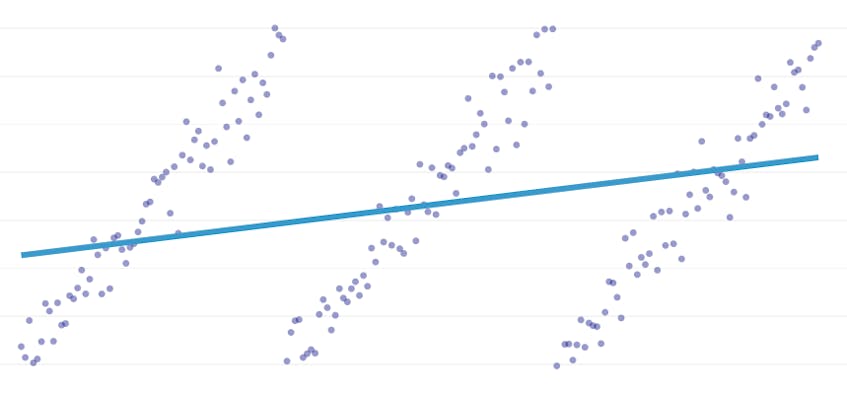
a darabonkénti regresszió a lineáris regresszió egy speciális típusa, amely akkor keletkezik, amikor egyetlen vonal nem elegendő az adathalmaz modellezéséhez. A darabonkénti regresszió a tartományt potenciálisan sok “szegmensre” bontja, és mindegyiken külön vonalat illeszt be. Például, az alábbi grafikonokon, egyetlen sor nem képes modellezni az adatokat, valamint egy darab regresszió három sorral:
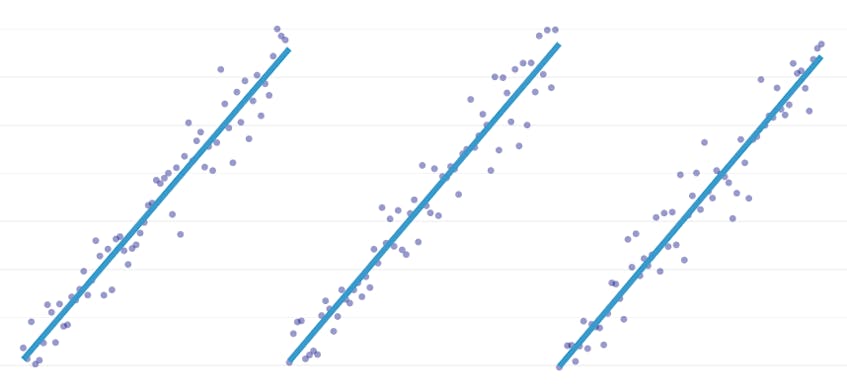
ez a bejegyzés bemutatja a Datadog megközelítését az idősor-adatok darabonkénti regressziójának automatizálására.
célok
a darabonkénti regresszió kissé eltérő dolgokat jelenthet különböző összefüggésekben, ezért szánjunk egy percet annak tisztázására, hogy pontosan mit próbálunk elérni darabonkénti regressziós algoritmusunkkal.
automatikus töréspont-észlelés. A klasszikus statisztikai irodalomban a darabonkénti regressziót gyakran javasolják a kézi regresszióanalízis során, ahol szabad szemmel nyilvánvaló, hogy az egyik lineáris trend utat enged a másiknak. Ebben az esetben az ember megadhatja a töréspontot a darabonkénti szegmensek között, feloszthatja az adatkészletet, és lineáris regressziót hajthat végre minden szegmensen függetlenül. Használati eseteinkben másodpercenként több száz regressziót akarunk végrehajtani, és nem lehetséges, hogy egy ember meghatározza az összes töréspontot. Ehelyett az a követelményünk, hogy darabonkénti regressziós algoritmusunk azonosítsa saját töréspontjait.
