- Que sont les liens internes?
- Exemple de code
- Format optimal
- Qu’est-ce qu’un lien interne ?
- Bonnes pratiques SEO
- Liens dans les formulaires de soumission obligatoires
- Liens Uniquement Accessibles Via des boîtes de recherche internes
- Liens en Javascript non analysable
- Liens dans Flash, Java ou d’autres Plug-Ins
- Liens pointant vers des Pages bloquées par la balise Meta Robots ou des Robots.txt
- Liens sur des pages contenant des centaines ou des milliers de liens
- Liens dans des cadres ou des cadres en I
- Continuez à apprendre
Que sont les liens internes?
Les liens internes sont des hyperliens qui pointent vers (cible) le même domaine que le domaine sur lequel le lien existe (source). En termes simples, un lien interne est un lien qui pointe vers une autre page du même site Web.
Exemple de code
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
Format optimal
Utilisez des mots-clés descriptifs dans le texte d’ancrage qui donnent une idée du ou des mots-clés que la page source essaie de cibler.
Qu’est-ce qu’un lien interne ?
Les liens internes sont des liens qui vont d’une page d’un domaine à une autre page du même domaine. Ils sont couramment utilisés dans la navigation principale.
Ces types de liens sont utiles pour trois raisons:
- Ils permettent aux utilisateurs de naviguer sur un site Web.
- Ils aident à établir une hiérarchie d’informations pour le site Web donné.
- Ils aident à diffuser l’équité des liens (pouvoir de classement) autour des sites Web.
Bonnes pratiques SEO
Les liens internes sont les plus utiles pour établir l’architecture du site et diffuser l’équité des liens (les URL sont également essentielles). Pour cette raison, cette section concerne la construction d’une architecture de site conviviale pour le référencement avec des liens internes.
Sur une page individuelle, les moteurs de recherche doivent voir le contenu afin de lister les pages dans leurs index massifs basés sur des mots clés. Ils doivent également avoir accès à une structure de liens explorables — une structure qui permet aux araignées de parcourir les voies d’un site Web — afin de trouver toutes les pages d’un site Web. Des centaines de milliers de sites commettent l’erreur critique de cacher ou d’enterrer leur navigation par lien principal d’une manière à laquelle les moteurs de recherche ne peuvent pas accéder. Cela empêche leur capacité à obtenir des pages répertoriées dans les index des moteurs de recherche. Voici une illustration de la façon dont ce problème peut se produire:
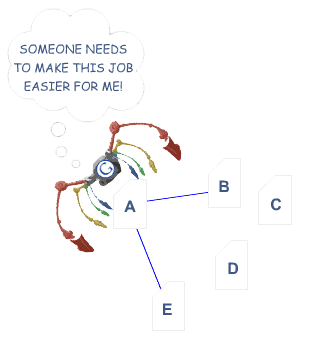
Dans l’exemple ci—dessus, l’araignée colorée de Google a atteint la page « A » et voit des liens internes vers les pages « B » et « E ». Quelles que soient les pages C et D importantes du site, l’araignée n’a aucun moyen de les atteindre — ou même de savoir qu’elles existent – car aucun lien direct et explorable ne pointe vers ces pages. En ce qui concerne Google, ces pages n’existent fondamentalement pas – un excellent contenu, un bon ciblage par mots clés et un marketing intelligent ne font aucune différence si les araignées ne peuvent pas atteindre ces pages en premier lieu.
La structure optimale pour un site Web ressemblerait à une pyramide (où le gros point en haut est la page d’accueil):
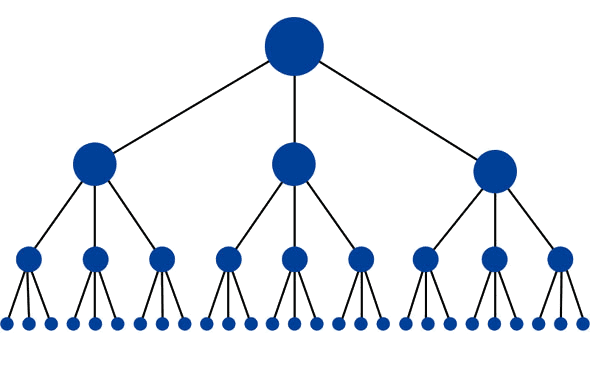
Cette structure a le minimum de liens possibles entre la page d’accueil et une page donnée. Ceci est utile car il permet à l’équité de lien (puissance de classement) de circuler sur l’ensemble du site, augmentant ainsi le potentiel de classement pour chaque page. Cette structure est courante sur de nombreux sites Web très performants (comme Amazon.com ) sous forme de systèmes de catégories et de sous-catégories.
Mais comment cela se fait-il ? La meilleure façon de le faire est d’utiliser des liens internes et des structures d’URL supplémentaires. Par exemple, ils renvoient en interne à une page située à http://www.example.com/mammals… avec le texte d’ancrage « chats. »Voici le format d’un lien interne correctement formaté. Imaginez que ce lien se trouve sur le domaine jonwye.com .

