L’accès mémoire non uniforme (NUMA) est une architecture de mémoire partagée utilisée dans les systèmes multitraitement actuels. Chaque CPU se voit attribuer sa propre mémoire locale et peut accéder à la mémoire à partir d’autres CPU du système. L’accès à la mémoire locale offre une faible latence et des performances de bande passante élevées. Lors de l’accès à la mémoire appartenant à l’autre CPU, la latence est plus élevée et les performances de bande passante sont plus faibles. Les applications et les systèmes d’exploitation modernes tels qu’ESXi prennent en charge NUMA par défaut, mais pour fournir les meilleures performances, la configuration de la machine virtuelle doit être effectuée en tenant compte de l’architecture NUMA. En cas de conception incorrecte, un comportement sans conséquence ou une dégradation globale des performances se produit pour cette machine virtuelle particulière ou, dans le pire des cas, pour toutes les machines virtuelles exécutées sur cet hôte ESXi.
Cette série vise à fournir des informations sur l’architecture CPU, le sous-système de mémoire et le planificateur de CPU et de mémoire ESXi. Vous permettant de créer une plate-forme haute performance qui jette les bases de services plus élevés et de ratios de consolidation accrus. Avant d’arriver aux architectures de calcul modernes, il est utile de passer en revue l’historique des architectures multiprocesseurs à mémoire partagée pour comprendre pourquoi nous utilisons des systèmes NUMA aujourd’hui.
- L’évolution de l’architecture multiprocesseurs à mémoire partagée au cours des dernières décennies
- Introduction des protocoles snoop de mise en cache
- Architecture d’accès mémoire uniforme
- Architecture d’accès mémoire non uniforme
- 1: Organisation d’accès mémoire non uniforme
- 2: Interconnexion point à point
- 3 : Cohérence de cache évolutive
- NUMA activé non entrelacé = SUMA
- Nehalem & Aperçu de la microarchitecture de base
L’évolution de l’architecture multiprocesseurs à mémoire partagée au cours des dernières décennies
Il semble qu’une architecture appelée Accès mémoire uniforme serait mieux adaptée lors de la conception d’une plate-forme cohérente à faible latence et à bande passante élevée. Pourtant, les architectures système modernes l’empêcheront d’être vraiment uniforme. Pour comprendre la raison derrière cela, nous devons remonter dans l’histoire pour identifier les principaux moteurs du calcul parallèle.
Avec l’introduction des bases de données relationnelles au début des années soixante-dix, le besoin de systèmes capables de gérer plusieurs opérations simultanées d’utilisateurs et de générer des données excessives est devenu courant. Malgré le taux impressionnant de performances d’uniprocesseur, les systèmes multiprocesseurs étaient mieux équipés pour gérer cette charge de travail. Afin de fournir un système rentable, l’espace d’adressage de mémoire partagée est devenu le centre de recherche. Au début, les systèmes utilisant un commutateur à barre transversale ont été préconisés, mais avec cette complexité de conception mise à l’échelle avec l’augmentation des processeurs, ce qui a rendu le système basé sur bus plus attrayant. Les processeurs d’un système de bus sont autorisés à accéder à tout l’espace mémoire en envoyant des requêtes sur le bus, un moyen très rentable d’utiliser la mémoire disponible de la manière la plus optimale possible.
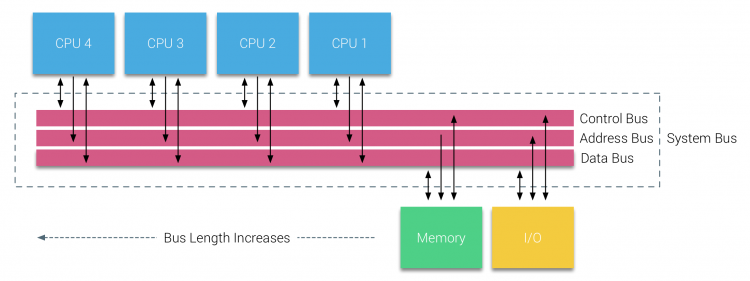
Cependant, les systèmes basés sur bus ont leurs propres problèmes d’évolutivité. Le problème principal est la quantité limitée de bande passante, ce qui limite le nombre de processeurs que le bus peut accueillir. L’ajout de PROCESSEURS au système introduit deux principaux domaines de préoccupation:
- La bande passante disponible par nœud diminue à mesure que chaque CPU est ajouté.
