La régression par morceaux est un type particulier de régression linéaire qui survient lorsqu’une seule ligne n’est pas suffisante pour modéliser un ensemble de données. La régression par morceaux divise le domaine en potentiellement plusieurs « segments » et correspond à une ligne distincte à travers chacun d’eux. Par exemple, dans les graphiques ci-dessous, une seule ligne n’est pas en mesure de modéliser les données ainsi qu’une régression par morceaux avec trois lignes:
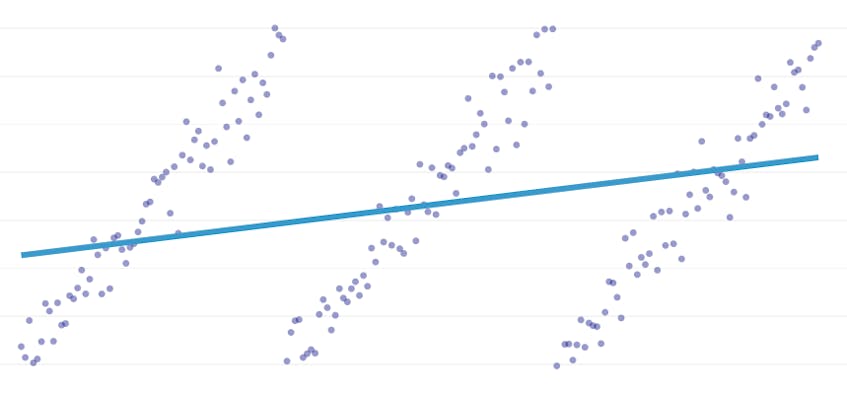
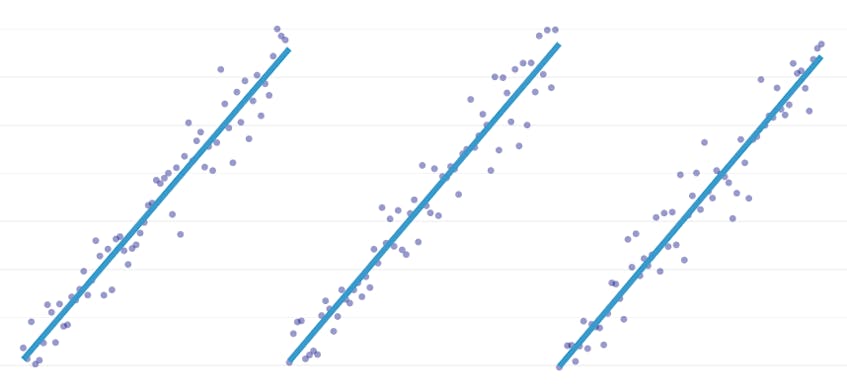
Cet article présente l’approche de Datadog pour automatiser la régression par morceaux sur des données de séries chronologiques.
Objectifs
La régression par morceaux peut signifier des choses légèrement différentes dans différents contextes, alors prenons une minute pour clarifier ce que nous essayons exactement de réaliser avec notre algorithme de régression par morceaux.
Détection automatisée des points d’arrêt. Dans la littérature statistique classique, la régression par morceaux est souvent suggérée lors des travaux d’analyse de régression manuelle, où il est évident à l’œil nu qu’une tendance linéaire cède la place à une autre. Dans ce cas, un humain peut spécifier le point d’arrêt entre les segments par morceaux, diviser l’ensemble de données et effectuer une régression linéaire sur chaque segment indépendamment. Dans nos cas d’utilisation, nous voulons faire des centaines de régressions par seconde, et il n’est pas possible qu’un humain spécifie tous les points d’arrêt. Au lieu de cela, nous avons l’exigence que notre algorithme de régression par morceaux identifie ses propres points d’arrêt.
Détection automatisée du nombre de segments. Si nous savions qu’un ensemble de données comporte exactement deux segments, nous pourrions facilement examiner chacune des paires possibles de segments. Cependant, dans la pratique, lorsqu’on lui attribue une série chronologique arbitraire, il n’y a aucune raison de croire qu’il doit y avoir plus d’un segment ou moins de 3, 4 ou 5. Notre algorithme doit choisir un nombre approprié de segments sans qu’il soit spécifié par l’utilisateur.
Aucune exigence de continuité. Certaines méthodes de régressions par morceaux génèrent des segments connectés, où le point final de chaque segment est le point de départ du segment suivant. Nous n’imposons aucune telle exigence à notre algorithme.
Défis
Le défi le plus évident pour la mise en œuvre d’une régression par morceaux avec détection automatisée des points d’arrêt est la grande taille de l’espace de recherche de solutions; une recherche par force brute de tous les segments possibles est d’un coût prohibitif. Le nombre de façons dont une série temporelle peut être divisée en segments est exponentiel dans la longueur de la série temporelle. Bien que la programmation dynamique puisse être utilisée pour parcourir cet espace de recherche beaucoup plus efficacement qu’une implémentation naïve à force brute, elle est encore trop lente dans la pratique. Une heuristique gourmande sera nécessaire pour éliminer rapidement de grandes zones de l’espace de recherche.
