ebben a tutorial fogunk magyarázni, az egyik feltörekvő és kiemelkedő szó beágyazási technika nevű Word2Vec által javasolt Mikolov et al. 2013-ban. Ezeket a tartalmakat különböző oktatóanyagokból és forrásokból gyűjtöttük össze, hogy megkönnyítsük az olvasókat egy helyen. Remélem, segít.
a Word2vec olyan modellek kombinációja, amelyeket a szavak elosztott ábrázolására használnak a corpus C. Word2Vec (W2V) egy algoritmus, amely elfogadja a szöveges korpuszt bemenetként, és minden szóhoz vektorábrázolást ad ki, amint az az alábbi ábrán látható:

ennek az algoritmusnak két fajtája van: a CBOW és a Skip-Gram. Adott mondatkészlet (más néven korpusz) a modell hurkokat vet az egyes mondatok szavaira, és vagy megpróbálja használni az aktuális szót w annak érdekében, hogy megjósolja szomszédait (azaz annak kontextusát), ezt a megközelítést “Skip-Gram” – nak hívják, vagy ezeket a kontextusokat használja az aktuális szó előrejelzésére w, ebben az esetben a módszert “folytonos szavak zsákjának” (CBOW) nevezik. Az egyes kontextusokban a szavak számának korlátozásához az “ablakméret” nevű paramétert kell használni.

a szavak ábrázolására használt vektorokat neurális szó beágyazásoknak nevezzük, a reprezentációk pedig furcsaak. Az egyik dolog leírja a másikat, annak ellenére, hogy ez a két dolog radikálisan különbözik egymástól. Ahogy Elvis Costello mondta: “a zenéről írni olyan, mint az építészetről táncolni. A “Word2vec” vektorizálja ” a szavakat, és ezzel a természetes nyelvet számítógéppel olvashatóvá teszi-elkezdhetünk erőteljes matematikai műveleteket végrehajtani a szavakon, hogy felismerjük a hasonlóságukat.
tehát a neurális szó Beágyazása egy számot tartalmazó szót jelent. Ez egy egyszerű, mégis valószínűtlen fordítás. A Word2vec hasonló az autoencoderhez, minden szót egy vektorban kódol, de ahelyett, hogy rekonstrukcióval gyakorolná a bemeneti szavakat, mint egy korlátozott Boltzmann gép, a word2vec a szavakat más szavakkal képzi, amelyek szomszédosak velük a bemeneti korpuszban.
kétféle módon teszi ezt, vagy kontextus segítségével megjósolni a cél szót (a módszer ismert folyamatos zsák szavak, vagy CBOW), vagy egy szó segítségével megjósolni a célkörnyezetet, amelyet skip-gram-nak hívnak. Ez utóbbi módszert használjuk, mert pontosabb eredményeket hoz nagy adatkészleteken.

ha egy szóhoz rendelt jellemzővektor nem használható az adott szó kontextusának pontos előrejelzésére, akkor a vektor összetevői kiigazításra kerülnek. Minden szó kontextusa a korpuszban a tanár hibajeleket küld vissza a funkcióvektor beállításához. A kontextusuk alapján hasonlónak ítélt szavak vektorai közelebb kerülnek egymáshoz a vektorban lévő számok beállításával. Ebben az oktatóanyagban a Skip-Gram modellre fogunk összpontosítani, amely a CBOW-val ellentétben a középső szót a fenti ábrán látható bemenetnek tekinti, és megjósolja a kontextus szavakat.
Model overview
megértettük, hogy néhány furcsa neurális hálózatot kell táplálnunk néhány szópárral, de ezt nem tehetjük meg a tényleges karakterek bemeneteként, meg kell találnunk a módját, hogy ezeket a szavakat matematikailag ábrázoljuk, hogy a hálózat feldolgozza őket. Ennek egyik módja az, hogy létrehozunk egy szókincset a szövegünkben szereplő összes szóból, majd kódoljuk a szót a szókincsünk azonos dimenzióinak vektoraként. Minden dimenzió szó lehet A szókincsünkben. Tehát lesz egy vektorunk minden nullával és egy 1-gyel, amely a megfelelő szót képviseli a szókincsben. Ezt a kódolási technikát egy forró kódolásnak nevezik. Figyelembe véve a példánkat, ha van egy szókincsünk, amely a “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the” “lusta”, “kutya” szavakból áll, akkor a “brown” szót ez a vektor képviseli: .