- La longueur du bus augmente lors de l’ajout de processeurs supplémentaires, augmentant ainsi la latence.
La croissance des performances du processeur et en particulier l’écart de vitesse entre le processeur et les performances de la mémoire était, et est toujours, dévastateur pour les multiprocesseurs. Étant donné que l’écart de mémoire entre le processeur et la mémoire devait augmenter, beaucoup d’efforts ont été déployés pour développer des stratégies efficaces de gestion des systèmes de mémoire. L’une de ces stratégies consistait à ajouter un cache mémoire, ce qui présentait une multitude de défis. La résolution de ces défis reste aujourd’hui l’objectif principal des équipes de conception de PROCESSEURS, de nombreuses recherches sont effectuées sur les structures de mise en cache et les algorithmes sophistiqués pour éviter les manques de cache.
Introduction des protocoles snoop de mise en cache
La connexion d’un cache à chaque CPU augmente les performances de plusieurs manières. Rapprocher la mémoire de la CPU réduit le temps d’accès moyen à la mémoire tout en réduisant la charge de bande passante sur le bus mémoire. Le défi avec l’ajout de cache à chaque CPU dans une architecture de mémoire partagée est qu’il permet à plusieurs copies d’un bloc de mémoire d’exister. C’est ce qu’on appelle le problème de cohérence du cache. Pour résoudre ce problème, des protocoles de mise en cache snoop ont été inventés en essayant de créer un modèle fournissant les données correctes tout en n’essayant pas de consommer toute la bande passante du bus. Le protocole le plus populaire, write invalidate, efface toutes les autres copies de données avant d’écrire le cache local. Toute lecture ultérieure de ces données par d’autres processeurs détectera un manque de cache dans leur cache local et sera traitée à partir du cache d’un autre processeur contenant les données les plus récemment modifiées. Ce modèle a économisé beaucoup de bande passante de bus et a permis l’émergence de systèmes d’accès mémoire uniformes au début des années 1990. Les protocoles modernes de cohérence du cache sont traités plus en détail dans la partie 3.
Architecture d’accès mémoire uniforme
Les processeurs de multiprocesseurs basés sur bus qui subissent le même temps d’accès uniforme à n’importe quel module de mémoire du système sont souvent appelés systèmes d’accès mémoire uniforme (ERS) ou Multiprocesseurs Symétriques (SMP).
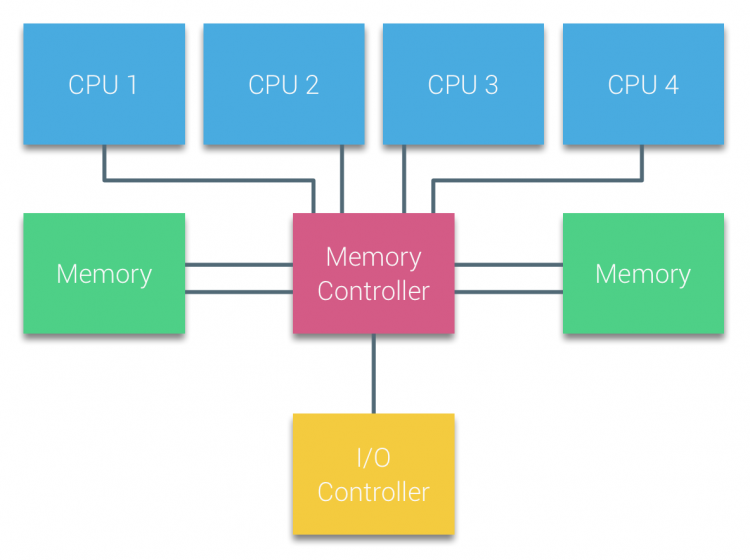
Avec les systèmes UMA, les processeurs sont connectés via un bus système (Bus Frontal) au Northbridge. Le Northbridge contient le contrôleur de mémoire et toutes les communications vers et depuis la mémoire doivent passer par le Northbridge. Le contrôleur d’E/S, responsable de la gestion des E/S vers tous les appareils, est connecté au Northbridge. Par conséquent, chaque E / S doit passer par le Northbridge pour atteindre le processeur.
