’aujourd’hui doit gérer des ensembles de données extrêmement volumineux – communément appelés « big data » – qui révèlent des modèles, des tendances, etc., sur lesquels les organisations peuvent fonder leurs décisions.
La plupart des organisations disposent aujourd’hui de nombreux composants, sinon de la totalité, mis en évidence dans l’architecture de référence présentée à la figure 1 – applications, systèmes et sources, transfert de données, couche de données d’entreprise, services de données, analyses et rapports, et traitement avancé des données.
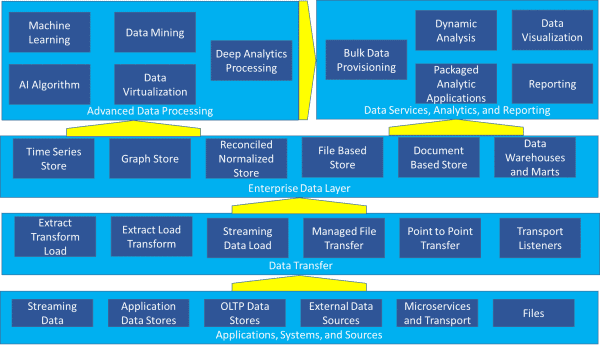
Figure 1 – Architecture de référence complexe
Avec l’entrepôt de données et les magasins représentés comme l’un des 28 composants possibles, il est difficile de comprendre comment ils s’intègrent dans l’image à première vue. Mais la plupart des organisations se préoccupent actuellement de plus qu’un entrepôt de données – elles doivent gérer de manière cohérente un environnement complexe comme celui représenté à la figure 1.
Les architectures Kimball et Inmon offrent toutes deux des frameworks pour aider au développement d’une architecture de référence complexe.
Mise à jour rapide des deux approches
Avant d’appliquer les modèles Kimball ou Inmon, il convient de revoir les différences entre les deux approches. Découvrez les représentations visuelles de chacun dans la figure 21 et la figure 32.
Le travail de Kimball et d’Inmon – les fondateurs des modèles respectifs – s’est mis au défi. Alors que les deux approches sont principalement motivées par le cycle de développement d’un modèle de données, les modèles sont basés sur une approche axée sur une approche ascendante ou descendante. Ces tensions ont joué dans le développement de l’ensemble des environnements de stockage et d’analyse des données.
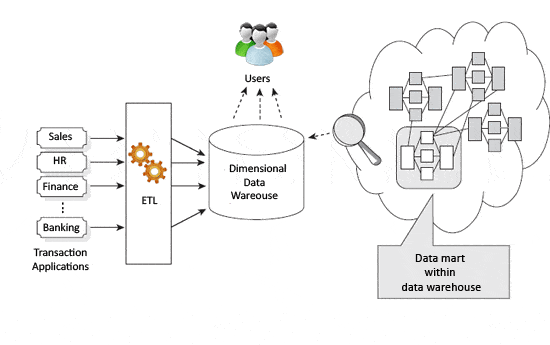
Figure 2 – Kimball visuel

Vue Figure 3 – Vue Inmon visuelle
L’approche Kimball indique que les entrepôts de données et les magasins de données sont pilotés par des processus métier et des questions métier. Le danger évident pour cela est que les données utiles ne soient pas nécessairement catégorisées ou capturées car elles ne rentreraient pas dans le processus métier défini.
L’approche Inmon indique la création d’un entrepôt de données d’entreprise avec des modèles logiques conçus pour chaque entité autour d’un sujet, tels que le compteur, la facture et l’actif. Le défi est que si les principaux sujets peuvent représenter une différenciation, les entités qui les soutiennent peuvent représenter des points communs qui peuvent être perdus.
Par exemple, l’emplacement d’un compteur représenté par un emplacement de service, l’adresse de facturation représentée dans la facture et l’emplacement d’inventaire ou de déploiement d’un actif peuvent tous partager des attributs communs. Même sous Inmon, il existe un risque que l’emplacement du service, l’adresse de facturation, l’actif, l’emplacement de l’inventaire et l’emplacement de déploiement des actifs soient représentés sous la forme de cinq objets différents, car ils sont considérés comme prenant en charge différents secteurs verticaux de l’organisation avec différents data marts.
Les approches Inmon et Kimball sont toutes deux guidées par le cycle pour développer le modèle de données conceptuel, puis implémenter les modèles de données sous une forme physicalisée. Ce cycle peut prendre en charge des approches de développement plus agiles, mais il s’alignera le plus étroitement avec une approche de développement de type cascade en raison de la linéarité de la recherche (basée sur le processus ou le sujet de l’entreprise), du développement du modèle conceptuel (basé sur les données du processus ou du sujet de l’entreprise) et du développement du modèle physique.
Passer à l’étape suivante
Un processus agile pourrait rendre difficile l’injection de cycles dans ce type d’activité de développement. Le défi pour chaque organisation sera de tirer les leçons des approches Inmon et Kimball et de les appliquer dans un nouveau contexte.
Plus de détails sur la façon d’appliquer les motifs à un environnement complexe à venir dans la deuxième partie de cette série de blogs – restez à l’écoute!
En attendant, consultez notre récent article sur la mise en œuvre réussie de la gestion de l’information d’entreprise (EIM).