Dans ce tutoriel, nous allons expliquer l’une des techniques d’intégration de mots émergentes et importantes appelées Word2Vec proposées par Mikolov et al. en 2013. Nous avons rassemblé ces contenus à partir de différents tutoriels et sources pour faciliter les lecteurs en un seul endroit. J’espère que ça va aider.
Word2vec est une combinaison de modèles utilisés pour représenter des représentations distribuées de mots dans un corpus C. Word2Vec (W2V) est un algorithme qui accepte le corpus de texte en entrée et génère une représentation vectorielle pour chaque mot, comme indiqué dans le diagramme ci-dessous:

Il existe deux saveurs de cet algorithme à savoir: CBOW et Skip-Gram. Étant donné un ensemble de phrases (également appelé corpus), le modèle boucle sur les mots de chaque phrase et tente soit d’utiliser le mot courant w afin de prédire ses voisins (c’est-à-dire son contexte), cette approche est appelée « Saut-Gramme », soit elle utilise chacun de ces contextes pour prédire le mot courant w, dans ce cas la méthode est appelée « Sac continu de mots » (CBOW). Pour limiter le nombre de mots dans chaque contexte, un paramètre appelé « taille de la fenêtre » est utilisé.

Les vecteurs que nous utilisons pour représenter les mots sont appelés intégrations de mots neuronaux, et les représentations sont étranges. Une chose en décrit une autre, même si ces deux choses sont radicalement différentes. Comme l’a dit Elvis Costello: « Écrire sur la musique, c’est comme danser sur l’architecture. »Word2vec »vectorise » les mots et, ce faisant, rend le langage naturel lisible par ordinateur — nous pouvons commencer à effectuer de puissantes opérations mathématiques sur les mots pour détecter leurs similitudes.
Ainsi, un incorporation de mot neuronal représente un mot avec des nombres. C’est une traduction simple, mais peu probable. Word2vec est similaire à un autoencodeur, codant chaque mot dans un vecteur, mais plutôt que de s’entraîner contre les mots d’entrée par reconstruction, comme le fait une machine de Boltzmann restreinte, word2vec entraîne les mots contre d’autres mots qui les voisinent dans le corpus d’entrée.
Il le fait de deux manières, soit en utilisant le contexte pour prédire un mot cible (une méthode connue sous le nom de sac continu de mots, ou CBOW), soit en utilisant un mot pour prédire un contexte cible, appelé skip-gram. Nous utilisons cette dernière méthode car elle produit des résultats plus précis sur de grands ensembles de données.

Lorsque le vecteur caractéristique attribué à un mot ne peut pas être utilisé pour prédire avec précision le contexte de ce mot, les composantes du vecteur sont ajustées. Le contexte de chaque mot dans le corpus est l’enseignant renvoyant des signaux d’erreur pour ajuster le vecteur d’entités. Les vecteurs de mots jugés similaires par leur contexte sont rapprochés en ajustant les nombres dans le vecteur. Dans ce tutoriel, nous allons nous concentrer sur le modèle de saut de gramme qui, contrairement à CBOW, considère le mot central comme entrée comme indiqué dans la figure ci-dessus et prédit les mots de contexte.
Aperçu du modèle
Nous avons compris que nous devons alimenter un réseau de neurones étrange avec des paires de mots, mais nous ne pouvons pas simplement le faire en utilisant comme entrées les caractères réels, nous devons trouver un moyen de représenter ces mots mathématiquement afin que le réseau puisse les traiter. Une façon de le faire est de créer un vocabulaire de tous les mots de notre texte, puis de coder notre mot comme vecteur des mêmes dimensions de notre vocabulaire. Chaque dimension peut être pensée comme un mot dans notre vocabulaire. Nous aurons donc un vecteur avec tous les zéros et un 1 qui représente le mot correspondant dans le vocabulaire. Cette technique de codage est appelée codage à chaud. Considérant notre exemple, si nous avons un vocabulaire composé des mots « le », « rapide », « brun », « renard », « saute », « au-dessus », « le » « paresseux », « chien », le mot « brun » est représenté par ce vecteur:.