Plusieurs bus et canaux de mémoire sont utilisés pour doubler la bande passante disponible et réduire le goulot d’étranglement du Northbridge. Pour augmenter encore la bande passante mémoire, certains systèmes ont connecté des contrôleurs de mémoire externes au Northbridge, améliorant ainsi la bande passante et la prise en charge de plus de mémoire. Cependant, en raison de la bande passante interne du Northbridge et de la nature de diffusion des premiers protocoles de cache snoopy, l’ UMA était considéré comme ayant une évolutivité limitée. Avec l’utilisation actuelle de périphériques flash à haute vitesse, poussant des centaines de milliers d’E/ S par seconde, ils avaient absolument raison que cette architecture ne s’adapterait pas aux charges de travail futures.
Architecture d’accès mémoire non uniforme
Pour améliorer l’évolutivité et les performances, trois modifications critiques sont apportées à l’architecture multiprocesseurs à mémoire partagée;
- Organisation d’accès mémoire non uniforme
- Topologie d’interconnexion point à point
- Solutions de cohérence de cache évolutives
1: Organisation d’accès mémoire non uniforme
NUMA s’éloigne d’un pool de mémoire centralisé et introduit des propriétés topologiques. En classant les bases d’emplacement de mémoire sur la longueur du chemin du signal du processeur à la mémoire, les goulots d’étranglement de latence et de bande passante peuvent être évités. Cela se fait en repensant l’ensemble du système de processeur et de chipset. Les architectures NUMA ont gagné en popularité à la fin des années 90 lorsqu’elles ont été utilisées sur des supercalculateurs SGI tels que le Cray Origin 2000. NUMA a aidé à identifier l’emplacement de la mémoire, dans ce cas de ces systèmes, ils ont dû se demander quelle région de mémoire dans quel châssis contenait les bits de mémoire.
Au cours de la première moitié de la décennie du millénaire, AMD a introduit NUMA dans le paysage des entreprises où les systèmes UTE régnaient en maîtres. En 2003, la famille AMD Opteron a été introduite, avec des contrôleurs de mémoire intégrés, chaque processeur possédant des banques de mémoire désignées. Chaque CPU dispose désormais de son propre espace d’adressage mémoire. Un système d’exploitation optimisé NUMA tel qu’ESXi permet à la charge de travail de consommer de la mémoire à partir des deux espaces d’adresses mémoire tout en optimisant l’accès à la mémoire locale. Utilisons un exemple de système à deux processeurs pour clarifier la distinction entre l’accès à la mémoire locale et à distance au sein d’un seul système.
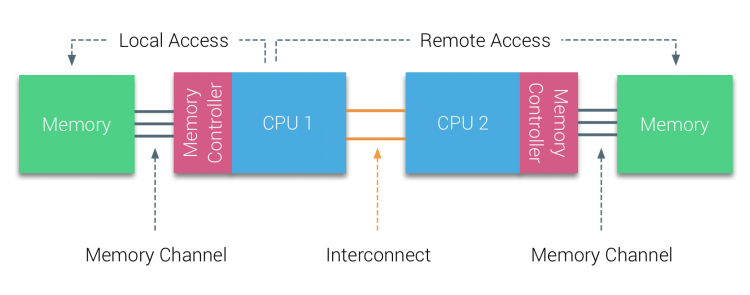
La mémoire connectée au contrôleur de mémoire du CPU1 est considérée comme une mémoire locale. La mémoire connectée à un autre socket CPU (CPU2) est considérée comme étrangère ou distante pour CPU1. L’accès à la mémoire distante a une surcharge de latence supplémentaire par rapport à l’accès à la mémoire locale, car il doit traverser une interconnexion (lien point à point) et se connecter au contrôleur de mémoire distant. En raison des différents emplacements de mémoire, ce système connaît un temps d’accès mémoire « non uniforme ».
