Le modèle de Markov caché (HMM) est un modèle de Markov statistique dans lequel le système modélisé est supposé être un processus de Markov avec des états non observés (c’est-à-dire cachés).
Les modèles de Markov cachés sont particulièrement connus pour leur application dans l’apprentissage par renforcement et la reconnaissance de formes temporelles telles que la parole, l’écriture manuscrite, la reconnaissance de gestes, le marquage de parties de discours, le suivi de partitions musicales, les décharges partielles et la bioinformatique.
Terminologie dans HMM
Le terme caché fait référence au processus de Markov du premier ordre derrière l’observation. L’observation fait référence aux données que nous connaissons et pouvons observer. Le processus de Markov est illustré par l’interaction entre « Pluvieux » et « Ensoleillé » dans le diagramme ci-dessous et chacun d’entre eux est un ÉTAT CACHÉ.

Les OBSERVATIONS sont des données connues et font référence à « Marcher », « Magasiner » et « Nettoyer » dans le diagramme ci-dessus. Dans le sens de l’apprentissage automatique, l’observation est nos données d’entraînement, et le nombre d’états cachés est notre hyper paramètre pour notre modèle. L’évaluation du modèle sera discutée plus tard.

T = n’a pas encore d’observation, N = 2, M = 3, Q = {« Pluvieux », « Ensoleillé »}, V = {« Marcher », « Magasiner », « Nettoyer »}
Les probabilités de transition d’état sont les flèches pointant vers chaque état caché. Les matrices de probabilité d’observation sont les flèches bleues et rouges pointant vers chaque observation de chaque état caché. La matrice est une ligne stochastique, ce qui signifie que les lignes totalisent 1.


La matrice explique quelle est la probabilité de passer d’un état à un autre, ou de passer d’un état à une observation.
La distribution d’état initial fait fonctionner le modèle en commençant par un état caché.
Le modèle complet avec les probabilités de transition d’état connues, la matrice de probabilité d’observation et la distribution d’état initiale est marqué comme,
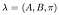
Comment pouvons-nous construire le modèle ci-dessus en Python?
Dans le cas ci-dessus, les émissions sont discrètes {« Walk », « Shop », « Clean »}. MultinomialHMM de la bibliothèque hmmlearn est utilisé pour le modèle ci-dessus. GaussianHMM et GMMHMM sont d’autres modèles de la bibliothèque.
Maintenant, avec le HMM, quels sont les problèmes clés à résoudre?
- Problème 1, Étant donné un modèle connu, quelle est la probabilité que la séquence O se produise?
- Problème 2, Étant donné un modèle et une séquence O connus, quelle est la séquence d’états cachés optimale? Cela sera utile si nous voulons savoir si le temps est « Pluvieux » ou « Ensoleillé »
- Problème 3, Étant donné la séquence O et le nombre d’états cachés, quel est le modèle optimal qui maximise la probabilité de O?
Problème 1 en Python
La probabilité que la première observation soit « Walk » est égale à la multiplication de la matrice de distribution d’état initiale et de probabilité d’émission. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). La probabilité de log est fournie à partir de l’appel.Note.
Problème 2 en Python

Compte tenu du modèle connu et de l’observation {« Shop », « Clean », « Walk »}, le temps était très probablement {« Rainy », « Rainy », « Sunny »} avec une probabilité de ~ 1,5%.
Compte tenu du modèle connu et de l’observation {« Propre », « Propre », « Propre »}, le temps était très probablement {« Pluvieux », « Pluvieux », « Pluvieux »} avec une probabilité d’environ 3,6%.
Intuitivement, lorsque la « marche » se produit, le temps ne sera probablement pas « pluvieux ».
Problème 3 en Python
Reconnaissance vocale avec fichier audio: Prédire ces mots

L’amplitude peut être utilisée comme OBSERVATION pour HMM, mais l’ingénierie des fonctionnalités nous donnera plus de performances.

Fonction stft et peakfind génère une fonction pour le signal audio.
L’exemple ci-dessus a été pris d’ici. Kyle Kastner a construit la classe HMM qui prend des tableaux 3d, j’utilise hmmlearn qui n’autorise que les tableaux 2d. C’est pourquoi je réduit les fonctionnalités générées par Kyle Kastner en tant que X_test.moyenne (axe = 2).
Passer par cette modélisation a pris beaucoup de temps à comprendre. J’ai eu l’impression que la variable cible devait être l’observation. Cela est vrai pour les séries chronologiques. La classification se fait en construisant HMM pour chaque classe et en comparant la sortie en calculant le logprob pour votre entrée.
Solution mathématique au problème 1: Algorithme de transfert

Le passage Alpha est la probabilité d’OBSERVATION et la séquence d’ÉTAT du modèle donné.
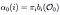
Passage Alpha au temps (t) = 0, distribution d’état initiale à i et de là à la première observation O0.
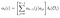
Passe Alpha au temps (t) = t, somme de la dernière passe alpha à chaque état caché multipliée par l’émission à Ot.
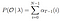
Solution mathématique au problème 2: Algorithme en Arrière


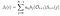

Modèle et observation donnés, probabilité d’être à l’état qi au temps t.
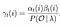
Solution mathématique au problème 3: Algorithme Avant-Arrière


Probabilité de de l’état qi à qj au temps t avec le modèle et l’observation donnés
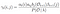
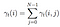
Somme de toutes les probabilités de transition de i à j.
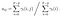
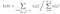
La matrice de probabilité de transition et d’émission est estimée avec du di-gamma.
Itérer si la probabilité pour P (O|modèle) augmente