Le modèle de saut de gramme prend un corpus de texte et crée un vecteur à chaud pour chaque mot. Un vecteur chaud est une représentation vectorielle d’un mot où le vecteur est la taille du vocabulaire (total des mots uniques). Toutes les dimensions sont définies sur 0, à l’exception de la dimension représentant le mot utilisé comme entrée à ce moment-là. Voici un exemple de vecteur chaud:

L’entrée ci-dessus est donnée à un réseau de neurones avec une seule couche cachée.
Nous allons représenter un mot d’entrée comme « fourmis » comme un vecteur à chaud. Ce vecteur aura 10 000 composants (un pour chaque mot de notre vocabulaire) et nous placerons un « 1 » dans la position correspondant au mot « fourmis », et des 0 dans toutes les autres positions. La sortie du réseau est un vecteur unique (également avec 10 000 composants) contenant, pour chaque mot de notre vocabulaire, la probabilité qu’un mot voisin sélectionné au hasard soit ce mot de vocabulaire.
Dans word2vec, une représentation distribuée d’un mot est utilisée. Prenez un vecteur de plusieurs centaines de dimensions (disons 1000). Chaque mot est représenté par une distribution de poids entre ces éléments. Ainsi, au lieu d’un mappage un à un entre un élément du vecteur et un mot, la représentation d’un mot est répartie sur tous les éléments du vecteur, et chaque élément du vecteur contribue à la définition de nombreux mots.
Si j’étiquette les dimensions dans un vecteur de mots hypothétique (il n’y a pas de telles étiquettes pré-attribuées dans l’algorithme bien sûr), cela pourrait ressembler un peu à ceci:

Un tel vecteur en vient à représenter de manière abstraite le « sens » d’un mot. Et comme nous le verrons plus loin, en examinant simplement un grand corpus, il est possible d’apprendre des vecteurs de mots capables de capturer les relations entre les mots d’une manière étonnamment expressive. Nous pouvons également utiliser les vecteurs comme entrées dans un réseau de neurones. Puisque nos vecteurs d’entrée sont à chaud, multiplier un vecteur d’entrée par la matrice de poids W1 revient simplement à sélectionner une ligne à partir de W1.
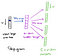

De la couche cachée à la couche de sortie, la deuxième matrice de poids W2 peut être utilisée pour calculer un score pour chaque mot du vocabulaire, et softmax peut être utilisé pour obtenir la distribution postérieure des mots. Le modèle skip-gram est le contraire du modèle CBOW. Il est construit avec le mot focus comme vecteur d’entrée unique, et les mots de contexte cible sont maintenant dans la couche de sortie. La fonction d’activation de la couche cachée revient simplement à copier la ligne correspondante de la matrice de poids W1 (linéaire) comme nous l’avons vu précédemment. Au niveau de la couche de sortie, nous produisons maintenant des distributions multinomiales C au lieu d’une seule. L’objectif de la formation est d’imiter l’erreur de prédiction additionnée sur tous les mots de contexte de la couche de sortie. Dans notre exemple, l’entrée serait « learning », et nous espérons voir (« an », « efficient », « method », « for », « high », « quality », « distributed », « vector ») à la couche de sortie.
Voici l’architecture de notre réseau de neurones.

Pour notre exemple, nous allons dire que nous apprenons des vecteurs de mots avec 300 fonctionnalités. La couche cachée va donc être représentée par une matrice de poids avec 10 000 lignes (une pour chaque mot de notre vocabulaire) et 300 colonnes (une pour chaque neurone caché). 300 fonctionnalités est ce que Google a utilisé dans son modèle publié formé sur l’ensemble de données Google news (vous pouvez le télécharger ici). Le nombre de fonctionnalités est un « hyper paramètre » que vous n’auriez qu’à ajuster à votre application (c’est-à-dire essayer différentes valeurs et voir ce qui donne les meilleurs résultats).
Si vous regardez les lignes de cette matrice de poids, ce sont ce que seront nos vecteurs de mots!

Donc, le but final de tout cela est vraiment juste d’apprendre cette matrice de poids de couche cachée — la couche de sortie que nous allons simplement lancer lorsque nous aurons terminé! Le vecteur de mots 1 x 300 pour « fourmis » est ensuite introduit dans la couche de sortie. La couche de sortie est un classificateur de régression softmax. En effet, chaque neurone de sortie possède un vecteur poids qu’il multiplie par rapport au vecteur mot de la couche cachée, puis il applique la fonction exp(x) au résultat. Enfin, pour que les sorties se résument à 1, nous divisons ce résultat par la somme des résultats des 10 000 nœuds de sortie. Voici une illustration du calcul de la sortie du neurone de sortie pour le mot « voiture ».