a Skip-gram modell a szöveg korpuszát veszi fel, és minden szóhoz forró vektort hoz létre. A forró vektor egy szó vektorábrázolása, ahol a vektor a szókincs mérete (összesen egyedi szavak). Minden dimenzió 0-ra van állítva, kivéve azt a dimenziót, amely az adott időpontban bemenetként használt szót képviseli. Íme egy példa egy forró vektorra:

a fenti bemenetet egy rejtett réteggel rendelkező neurális hálózat kapja.
egy olyan beviteli szót fogunk ábrázolni, mint a “hangyák”, mint egy forró vektor. Ennek a vektornak 10 000 összetevője lesz (egy a szókincsünk minden szavához), és egy “1” – et helyezünk a “hangyák” szónak megfelelő pozícióba, és 0s-t az összes többi pozícióba. A hálózat kimenete egyetlen vektor (szintén 10 000 komponenssel), amely szókincsünk minden szavára tartalmazza annak valószínűségét, hogy egy véletlenszerűen kiválasztott közeli szó az a szókincs szó.
a word2vec-ben egy szó elosztott ábrázolását használják. Vegyünk egy több száz dimenziós vektort (mondjuk 1000). Minden szót a súlyok eloszlása képvisel ezen elemek között. Tehát a vektor egyik eleme és a szó közötti egy-egy leképezés helyett a szó ábrázolása a vektor összes elemére kiterjed, és a vektor minden eleme hozzájárul sok szó meghatározásához.
ha a dimenziókat egy hipotetikus szóvektorban címkézem (természetesen nincsenek ilyen előre hozzárendelt címkék az algoritmusban), kissé így nézhet ki:

egy ilyen vektor valamilyen elvont módon képviseli a szó ‘jelentését’. És amint látni fogjuk, egyszerűen egy nagy korpusz vizsgálatával meg lehet tanulni a szavak vektorait, amelyek meglepően kifejező módon képesek megragadni a szavak közötti kapcsolatokat. A vektorokat egy neurális hálózat bemeneteként is felhasználhatjuk. Mivel bemeneti vektoraink egyforróak, a bemeneti vektor szorzása a W1 súlymátrixmal annyit jelent, hogy egyszerűen kiválaszt egy sort a W1-ből.
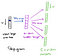

a rejtett rétegtől a kimeneti rétegig a W2 második súlymátrix felhasználható a szókincs minden szavának pontszámának kiszámításához,a softmax pedig a szavak hátsó eloszlásának megszerzéséhez. A skip-gram modell ellentétes a CBOW modellel. A fókuszszóval van felépítve, mint egyetlen bemeneti vektor, és a célkörnyezet szavai most a kimeneti rétegben vannak. A rejtett réteg aktiválási funkciója egyszerűen a megfelelő sor másolását jelenti a W1 súlymátrixból (lineáris), amint azt korábban láttuk. A kimeneti rétegnél most csak egy helyett C multinomiális eloszlásokat adunk ki. Az edzés célja az összegzett előrejelzési hiba mimimizálása a kimeneti réteg összes kontextusszavában. Példánkban a bemenet “tanulás” lenne, és reméljük, hogy (“an”, “efficient”, “method”, “for”, “high”, “quality”, “distributed”, “vector”) látjuk a kimeneti réteget.
itt van a neurális hálózatunk architektúrája.

példánkban azt fogjuk mondani, hogy 300 funkcióval rendelkező word vektorokat tanulunk. Tehát a rejtett réteget egy súlymátrix fogja képviselni 10 000 sorból (egy a szókincsünk minden szavához) és 300 oszlopból (egy minden rejtett neuronhoz). 300 funkciók, amit a Google használt a közzétett modell képzett a Google news dataset (letöltheti innen). A funkciók száma Egy “hiperparaméter”, amelyet csak be kell hangolnia az alkalmazásához (vagyis különböző értékeket kell kipróbálnia, és meg kell néznie, hogy mi hozza a legjobb eredményt).
ha megnézzük ennek a súlymátrixnak a sorait, akkor ezek lesznek a szóvektoraink!

tehát mindennek a végső célja valójában csak ennek a rejtett rétegsúly-mátrixnak a megtanulása-a kimeneti réteg, amelyet csak dobunk, ha végeztünk! A “hangyák” 1 x 300 szóvektora ezután a kimeneti rétegbe kerül. A kimeneti réteg egy softmax regressziós osztályozó. Pontosabban, minden kimeneti neuronnak van egy súlyvektora, amelyet megsokszoroz a rejtett réteg vektor szójával szemben, majd az EXP(x) függvényt alkalmazza az eredményre. Végül, annak érdekében, hogy a kimenetek összege 1 legyen, ezt az eredményt elosztjuk az összes 10 000 kimeneti csomópont eredményének összegével. Íme egy példa a kimeneti neuron kimenetének kiszámítására az “autó”szó esetében.