2: Interconnexion point à point
AMD a introduit son HyperTransport de connexion point à point avec la microarchitecture AMD Opteron. Intel s’est éloigné de son architecture de bus double indépendant en 2007 en introduisant l’architecture QuickPath dans la conception de sa famille de processeurs Nehalem.
L’architecture Nehalem a été un changement de conception important au sein de la microarchitecture Intel et est considérée comme la première véritable génération de la série Intel Core. L’architecture Broadwell actuelle est la 4ème génération de la marque Intel Core (Intel Xeon E5 v4), le dernier paragraphe contient plus d’informations sur les générations de microarchitecture. Dans l’architecture QuickPath, les contrôleurs de mémoire se sont déplacés vers le processeur et ont introduit l’interconnexion point à point QuickPath (QPI) en tant que liaisons de données entre les PROCESSEURS du système.
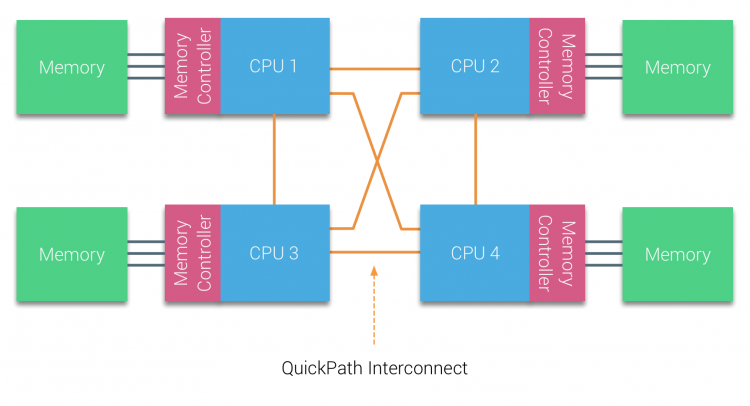
La microarchitecture Nehalem a non seulement remplacé le bus frontal hérité, mais a réorganisé l’ensemble du sous-système en une conception modulaire pour le processeur du serveur. Cette conception modulaire a été introduite sous le nom de « Uncore » et crée une bibliothèque de blocs de construction pour la mise en cache et les vitesses d’interconnexion. La suppression du bus frontal améliore les problèmes d’évolutivité de la bande passante, mais la communication intra et inter-processeurs doit être résolue lorsqu’il s’agit d’énormes quantités de capacité de mémoire et de bande passante. Le contrôleur de mémoire intégré et les interconnexions QuickPath font partie de l’Uncore et sont des registres spécifiques au modèle (MSR)). Ils se connectent à un MSR qui assure la communication intra- et inter-processeur. La modularité de l’Uncore permet également à Intel d’offrir différentes vitesses QPI, au moment de la rédaction de la microarchitecture Intel Broadwell-EP (2016) offre 6,4 Giga-transferts par seconde (GT / s), 8,0 GT / s et 9,6 GT / s. Fournissant respectivement une bande passante maximale théorique de 25,6 GB / s, 32 GB / s et 38,4 GB / s entre les PROCESSEURS. Pour mettre cela en perspective, le dernier bus frontal utilisé fournissait 1,6 GT/ s ou 12,8 GB/ s de bande passante de la plate-forme. Lors de l’introduction de Sandy Bridge, Intel a rebaptisé Uncore en Agent système, mais le terme Uncore est toujours utilisé dans la documentation actuelle. Vous pouvez en savoir plus sur QuickPath et Uncore dans la partie 2.