Si deux mots différents ont des « contextes » très similaires (c’est-à-dire quels mots sont susceptibles d’apparaître autour d’eux), notre modèle doit produire des résultats très similaires pour ces deux mots. Et une façon pour le réseau de produire des prédictions de contexte similaires pour ces deux mots est si les vecteurs de mots sont similaires. Donc, si deux mots ont des contextes similaires, alors notre réseau est motivé pour apprendre des vecteurs de mots similaires pour ces deux mots! Ta fille!
Chaque dimension de l’entrée passe par chaque nœud de la couche cachée. La dimension est multipliée par le poids qui la conduit à la couche cachée. Comme l’entrée est un vecteur chaud, un seul des nœuds d’entrée aura une valeur non nulle (à savoir la valeur de 1). Cela signifie que pour un mot, seuls les poids associés au nœud d’entrée de valeur 1 seront activés, comme indiqué dans l’image ci-dessus.
Comme l’entrée dans ce cas est un vecteur chaud, un seul des nœuds d’entrée aura une valeur non nulle. Cela signifie que seuls les poids connectés à ce nœud d’entrée seront activés dans les nœuds cachés. Un exemple des poids qui seront considérés est représenté ci-dessous pour le deuxième mot du vocabulaire:
La représentation vectorielle du deuxième mot du vocabulaire (montrée dans le réseau de neurones ci-dessus) se présentera comme suit, une fois activée dans la couche cachée:
Ces poids commencent par des valeurs aléatoires. Le réseau est ensuite entraîné afin d’ajuster les poids pour représenter les mots d’entrée. C’est là que la couche de sortie devient importante. Maintenant que nous sommes dans la couche cachée avec une représentation vectorielle du mot, nous avons besoin d’un moyen de déterminer dans quelle mesure nous avons prédit qu’un mot s’intégrera dans un contexte particulier. Le contexte du mot est un ensemble de mots dans une fenêtre qui l’entoure, comme indiqué ci-dessous:

L’image ci-dessus montre que le contexte du vendredi comprend des mots comme « chat » et « est ». Le but du réseau de neurones est de prédire que le « vendredi » s’inscrit dans ce contexte.
Nous activons la couche de sortie en multipliant le vecteur que nous avons traversé la couche cachée (qui était le vecteur chaud d’entrée * poids entrant dans le nœud caché) avec une représentation vectorielle du mot de contexte (qui est le vecteur chaud pour le mot de contexte * poids entrant dans le nœud de sortie). L’état de la couche de sortie pour le premier mot de contexte peut être visualisé ci-dessous:

La multiplication ci-dessus est effectuée pour chaque paire de mots à mots contextuels. Nous calculons ensuite la probabilité qu’un mot appartienne à un ensemble de mots de contexte en utilisant les valeurs résultant des couches masquées et de sortie. Enfin, nous appliquons la descente de gradient stochastique pour modifier les valeurs des poids afin d’obtenir une valeur plus souhaitable pour la probabilité calculée.
En descente de gradient, nous devons calculer le gradient de la fonction optimisée au point représentant le poids que nous changeons. Le gradient est ensuite utilisé pour choisir la direction dans laquelle faire un pas vers l’optimum local, comme le montre l’exemple de minimisation ci-dessous.
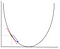
Le poids sera modifié en faisant un pas dans la direction du point optimal (dans l’exemple ci-dessus, le point le plus bas du graphique). La nouvelle valeur est calculée en soustrayant de la valeur de poids actuelle la fonction dérivée au point du poids mis à l’échelle par le taux d’apprentissage. L’étape suivante consiste à utiliser la rétropropagation, pour ajuster les poids entre plusieurs couches. L’erreur calculée à la fin de la couche de sortie est renvoyée de la couche de sortie à la couche masquée en appliquant la règle de chaîne. La descente de gradient est utilisée pour mettre à jour les poids entre ces deux couches. L’erreur est ensuite ajustée à chaque couche et renvoyée plus loin. Voici un diagramme pour représenter la rétropropagation:

Compréhension à l’aide de l’exemple
Word2vec utilise une seule couche cachée, un réseau de neurones entièrement connecté, comme indiqué ci-dessous. Les neurones de la couche cachée sont tous des neurones linéaires. La couche d’entrée est configurée pour avoir autant de neurones qu’il y a de mots dans le vocabulaire pour l’entraînement. La taille du calque masqué est définie sur la dimensionnalité des vecteurs de mots résultants. La taille de la couche de sortie est la même que celle de la couche d’entrée. Ainsi, si le vocabulaire d’apprentissage des vecteurs de mots est constitué de V mots et N étant la dimension des vecteurs de mots, l’entrée des connexions de couches cachées peut être représentée par une matrice WI de taille VxN, chaque ligne représentant un mot de vocabulaire. De la même manière, les connexions de couche cachée à couche de sortie peuvent être décrites par une matrice WO de taille NxV. Dans ce cas, chaque colonne de la matrice WO représente un mot du vocabulaire donné.

L’entrée du réseau est codée à l’aide de la représentation « 1 sur V », ce qui signifie qu’une seule ligne d’entrée est définie sur un et que le reste des lignes d’entrée est défini sur zéro.
Supposons que nous ayons un corpus d’entraînement comportant les phrases suivantes:
« le chien a vu un chat », « le chien a chassé le chat », « le chat a grimpé dans un arbre »
Le vocabulaire du corpus comporte huit mots. Une fois classés par ordre alphabétique, chaque mot peut être référencé par son index. Pour cet exemple, notre réseau de neurones aura huit neurones d’entrée et huit neurones de sortie. Supposons que nous décidions d’utiliser trois neurones dans la couche cachée. Cela signifie que WI et WO seront respectivement des matrices 8×3 et 3×8. Avant le début de l’entraînement, ces matrices sont initialisées à de petites valeurs aléatoires comme d’habitude dans l’entraînement en réseau de neurones. Juste pour l’illustration, supposons que WI et WO soient initialisés aux valeurs suivantes:

Supposons que nous souhaitions que le réseau apprenne la relation entre les mots « chat » et « grimpé ». Autrement dit, le réseau devrait montrer une forte probabilité de « grimper » lorsque « cat » est entré dans le réseau. Dans la terminologie d’intégration de mots, le mot « chat » est appelé mot de contexte et le mot « grimpé » est appelé mot cible. Dans ce cas, le vecteur d’entrée X sera t. Notez que seule la deuxième composante du vecteur est 1. En effet, le mot d’entrée est « cat » qui occupe la deuxième position dans la liste triée des mots du corpus. Étant donné que le mot cible est « grimpé », le vecteur cible ressemblera à t. Avec le vecteur d’entrée représentant « cat », la sortie au niveau des neurones de la couche cachée peut être calculée comme suit:
Ht = XtWI=
Il ne faut pas nous surprendre que le vecteur H des sorties de neurones cachés imite les poids de la deuxième rangée de matrice WI en raison de la représentation 1 hors V. Ainsi, la fonction de l’entrée dans les connexions de couche masquées est essentiellement de copier le vecteur de mot d’entrée dans la couche masquée. En effectuant des manipulations similaires pour la couche cachée à la couche de sortie, le vecteur d’activation des neurones de la couche de sortie peut être écrit comme
HtWO =
Étant donné que le but est de produire des probabilités pour les mots de la couche de sortie, Pr (wordk | wordcontext) pour k = 1, V, pour refléter leur relation de mot suivant avec le mot de contexte en entrée, nous avons besoin de la somme des sorties de neurones dans la couche de sortie pour en ajouter une. Word2vec y parvient en convertissant les valeurs d’activation des neurones de la couche de sortie en probabilités à l’aide de la fonction softmax. Ainsi, la sortie du k-th neurone est calculée par l’expression suivante où l’activation (n) représente la valeur d’activation du n-th neurone de couche de sortie:
Ainsi, les probabilités pour huit mots dans le corpus sont:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
La probabilité en gras correspond au mot cible choisi « grimpé ». Étant donné le vecteur cible t, le vecteur d’erreur de la couche de sortie est facilement calculé en soustrayant le vecteur de probabilité du vecteur cible. Une fois l’erreur connue, les poids des matrices WO et WI peuvent être mis à jour par rétropropagation. Ainsi, la formation peut se poursuivre en présentant différentes paires de mots contexte-cible du corpus. C’est ainsi que Word2vec apprend les relations entre les mots et développe dans le processus des représentations vectorielles pour les mots du corpus.
L’idée derrière word2vec est de représenter les mots par un vecteur de nombres réels de dimension d. Par conséquent, la deuxième matrice est la représentation de ces mots. La i- line ligne de cette matrice est la représentation vectorielle du i-th mot. Disons que dans votre exemple, vous avez 5 mots:, alors le premier vecteur signifie que vous considérez le mot « Cheval » et donc la représentation de « Cheval » est. De même, est la représentation du mot « Lion ».