ha két különböző szónak nagyon hasonló “összefüggései” vannak (vagyis milyen szavak valószínűleg megjelennek körülöttük), akkor modellünknek nagyon hasonló eredményeket kell kiadnia e két szó esetében. Az egyik módja annak, hogy a hálózat hasonló kontextus-előrejelzéseket adjon ki erre a két szóra, ha a vektorok hasonlóak. Tehát, ha két szónak hasonló összefüggései vannak, akkor hálózatunk motivált arra, hogy hasonló szóvektorokat tanuljon ehhez a két szóhoz! Ta da!
a bemenet minden dimenziója áthalad a rejtett réteg minden csomópontján. A dimenziót megszorozzuk a rejtett réteghez vezető tömeggel. Mivel a bemenet forró vektor, csak az egyik bemeneti csomópontnak lesz nem nulla értéke (nevezetesen 1 értéke). Ez azt jelenti, hogy egy szó esetében csak az 1.értékű bemeneti csomóponthoz társított súlyok aktiválódnak, amint az a fenti képen látható.
mivel a bemenet ebben az esetben forró vektor, csak az egyik bemeneti csomópontnak lesz nem nulla értéke. Ez azt jelenti, hogy csak a bemeneti csomóponthoz csatlakoztatott súlyok aktiválódnak a rejtett csomópontokban. Az alábbiakban bemutatunk egy példát a figyelembe veendő súlyokra a szókincs második szavához:
a második szó vektorábrázolása a szókincsben (a fenti neurális hálózatban látható) a következőképpen fog kinézni, miután aktiválódott a rejtett rétegben:
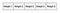
ezek a súlyok véletlenszerű értékekként indulnak. A hálózat ezután képzett annak érdekében, hogy állítsa be a súlyokat, hogy képviselje a bemeneti szavakat. Itt válik fontossá a kimeneti réteg. Most, hogy a rejtett rétegben vagyunk a szó vektorábrázolásával, szükségünk van egy módra annak meghatározására, hogy mennyire jól jósoltuk meg, hogy egy szó illeszkedik egy adott kontextusba. A szó kontextusa Szavak halmaza a körülötte lévő ablakban, az alábbiak szerint:

a fenti kép azt mutatja, hogy a pénteki kontextusban olyan szavak szerepelnek, mint a” macska “és az”is”. A neurális hálózat célja annak előrejelzése, hogy a “péntek” ebbe az összefüggésbe tartozik.
a kimeneti réteget úgy aktiváljuk, hogy megszorozzuk a rejtett rétegen áthaladó vektort (amely a bemeneti forró vektor * a rejtett csomópontba belépő súlyok) a kontextus szó vektorábrázolásával (amely a kontextus szó forró vektora * a kimeneti csomópontba belépő súlyok). Az első kontextus szó kimeneti rétegének állapota alább látható:

a fenti szorzás történik minden szót összefüggésben szó pár. Ezután kiszámítjuk annak valószínűségét, hogy egy szó kontextusszavakhoz tartozik, a rejtett és kimeneti rétegekből származó értékek felhasználásával. Végül sztochasztikus gradiens süllyedést alkalmazunk a súlyok értékeinek megváltoztatására annak érdekében, hogy a kiszámított valószínűségre kívánatosabb értéket kapjunk.
a gradiens süllyedésnél ki kell számolnunk az optimalizált függvény gradiensét azon a ponton, amely a változó súlyt képviseli. A gradienst ezután arra használják, hogy kiválasszák azt az irányt, amelyben lépést tesznek a helyi optimum felé, amint azt az alábbi minimalizálási példa mutatja.
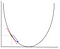
a súlyt úgy változtatjuk meg, hogy egy lépést teszünk az optimális pont irányába (a fenti példában a grafikon legalacsonyabb pontja). Az új értéket úgy számítják ki, hogy az aktuális súlyértékből kivonják a származtatott függvényt a tanulási sebességgel méretezett súly pontján. A következő lépés a Backpropagation használata, a több réteg közötti súlyok beállításához. A kimeneti réteg végén kiszámított hiba a láncszabály alkalmazásával visszakerül a kimeneti rétegből a rejtett rétegbe. A gradiens süllyedést a két réteg közötti súlyok frissítésére használják. A hibát ezután minden rétegben korrigálják, majd tovább küldik vissza. Itt van egy diagram a backpropagation ábrázolására:

megértés a
példa használatával a Word2vec egyetlen rejtett réteget használ, teljesen összekapcsolt neurális hálózatot, az alábbiak szerint. A rejtett réteg neuronjai mind lineáris neuronok. A bemeneti réteg úgy van beállítva, hogy annyi idegsejt legyen, ahány szó van a szókincsben a képzéshez. A rejtett réteg méretét a kapott szóvektorok dimenziójára állítjuk be. A kimeneti réteg mérete megegyezik a bemeneti réteg méretével. Így, ha a szókincs a tanulás szó Vektorok áll V szavak és N, hogy a dimenziója szó Vektorok, a bemenet rejtett réteg kapcsolatokat lehet képviselni mátrix WI méretű VXN minden sorban képviselő szókincs szó. Ugyanígy a rejtett rétegtől a kimeneti rétegig tartó kapcsolatokat az NxV méretű wo mátrix írja le. Ebben az esetben a wo mátrix minden oszlopa egy szót képvisel az adott szókincsből.

a hálózat bemenete az “1-Out of-V” ábrázolással van kódolva, ami azt jelenti, hogy csak egy bemeneti vonal van beállítva egyre, a többi bemeneti vonal pedig nullára van állítva.
tegyük fel, hogy van egy kiképző korpuszunk, amelynek a következő mondatai vannak:
“a kutya macskát látott”, “a kutya üldözte a macskát”, “a macska fára mászott”
a korpusz szókincsének nyolc szava van. Miután ábécé sorrendben, minden szó lehet hivatkozni az index. Ebben a példában a neurális hálózatunknak nyolc bemeneti és nyolc kimeneti neuronja lesz. Tegyük fel, hogy úgy döntünk, hogy három neuront használunk a rejtett rétegben. Ez azt jelenti, hogy a WI és a WO mátrixok 8 (3) és 3 (8) (8) lesz. Az edzés megkezdése előtt ezeket a mátrixokat kis véletlenszerű értékekre inicializálják, amint az a neurális hálózati képzésben szokásos. Csak az illusztráció kedvéért tegyük fel, hogy a WI és a WO a következő értékekre inicializálódik:

tegyük fel, hogy azt akarjuk, hogy a hálózat megtanulja a “macska” és a “felmászott”szavak közötti kapcsolatot. Ez azt jelenti, hogy a hálózatnak nagy valószínűséggel kell megjelennie a “felmászott”, amikor a “macska” be van írva a hálózatba. A szó beágyazási terminológiájában a “macska” szót kontextus szónak, a “felmászott” szót pedig célszónak nevezik. Ebben az esetben a bemeneti vektor X lesz t. vegye figyelembe, hogy a vektornak csak a második komponense 1. Ennek oka az, hogy a bemeneti szó “macska”, amely a második helyet tartja a korpusz szavak rendezett listájában. Tekintettel arra, hogy a célszó “felmászott”, a célvektor úgy néz ki, mint t. A “cat”-t képviselő bemeneti vektorral a rejtett réteg neuronjainak kimenete a következőképpen számítható ki:
Ht = XtWI =
nem szabad meglepődnünk, hogy a rejtett neuron kimenetek H vektora utánozza a WI mátrix második sorának súlyát az 1-Out-of-Vreprezentáció miatt. Tehát a rejtett rétegkapcsolatok bemenetének funkciója alapvetően a bemeneti szó vektorának a rejtett rétegbe másolása. Hasonló manipulációk végrehajtása a rejtett kimeneti réteghez, a kimeneti réteg neuronjainak aktiválási vektora
HtWO =
mivel a cél az készítsen valószínűségeket a kimeneti rétegben lévő szavakra, Pr (wordk|wordcontext) mert k = 1, V, hogy tükrözze a következő szó kapcsolatát a kontextus szóval a bemenetnél, szükségünk van a kimeneti réteg neuron kimeneteinek összegére, hogy hozzáadjunk egyet. A Word2vec ezt úgy éri el, hogy a kimeneti réteg neuronjainak aktiválási értékeit valószínűségekké alakítja a softmax függvény segítségével. Így a K-edik neuron kimenetét a következő kifejezéssel számítjuk ki, ahol az aktiválás (n) az n-edik kimeneti réteg neuron aktiválási értékét képviseli:
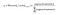
így a korpusz nyolc szavának valószínűsége a következő:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
a félkövér valószínűség a kiválasztott “felmászott”célszóra vonatkozik. Tekintettel a célvektorra t, a kimeneti réteg hibavektora könnyen kiszámítható a valószínűségi vektor kivonásával a célvektorból. Amint a hiba ismert, a wo és WI mátrixok súlyai frissíthetők a backpropagation használatával. Így a képzés folytatódhat a korpusz különböző kontextus-cél szavak párjának bemutatásával. Így tanulja meg a Word2vec a szavak közötti kapcsolatokat, és a folyamat során vektorreprezentációkat fejleszt a korpuszban lévő szavakhoz.
az ötlet mögött word2vec az, hogy képviselje a szavakat egy vektor valós számok dimenzió d. Ezért a második mátrix ezeknek a szavaknak az ábrázolása. Ennek a mátrixnak az i-edik sora az i-edik szó vektorábrázolása. Tegyük fel , hogy a példádban 5 szó van:, akkor az első vektor azt jelenti, hogy a “ló” szót veszi figyelembe, tehát a “ló” ábrázolása az . Hasonlóképpen az “oroszlán”szó ábrázolása.