automatizált szegmensszám-felismerés. Ha tudnánk, hogy egy adathalmaznak pontosan két szegmense van, könnyen megvizsgálhatnánk az egyes lehetséges szegmenspárokat. A gyakorlatban azonban, ha tetszőleges idősort adunk meg, nincs ok azt feltételezni, hogy egynél több szegmensnek vagy kevesebbnek kell lennie, mint 3, 4 vagy 5. Algoritmusunknak megfelelő számú szegmenst kell kiválasztania anélkül, hogy a felhasználó megadná.
nincs folytonossági követelmény. A darabonkénti regressziók egyes módszerei összekapcsolt szegmenseket generálnak, ahol az egyes szegmensek végpontja a következő szegmens kezdőpontja. Nem írunk elő ilyen követelményt algoritmusunkra.
kihívások
a darabonkénti regresszió automatizált töréspont-detektálással történő megvalósításának legkézenfekvőbb kihívása a megoldáskeresési terület nagy mérete; az összes lehetséges szegmens brute force keresése megfizethetetlenül drága. Az idősorok szegmensekre bontásának módja exponenciális az idősor hosszában. Míg a dinamikus programozás sokkal hatékonyabban bejárhatja ezt a keresési helyet, mint egy naiv brute-force megvalósítás, a gyakorlatban még mindig túl lassú. Kapzsi heurisztikára lesz szükség a keresési terület nagy területeinek gyors eldobásához.
finomabb kihívás az, hogy valamilyen módon össze kell hasonlítanunk az egyik megoldás minőségét a másikkal. A probléma ismeretlen számokkal és a szegmensek elhelyezkedésével kapcsolatos verziójához össze kell hasonlítanunk a lehetséges megoldásokat különböző szegmensszámokkal és különböző töréspontokkal. Azon kapjuk magunkat, hogy két versengő célt próbálunk egyensúlyba hozni:
- minimalizálja a hibákat. Vagyis tegye az egyes szegmensek regressziós vonalát közel a megfigyelt adatpontokhoz.
- használja a legkevesebb szegmenst, amely jól modellezi az adatokat. Mindig nulla hibát kaphatunk, ha minden ponthoz egyetlen szegmenst hozunk létre (vagy akár minden két ponthoz egy szegmenst). Ez azonban meghiúsítaná a regresszió lényegét; nem tudnánk semmit az időbélyeg és a hozzá tartozó metrikus érték közötti általános kapcsolatról, és nem tudnánk könnyen használni az eredményt interpolációra vagy extrapolációra.
megoldásunk
a következő kapzsi algoritmust használjuk a darabonkénti regressziós problémához:
- végezzen darabonkénti regressziót n/2 szegmensekkel, ahol n az idősorok megfigyeléseinek száma. Az egyes szegmensek regressziós vonala a szokásos legkisebb négyzetek (OLS) regresszió alkalmazásával illeszkedik. Ennek a kezdeti darabonkénti regressziónak alig lesz hibája, de súlyosan túl fogja illeszteni az adatkészletet.
- iteratív módon, amíg csak egy szegmens van:
- a szomszédos szegmensek összes párjára vonatkozóan értékelje a teljes hiba növekedését, amely a két szegmens kombinálásakor következne be, két regressziós vonalukat egyetlen regressziós egyenes váltja fel.
- egyesítse a szegmenspárokat, amelyek a legkisebb hibanövekedést eredményeznék.
- ha az egyesítés végrehajtása megfelel a leállítási kritériumoknak (az alábbiakban definiálva), akkor lehet, hogy túl messzire mentünk, két szegmens egyesítésével, amelyeknek külön kell maradniuk. Ebben az esetben emlékezzen a szegmensek állapotára az iteráció egyesítése előtt.