À ma connaissance, il n’y a pas de « signification humaine » spécifiquement à chacun des nombres dans ces représentations. Un nombre ne représente pas si le mot est un verbe ou non, un adjectif ou non… Ce sont juste les poids que vous modifiez pour résoudre votre problème d’optimisation pour apprendre la représentation de vos mots.
Un diagramme visuel qui élabore le mieux le processus de multiplication matricielle word2vec est représenté dans la figure suivante:

La première matrice représente le vecteur d’entrée dans un format chaud. La deuxième matrice représente les poids synaptiques des neurones de la couche d’entrée aux neurones de la couche cachée. Remarquez en particulier le coin supérieur gauche où la matrice de couche d’entrée est multipliée par la matrice de poids. Maintenant, regardez en haut à droite. Cette couche d’entrée de multiplication matricielle produite avec Transposition de poids est juste un moyen pratique de représenter le réseau de neurones en haut à droite.
La première partie représente le mot d’entrée sous la forme d’un vecteur chaud et l’autre matrice représente le poids pour la connexion de chacun des neurones de la couche d’entrée aux neurones de la couche cachée. À mesure que Word2Vec s’entraîne, il rétropropagate (en utilisant la descente de gradient) ces poids et les modifie pour donner de meilleures représentations des mots en tant que vecteurs. Une fois l’entraînement terminé, vous n’utilisez que cette matrice de poids, prenez par exemple « chien » et multipliez-la avec la matrice de poids améliorée pour obtenir la représentation vectorielle de « chien » dans une dimension = non de neurones de couche cachés. Dans le diagramme, le nombre de neurones de couche cachés est de 3.
En un mot, le modèle Skip-gram inverse l’utilisation des mots cibles et contextuels. Dans ce cas, le mot cible est alimenté en entrée, la couche cachée reste la même et la couche de sortie du réseau de neurones est répliquée plusieurs fois pour accueillir le nombre de mots de contexte choisi. En prenant l’exemple de « cat » et « tree » comme mots de contexte et « climbed » comme mot cible, le vecteur d’entrée dans le modèle écrémé-gramme serait t, tandis que les deux couches de sortie auraient respectivement t et t comme vecteurs cibles. Au lieu de produire un vecteur de probabilités, deux de ces vecteurs seraient produits pour l’exemple actuel. Le vecteur d’erreur pour chaque couche de sortie est produit de la manière décrite ci-dessus. Cependant, les vecteurs d’erreur de toutes les couches de sortie sont additionnés pour ajuster les poids via une rétropropagation. Cela garantit que la matrice de poids WO pour chaque couche de sortie reste identique tout au long de l’entraînement.
Nous avons besoin de quelques modifications supplémentaires au modèle de saut-gramme de base qui sont importantes pour rendre possible l’entraînement. L’exécution de la descente de gradient sur un réseau de neurones aussi important va être lente. Et pour aggraver les choses, vous avez besoin d’une énorme quantité de données d’entraînement pour ajuster autant de poids et éviter de trop ajuster. des millions de poids fois des milliards d’échantillons d’entraînement signifie que l’entraînement de ce modèle va être une bête. Pour cela, les auteurs ont proposé deux techniques appelées sous-échantillonnage et échantillonnage négatif dans lesquelles les mots insignifiants sont supprimés et seul un échantillon spécifique de poids est mis à jour.
Mikolov et coll. utilisez également une approche de sous-échantillonnage simple pour contrer le déséquilibre entre les mots rares et fréquents dans l’ensemble d’entraînement (par exemple, « in », « the » et « a » fournissent moins de valeur d’information que les mots rares). Chaque mot de l’ensemble d’entraînement est rejeté avec une probabilité P (wi) où