Dans l’illustration ci-dessus, la balise « a » indique le début d’un lien. Les balises de lien peuvent contenir des images, du texte ou d’autres objets, qui fournissent toutes une zone « cliquable » sur la page que les utilisateurs peuvent engager pour passer à une autre page. C’est le concept original d’Internet: « hyperliens. »L’emplacement de référence du lien indique au navigateur — et aux moteurs de recherche — où le lien pointe. Dans cet exemple, l’URL http://www.jonwye.com est référencée. Ensuite, la partie visible du lien pour les visiteurs, appelée « texte d’ancrage » dans le monde du référencement, décrit la page vers laquelle le lien pointe. Dans cet exemple, la page pointée concerne les ceintures personnalisées fabriquées par un homme nommé Jon Wye, de sorte que le lien utilise le texte d’ancrage « Ceintures personnalisées de Jon Wye. » La balise </a> ferme le lien, de sorte que l’attribut link ne leur sera pas appliqué aux éléments ultérieurs de la page.
C’est le format le plus basique d’un lien — et il est éminemment compréhensible pour les moteurs de recherche. Les araignées du moteur de recherche savent qu’elles doivent ajouter ce lien au graphique de liens du moteur du Web, l’utiliser pour calculer des variables indépendantes de la requête (comme MozRank) et le suivre pour indexer le contenu de la page référencée.
Voici quelques raisons courantes pour lesquelles les pages peuvent ne pas être accessibles et, par conséquent, ne pas être indexées.
Liens dans les formulaires de soumission obligatoires
Les formulaires peuvent inclure des éléments aussi basiques qu’un menu déroulant ou des éléments aussi complexes qu’une enquête complète. Dans les deux cas, les araignées de recherche ne tenteront pas de « soumettre » des formulaires et, par conséquent, tout contenu ou lien qui serait accessible via un formulaire est invisible pour les moteurs.
Liens Uniquement Accessibles Via des boîtes de recherche internes
Les araignées ne tenteront pas d’effectuer des recherches pour trouver du contenu, et ainsi, on estime que des millions de pages sont cachées derrière des murs de boîtes de recherche internes complètement inaccessibles.
Liens en Javascript non analysable
Les liens construits à l’aide de Javascript peuvent être soit non déchiffrables, soit dévalués en poids en fonction de leur implémentation. Pour cette raison, il est recommandé d’utiliser des liens HTML standard à la place des liens basés sur Javascript sur toute page où le trafic référencé par les moteurs de recherche est important.
Liens dans Flash, Java ou d’autres Plug-Ins
Tous les liens intégrés dans Flash, les applets Java et d’autres plug-ins sont généralement inaccessibles aux moteurs de recherche.
Liens pointant vers des Pages bloquées par la balise Meta Robots ou des Robots.txt
La balise Meta Robots et les robots.le fichier txt permet à un propriétaire de site de restreindre l’accès de l’araignée à une page.
Liens sur des pages contenant des centaines ou des milliers de liens
Les moteurs de recherche ont tous une limite approximative de 150 liens par page avant de pouvoir arrêter de créer des pages supplémentaires liées à partir de la page d’origine. Cette limite est quelque peu flexible, et les pages particulièrement importantes peuvent avoir plus de 200 voire 250 liens suivis, mais en pratique générale, il est sage de limiter le nombre de liens sur une page donnée à 150 ou de risquer de perdre la possibilité d’avoir des pages supplémentaires explorées.
Liens dans des cadres ou des cadres en I
Techniquement, les liens dans les cadres et les cadres en I sont explorables, mais les deux présentent des problèmes structurels pour les moteurs en termes d’organisation et de suivi. Seuls les utilisateurs avancés ayant une bonne compréhension technique de la façon dont les moteurs de recherche indexent et suivent les liens dans les cadres doivent utiliser ces éléments en combinaison avec des liens internes.
En évitant ces pièges, un webmaster peut avoir des liens HTML propres et invisibles qui permettront aux araignées d’accéder facilement à leurs pages de contenu. Les liens peuvent avoir des attributs supplémentaires qui leur sont appliqués, mais les moteurs ignorent presque tous ces attributs, à l’exception importante de la balise rel="nofollow".
Vous voulez avoir un aperçu rapide de l’indexation de votre site? Utilisez un outil comme Moz Pro, Link Explorer ou Screaming Frog pour lancer une exploration de site. Ensuite, comparez le nombre de pages de l’analyse au nombre de pages répertoriées lorsque vous exécutez un site: recherche sur Google.
Rel= »nofollow » peut être utilisé avec la syntaxe suivante:
<pre > <a href= »/ »rel= »nofollow »>nofollow ce lien </a > </pre>
Dans cet exemple, en ajoutant l’attribut rel="nofollow" à la balise de lien, le webmaster indique aux moteurs de recherche que ils ne veulent pas que ce lien soit interprété comme un passage de jus normal « , vote éditorial. »Nofollow est apparu comme une méthode pour aider à arrêter le spam automatisé de commentaires de blog, de livres d’or et d’injection de liens, mais s’est transformé au fil du temps en un moyen de dire aux moteurs d’actualiser toute valeur de lien qui serait normalement transmise. Les liens marqués avec nofollow sont interprétés légèrement différemment par chacun des moteurs.
Continuez à apprendre
- Texte d’ancrage
- Équité des liens
- Directives pour les webmasters Les Directives officielles de Google pour les Webmasters.
- Liens textuels et PageRank L’ancien responsable de l’équipe Webspam chez Google, Matt Cutts, réfléchit aux liens hypertextes en relation avec le référencement et Google.