Un défi plus subtil est que nous avons besoin d’un moyen de comparer la qualité d’une solution à une autre. Pour notre version du problème, avec des nombres et des emplacements inconnus de segments, nous devons comparer les solutions potentielles avec différents nombres de segments et différents points d’arrêt. Nous nous trouvons en train d’essayer d’équilibrer deux objectifs concurrents:
- Minimisez les erreurs. Autrement dit, rapprochez la droite de régression de chaque segment des points de données observés.
- Utilisez le plus petit nombre de segments qui modélisent bien les données. Nous pourrions toujours obtenir zéro erreur en créant un seul segment pour chaque point (ou même un segment pour deux points). Pourtant, cela annulerait tout l’intérêt de faire une régression; nous n’apprendrions rien sur la relation générale entre un horodatage et sa valeur métrique associée, et nous ne pourrions pas facilement utiliser le résultat pour l’interpolation ou l’extrapolation.
Notre solution
Nous utilisons l’algorithme gourmand suivant pour le problème de régression par morceaux:
- Faites une régression par morceaux avec n/2 segments, où n est le nombre d’observations dans la série chronologique. La droite de régression dans chaque segment est ajustée en utilisant la régression des moindres carrés ordinaires (OLS). Cette régression initiale par morceaux n’aura pratiquement aucune erreur, mais elle surajustera considérablement l’ensemble de données.
- De manière itérative, jusqu’à ce qu’il n’y ait qu’un seul segment :
- Pour toutes les paires de segments voisins, évaluez l’augmentation de l’erreur totale qui résulterait si les deux segments étaient combinés, leurs deux lignes de régression étant remplacées par une seule ligne de régression.
- Fusionnez la paire de segments qui entraînerait la plus petite augmentation d’erreur.
- Si l’exécution de cette fusion répond à nos critères d’arrêt (définis ci-dessous), nous serions peut-être allés trop loin en fusionnant deux segments qui devraient rester séparés. Si tel est le cas, rappelez-vous l’état des segments avant la fusion de cette itération.
- Si aucune fusion n’a entraîné la mémorisation de l’état des segments dans (2c) ci-dessus, la meilleure solution est un grand segment. Sinon, le dernier état de segment à mémoriser dans (2c) est la meilleure solution.
Critères d’arrêt
Nous considérons une fusion comme un point d’arrêt potentiel si elle augmente la somme totale des erreurs au carré de plus que toute fusion précédente. Pour éviter de s’arrêter trop tôt dans les cas où il ne devrait y avoir qu’un seul segment, nous ne considérerons pas une fusion comme un point d’arrêt potentiel à moins qu’elle n’entraîne une augmentation de l’erreur totale inférieure à 3% de l’erreur totale d’une régression avec un segment. (Les 3% sont un seuil arbitraire, mais nous avons constaté qu’il fonctionnait bien dans la pratique.) Voici quelques exemples pour démontrer pourquoi ce critère d’arrêt fonctionne.
Tout d’abord, regardons un ensemble de données qui a été généré en ajoutant du bruit normalement distribué aux points le long d’une seule ligne. L’algorithme ne correspond correctement qu’à un seul segment de cet ensemble de données.
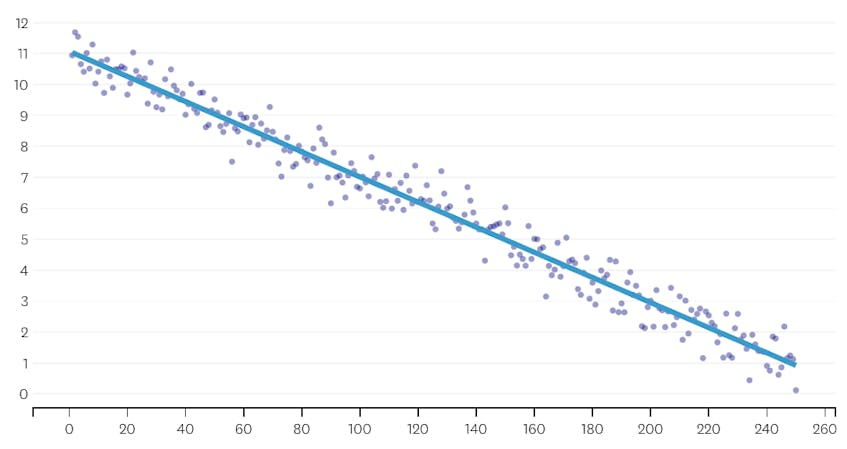
Dans ce cas, aucune fusion n’augmente jamais la somme totale des erreurs au carré de plus de 3%. Par conséquent, aucune fusion n’est considérée comme un point d’arrêt adéquat et nous utilisons l’état final une fois toutes les fusions exécutées. Dans le graphique ci-dessous, nous voyons que les fusions ultérieures ont tendance à introduire plus d’erreurs que les précédentes (ce qui est logique car elles ont chacune un impact sur plus de points), mais l’augmentation de l’erreur n’augmente que progressivement à mesure que plus de segments sont fusionnés.