f(wi) est la fréquence du mot wi et t est un seuil choisi, typiquement autour de 10-5.
Détails d’implémentation
Word2vec a été implémenté dans différents langages mais nous nous concentrerons ici particulièrement sur Java, c’est-à-dire, DeepLearning4j, darks-learning et python. Divers algorithmes de réseaux neuronaux ont été implémentés dans DL4j, le code est disponible sur GitHub.
Pour l’implémenter dans DL4j, nous passerons par quelques étapes données comme suit:
a) Word2Vec Setup
Créer un nouveau projet dans IntelliJ en utilisant Maven. Spécifiez ensuite les propriétés et les dépendances dans le POM.fichier xml dans le répertoire racine de votre projet.
b) Chargez les données
Créez et nommez maintenant une nouvelle classe en Java. Après cela, vous prendrez les phrases brutes dans votre.fichier txt, parcourez-les avec votre itérateur et soumettez-les à une sorte de prétraitement, comme la conversion de tous les mots en minuscules.
Chemin de fichier de chaîne = new ClassPathResource(« raw_sentences.txt « ).Fichier d’accès().Je ne peux pas utiliser ce fichier.log.info (« Charger & Vectoriser des phrases …. »);
// Supprimez les espaces blancs avant et après pour chaque ligne
SentenceIteratorter= new BasicLineIterator(filePath);
Si vous souhaitez charger un fichier texte en plus des phrases fournies dans notre exemple, vous devez le faire:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenisation des données
Word2vec doit être alimenté en mots plutôt qu’en phrases entières, l’étape suivante consiste donc à tokeniser les données. Pour tokeniser un texte, c’est le diviser en ses unités atomiques, en créant un nouveau jeton chaque fois que vous frappez un espace blanc, par exemple.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Formation du modèle
Maintenant que les données sont prêtes, vous pouvez configurer le réseau neuronal Word2vec et alimenter les jetons.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Cette configuration accepte plusieurs hyperparamètres. Quelques-uns nécessitent des explications:
- batchSize est la quantité de mots que vous traitez à la fois.
- minWordFrequency est le nombre minimum de fois qu’un mot doit apparaître dans le corpus. Ici, s’il apparaît moins de 5 fois, il n’est pas appris. Les mots doivent apparaître dans plusieurs contextes pour apprendre des fonctionnalités utiles à leur sujet. Dans les très grands corpus, il est raisonnable d’augmenter le minimum.
- useAdaGrad – Adagrad crée un dégradé différent pour chaque fonctionnalité. Ici, nous ne sommes pas concernés par cela.
- layerSize spécifie le nombre d’entités dans le vecteur de mots. Ceci est égal au nombre de dimensions dans la caractéristiqueespace. Les mots représentés par 500 caractéristiques deviennent des points dans un espace de 500 dimensions.
- Le taux d’apprentissage est la taille de pas pour chaque mise à jour des coefficients, car les mots sont repositionnés dans l’espace des entités.
- minLearningRate est le plancher sur le taux d’apprentissage. Le taux d’apprentissage diminue à mesure que le nombre de mots sur lesquels vous vous entraînez diminue. Si le taux d’apprentissage diminue trop, l’apprentissage du net n’est plus efficace. Cela maintient les coefficients en mouvement.
- iterate indique au réseau sur quel lot de l’ensemble de données il s’entraîne.
- tokenizer lui transmet les mots du lot en cours.
- vec.fit() indique au réseau configuré de commencer l’entraînement.
e) Évaluation du modèle à l’aide de Word2vec
L’étape suivante consiste à évaluer la qualité de vos vecteurs d’entités.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
La ligne vec.similarity("word1","word2") renverra la similarité cosinus des deux mots que vous entrez. Plus il est proche de 1, plus le réseau perçoit ces mots comme similaires (voir l’exemple Suède-Norvège ci-dessus). Exemple:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
Avec vec.wordsNearest("word1", numWordsNearest), les mots imprimés à l’écran vous permettent de déterminer si le réseau a des mots sémantiquement similaires. Vous pouvez définir le nombre de mots les plus proches de votre choix avec le deuxième paramètre wordsNearest. Par exemple:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec en Java dans http://deeplearning4j.org/word2vec.html
7) Word2Vec et Doc2Vec en Python dans genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html