3 : Cohérence de cache évolutive
Chaque cœur avait un chemin privé vers le cache L3. Chaque chemin était composé de mille fils et vous pouvez imaginer que cela ne s’adapte pas bien si vous voulez diminuer le processus de fabrication du nanomètre tout en augmentant les cœurs qui souhaitent accéder au cache. Afin de pouvoir évoluer, l’architecture Sandy Bridge a déplacé le cache L3 hors de l’Uncore et a introduit l’interconnexion évolutive en anneau. Cela a permis à Intel de partitionner et de distribuer le cache L3 en tranches égales. Cela fournit une bande passante et une associativité plus élevées. Chaque tranche est de 2,5 Mo et une tranche est associée à chaque cœur. L’anneau permet à chaque noyau d’accéder également à toutes les autres tranches. Sur la photo ci-dessous se trouve la configuration de matrice d’un processeur Xeon à faible nombre de cœurs (LCC) de la Microarchitecture Broadwell (v4) (2016).
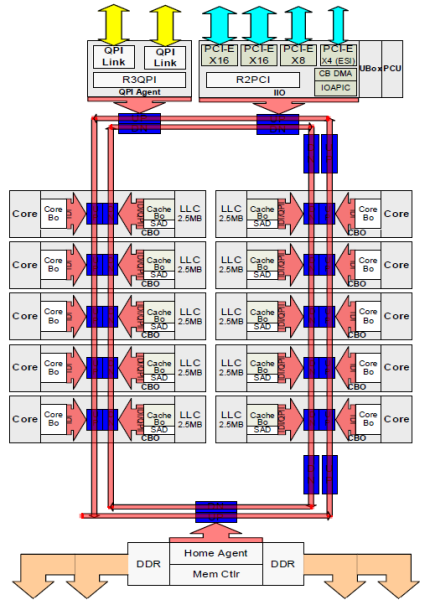
Cette architecture de mise en cache nécessite un protocole de surveillance qui intègre à la fois le cache local distribué et les autres processeurs du système pour assurer la cohérence du cache. Avec l’ajout de plus de cœurs dans le système, la quantité de trafic de snoop augmente, car chaque cœur a son propre flux constant d’échecs de cache. Cela affecte la consommation des liens QPI et des caches de dernier niveau, nécessitant un développement continu des protocoles de cohérence snoop. Une vue en profondeur de l’interconnexion en anneau sur puce évolutive et de l’importance de la mise en cache des protocoles snoop sur les performances NUMA sera incluse dans la partie 3.
NUMA activé non entrelacé = SUMA
La mémoire physique est distribuée sur la carte mère, cependant, le système peut fournir un espace d’adressage mémoire unique en entrelaçant la mémoire entre les deux nœuds NUMA. C’est ce qu’on appelle l’entrelacement des nœuds (le paramètre est couvert dans la partie 2). Lorsque l’entrelacement des nœuds est activé, le système devient une architecture de mémoire suffisamment uniforme (SUMA). Au lieu de relayer les informations de topologie et la nature des processeurs et de la mémoire du système au système d’exploitation, le système décompose toute la plage de mémoire en régions adressables de 4 Ko et les mappe de manière circulaire à partir de chaque nœud. Cela fournit une structure de mémoire « entrelacée » dans laquelle l’espace d’adressage mémoire est réparti sur les nœuds. Lorsque ESXi affecte de la mémoire à une machine virtuelle, il alloue de la mémoire physique située à partir de deux nœuds différents lorsque le processeur physique situé dans le nœud 0 doit récupérer la mémoire du nœud 1, la mémoire traverse les liens QPI.
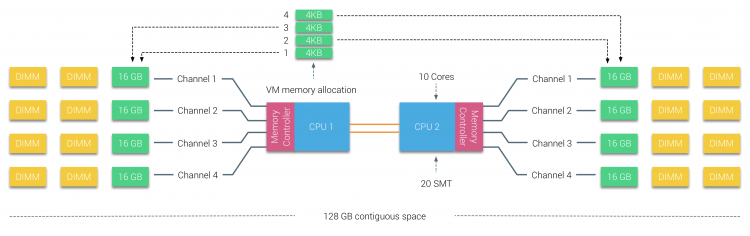
Ce qui est intéressant, c’est que le système SUMA fournit un temps d’accès mémoire uniforme. Seulement, ce n’est pas le plus optimal et dépend fortement des niveaux de conflit dans l’architecture QPI. Le vérificateur de latence de mémoire Intel a été utilisé pour démontrer les différences entre la configuration NUMA et SUMA sur le même système.