- ha egyetlen egyesítés sem eredményezte a fenti (2C) szegmensek állapotának megjegyzését, akkor a legjobb megoldás egy nagy szegmens. Ellenkező esetben a (2C) – ben utoljára megjegyezendő szegmensállapot a legjobb megoldás.
leállítási feltételek
az egyesítést potenciális megállási pontnak tekintjük, ha az a négyzetes hibák teljes összegét többel növeli, mint bármely korábbi egyesítés. Annak érdekében, hogy megakadályozzuk a túl korai megállást azokban az esetekben, amikor csak egy szegmensnek kell lennie, az egyesítést nem tekintjük potenciális megállási pontnak, kivéve, ha az a teljes hiba növekedését eredményezi, amely kevesebb, mint egy szegmens regressziójának teljes hibájának 3% – a. (A 3% egy önkényes küszöb, de azt találtuk, hogy jól működik a gyakorlatban.) Az alábbiakban bemutatunk néhány példát annak bemutatására, hogy miért működik ez a leállítási kritérium.
először nézzünk meg egy adathalmazt, amelyet úgy hoztunk létre, hogy normálisan elosztott zajt adtunk egyetlen vonal mentén lévő pontokhoz. Az algoritmus helyesen illeszkedik csak egy szegmens ezen keresztül adathalmaz.
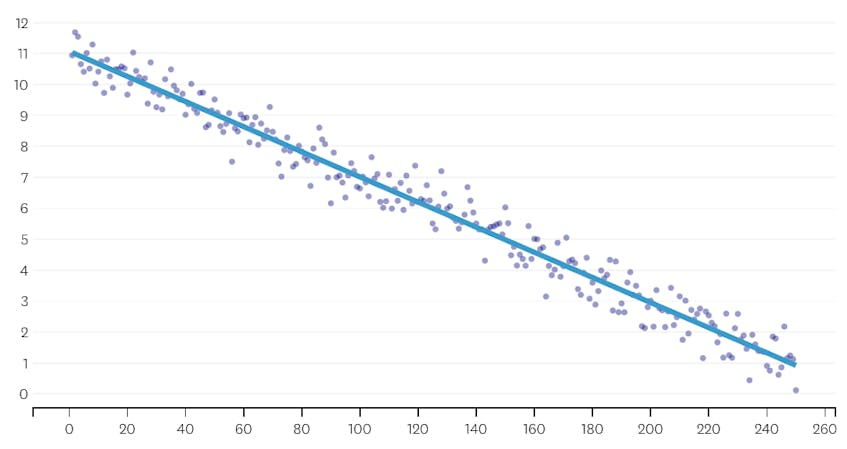
ebben az esetben egyetlen egyesítés sem növeli a négyzethibák teljes összegét több mint 3% – kal. Ezért egyetlen egyesítés sem tekinthető megfelelő megállási pontnak, és az összes egyesítés végrehajtása után a végső állapotot használjuk. Az alábbi ábrán azt látjuk, hogy a későbbi összeolvadások általában több hibát vezetnek be, mint a korábbiak (aminek van értelme, mert mindegyik több pontot érint), de a hiba növekedése csak fokozatosan növekszik, mivel több szegmens egyesül.
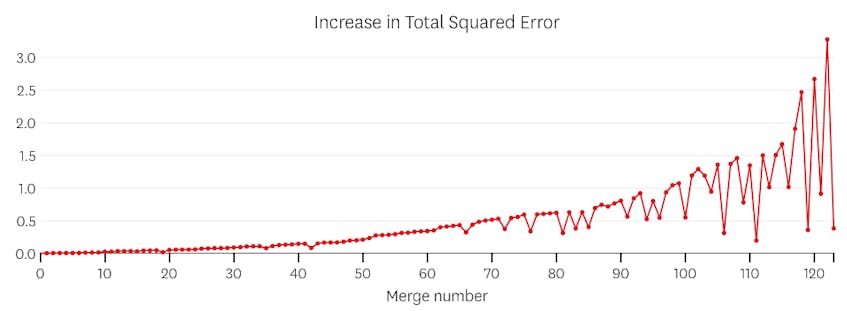
másodszor, nézzünk meg egy példát, ahol hét különálló szegmens van az adatkészletben.