tudomásom szerint ezekben az ábrázolásokban nincs kifejezetten” emberi jelentés ” az egyes számokra. Az egyik szám nem azt jelenti, hogy a szó ige-e vagy sem, melléknév vagy sem… csak a súlyokat változtatja meg, hogy megoldja az optimalizálási problémát, hogy megtanulja a szavak ábrázolását.
a word2vec mátrixszorzási folyamatot legjobban kidolgozó vizuális diagram a következő ábrán látható:

az első mátrix a bemeneti vektort egy forró formátumban képviseli. A második mátrix a szinaptikus súlyokat képviseli a bemeneti réteg neuronjaitól a rejtett réteg neuronjáig. Különösen vegye figyelembe a bal felső sarkot, ahol a bemeneti réteg mátrixot megszorozzuk a Súlymátrixmal. Most nézd meg a jobb felső sarokban. Ez a mátrix szorzás InputLayer dot-előállított súlyok átültetése csak egy praktikus módja annak, hogy képviselje a neurális hálózat a jobb felső sarokban.
az első rész a bemeneti szót egy forró vektorként, a másik mátrix pedig az egyes bemeneti réteg neuronok rejtett réteg neuronokhoz való kapcsolódásának súlyát jelenti. Mivel a Word2Vec vonatok, ez backpropagates (a gradiens Süllyedés) ezeket a súlyokat, és megváltoztatja őket, hogy jobban reprezentálja a szavakat, mint vektorok. Miután a képzés befejeződött, csak ezt a súlymátrixot használja, mondjuk a ‘kutyát’, és szorozza meg a javított súlymátrixmal, hogy megkapja a’ kutya ‘ vektoros ábrázolását a rejtett réteg neuronok dimenziójában = nem. Az ábrán a rejtett réteg neuronok száma 3.
dióhéjban a Skip-gram modell megfordítja a cél és a kontextus szavak használatát. Ebben az esetben a célszó a bemeneten kerül betáplálásra, a rejtett réteg ugyanaz marad, a neurális hálózat kimeneti rétege pedig többször megismétlődik, hogy befogadja a kiválasztott számú kontextus szót. A “cat” és a “tree” mint kontextus szavak és a “mászott” mint célszó példáját véve a skim-gram modellben a bemeneti vektor t lenne, míg a két kimeneti réteg t és t mint célvektor lenne. Egy valószínűségi vektor előállítása helyett két ilyen vektort állítanánk elő a jelenlegi példához. Az egyes kimeneti rétegek hibavektorát a fent tárgyalt módon állítjuk elő. Az összes kimeneti réteg hibavektorait azonban összegezzük, hogy a súlyokat backpropagation segítségével állítsuk be. Ez biztosítja, hogy a wo súlymátrix minden kimeneti réteghez azonos maradjon az edzés során.
kevés további módosításra van szükségünk az alapvető skip-gram modellhez, amelyek fontosak a vonat kivitelezhetőségéhez. A gradiens ereszkedés egy ekkora neurális hálózaton lassú lesz. És hogy még rosszabb legyen a helyzet, hatalmas mennyiségű edzési adatra van szüksége ahhoz, hogy beállítsa ezt a sok súlyt, és elkerülje a túlzott illeszkedést. több millió súly szorozva milliárd képzési mintával azt jelenti, hogy ennek a modellnek a kiképzése vadállat lesz. Ehhez a szerzők két módszert javasoltak, az úgynevezett részmintavételt és a negatív mintavételt, amelyekben a jelentéktelen szavakat eltávolítják, és csak egy meghatározott súlymintát frissítenek.
Mikolov et al. használjon egy egyszerű részmintavételi megközelítést a ritka és gyakori szavak közötti egyensúlyhiány ellensúlyozására a képzési készletben (például az “in”, “the” és “a” kevesebb információértéket biztosít, mint a ritka szavak). Minden szó a képzési készlet eldobjuk valószínűséggel P (wi), ahol