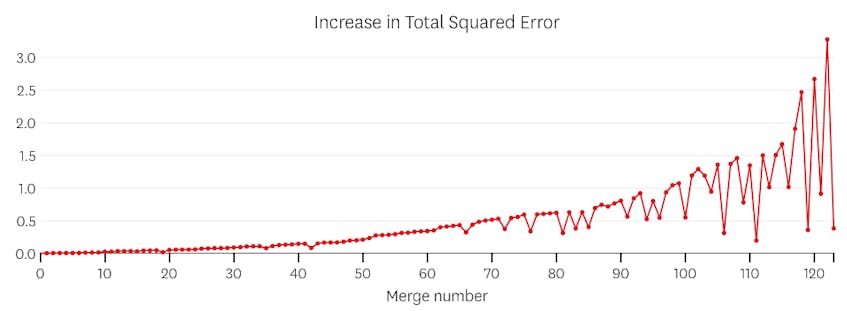
Deuxièmement, regardons un exemple où il y a sept segments distincts dans l’ensemble de données.
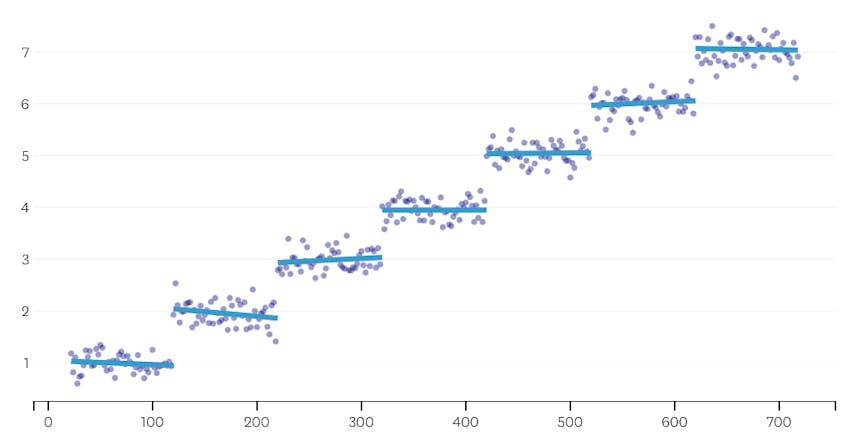
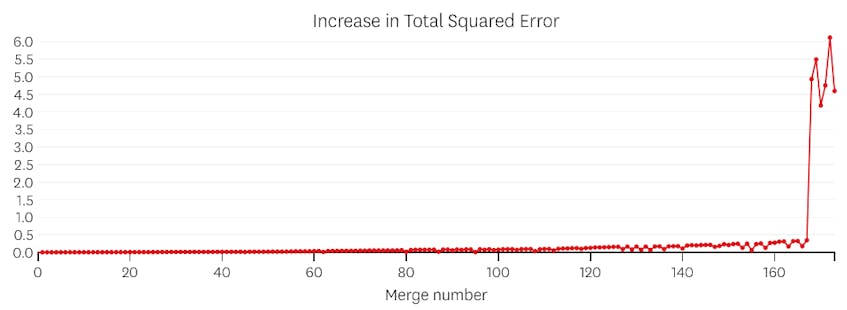
Dans ce cas, lorsque nous examinons le tracé des erreurs introduites par chaque fusion, nous voyons que les six dernières fusions ont introduit beaucoup plus d’erreurs que n’importe laquelle des fusions précédentes. Par conséquent, notre algorithme s’est souvenu de l’état des segments avant la 6e à la dernière fusion et l’a utilisé comme solution finale.
Le code
Dans le dépôt Github Datadog/par morceaux, vous trouverez notre implémentation Python de l’algorithme. La fonction piecewise() est l’endroit où se produit le levage de charges lourdes; étant donné un ensemble de données, elle renverra les coefficients de localisation et de régression pour chacun des segments ajustés.
Également inclus dans l’essentiel est plot_data_with_regression() – une fonction d’emballage pour un traçage rapide et facile. Un exemple rapide de la façon dont cela pourrait être utilisé:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)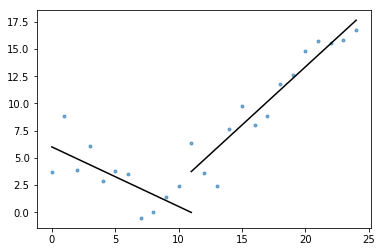
Bien que cette implémentation utilise la régression linéaire OLS, le même cadre peut être adapté pour résoudre les problèmes connexes. En remplaçant l’erreur au carré par une erreur absolue ou une perte de Huber, la régression peut être rendue robuste. Ou bien, une fonction pas à pas peut être adaptée en attribuant à chaque segment une valeur constante égale à la moyenne des observations dans son domaine.