Ce test mesure les latences inactives (en nanosecondes) de chaque socket à l’autre socket du système. La latence rapportée du noeud mémoire 0 par le socket 0 est un accès à la mémoire locale, l’accès à la mémoire depuis le socket 0 du noeud mémoire 1 est un accès à la mémoire à distance dans le système configuré en tant que NUMA.
| NUMA | Nœud mémoire 0 | Nœud mémoire 1 | – | SUMA | Nœud de mémoire 0 | Nœud de mémoire 1 |
| Prise 0 | 75.7 | 132.0 | – | Prise 0 | 105.5 | 106.4 |
| Prise 1 | 131.9 | 75.8 | – | Prise 1 | 106.0 | 104.6 |
Comme prévu, l’entrelacement est affecté par la traversée constante des liaisons QPI. Le test de mémoire inactive est le meilleur scénario, un test plus intéressant consiste à mesurer les latences chargées. Cela aurait été un mauvais investissement si vos serveurs ESXi tournent au ralenti, vous pouvez donc supposer qu’un système ESXi traite des données. La mesure des latences chargées fournit un meilleur aperçu des performances du système en charge normale. Pendant le test, les délais d’injection de charge sont automatiquement modifiés toutes les 2 secondes et la bande passante et la latence correspondante sont mesurées à ce niveau. Ce test utilise 100% de trafic de lecture.Résultats du test NUMA à gauche, résultats du test SUMA à droite.
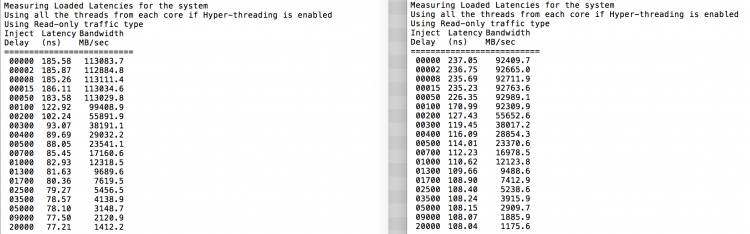
La bande passante signalée pour le système SUMA est inférieure tout en maintenant une latence plus élevée que le système configuré en tant que NUMA. Par conséquent, l’accent devrait être mis sur l’optimisation de la taille de la machine virtuelle pour tirer parti des caractéristiques NUMA du système.
Nehalem & Aperçu de la microarchitecture de base
Avec l’introduction de la microarchitecture Nehalem en 2008, Intel s’est éloigné de l’architecture Netburst. La microarchitecture Nehalem a introduit les clients Intel à NUMA. Au fil des années, Intel a introduit de nouvelles microarchitectures et optimisations, selon son célèbre modèle Tic-Tac. À chaque Tick, une optimisation a lieu, réduisant la technologie de processus et à chaque Tick, une nouvelle microarchitecture est introduite. Même si Intel fournit un modèle de marque cohérent depuis 2012, les gens ont tendance à utiliser les noms de code de l’architecture Intel pour discuter des générations de TIC-tac du processeur. Même les lignes de base EVC répertorient ces noms de code Intel internes, les noms de marque et les noms de code d’architecture seront utilisés tout au long de cette série:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Tick | 14 nm |
Ensuite, Partie 2: Architecture Système
La série NUMA Deep Dive 2016:
Partie 0: Introduction Série NUMA Deep Dive
Partie 1: De UMA à NUMA
Partie 2: Architecture Système
Partie 3: Cohérence du cache
Partie 4: Optimisation de la mémoire locale
Partie 5: Constructions NUMA ESXi VMkernel