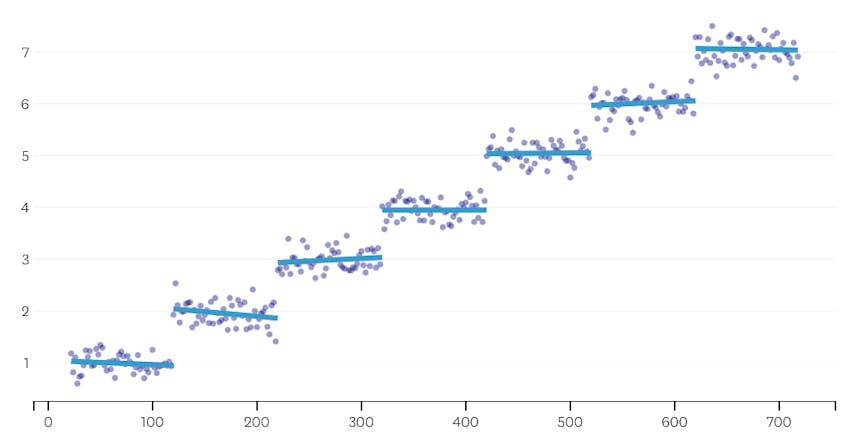
ebben az esetben, amikor megnézzük az egyes egyesítések által bevezetett hibák diagramját, azt látjuk, hogy az utolsó hat egyesítés sokkal több hibát vezetett be, mint az előző egyesítések bármelyike. Ezért algoritmusunk emlékezett a szegmensek állapotára a 6. – tól az utolsóig történő egyesítés előtt, és ezt használta végső megoldásként.
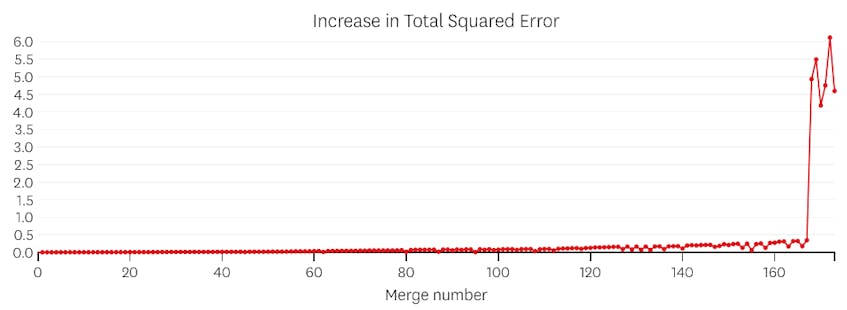
a kód
a Datadog/piecewise Github repo, megtalálja a Python végrehajtását az algoritmus. A piecewise() függvény az, ahol a nehéz emelés történik; adott adatkészlet esetén visszaadja az egyes illesztett szegmensek helyét és regressziós együtthatóit.
a lényeget is tartalmazza plot_data_with_regression() — egy csomagoló funkció a gyors és egyszerű ábrázoláshoz. Egy gyors példa arra, hogyan lehet ezt használni:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)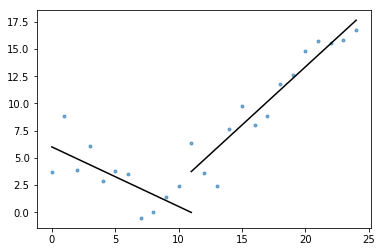
míg ez a megvalósítás OLS lineáris regressziót használ, ugyanaz a keret adaptálható a kapcsolódó problémák megoldására. A négyzethiba helyettesítésével abszolút hiba vagy Huber veszteség, a regresszió robusztus lehet. Vagy egy lépésfüggvény illeszkedhet úgy, hogy minden szegmenshez állandó értéket rendel, amely megegyezik a tartományában lévő megfigyelések átlagával.