f (wi)a wi szó gyakorisága, t pedig egy választott küszöb, általában 10-5 körül.
végrehajtási részletek
a Word2vec különböző nyelveken került megvalósításra, de itt különösen a Java-ra fogunk összpontosítani., DeepLearning4j, darks-learning és python . Különböző neurális net algoritmusokat valósítottak meg a DL4j-ben, a kód elérhető a GitHub-on.
a DL4j-ben történő megvalósításához néhány lépést fogunk végrehajtani a következők szerint:
a) Word2Vec Setup
hozzon létre egy új projektet az IntelliJ-ben a Maven használatával. Ezután adja meg a tulajdonságokat és a függőségeket a POM-ban.xml fájl a projekt gyökérkönyvtárában.
b) adatok betöltése
most hozzon létre és nevezzen el egy új osztályt a Java-ban. Azután, akkor vegye be a nyers mondatokat .TXT fájl, keresse meg őket az iterátorral, és tegye ki őket valamilyen előfeldolgozásnak, például konvertálja az összes szót kisbetűvé.
String filePath = új Classpatresource(“raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info (“Betöltés & mondatok vektorizálása….”);
// Strip fehér szóköz előtt és után minden sorban
SentenceIterator iter = new BasicLineIterator(filePath);
ha a példánkban megadott mondatok mellett szöveges fájlt is be szeretne tölteni, akkor ezt kell tennie:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Az adatok tokenizálása
a Word2vec-et egész mondatok helyett szavakkal kell betáplálni, így a következő lépés az adatok tokenizálása. A szöveg tokenizálása azt jelenti, hogy atomegységeire bontja, új tokent hozva létre minden alkalommal, amikor például egy fehér szóközt üt meg.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) A modell betanítása
most, hogy az adatok készen vannak, konfigurálhatja a Word2vec neurális hálót és betáplálhatja a tokeneket.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
ez a konfiguráció több hiperparamétert is Elfogad. Néhány igényel némi magyarázatot:
- batchSize az összeg a szavakat feldolgozni egy időben.
- a minWordFrequency az a minimális szám, ahányszor egy szónak meg kell jelennie a korpuszban. Itt, ha kevesebb, mint 5-ször jelenik meg, nem tanulják meg. A szavaknak több kontextusban kell megjelenniük, hogy hasznos funkciókat tanuljanak róluk. Nagyon nagy korpuszokban ésszerű a minimum emelése.
- useAdaGrad — Adagrad létrehoz egy másik gradiens minden funkció. Itt nem foglalkozunk ezzel.
- a layerSize megadja a word vektor jellemzőinek számát. Ez megegyezik a jellemzők dimenzióinak számávaltérben. Az 500 funkció által képviselt szavak pontokká válnak egy 500 dimenziós térben.
- a tanulási arány az együtthatók minden frissítésének lépésmérete, mivel a szavak áthelyeződnek a funkciótérben.
- minLearningRate a padló a tanulási Arány. Tanulási Arány bomlik, mint a szavak száma a vonat csökken. Ha a tanulási arány túl sokat csökken, a net tanulása már nem hatékony. Ez mozgatja az együtthatókat.
- az iterate megmondja a netnek, hogy az adatkészlet melyik tételén edz.
- tokenizer táplálja a szavakat az aktuális tétel.
- vec.fit () megmondja a konfigurált net kezdeni képzés.
e) a modell kiértékelése a Word2vec használatával
a következő lépés a funkcióvektorok minőségének értékelése.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
a vec.similarity("word1","word2") sor visszaadja a beírt két szó koszinusz hasonlóságát. Minél közelebb van az 1-hez, annál hasonlóbbnak érzékeli a háló ezeket a szavakat (lásd a fenti Svédország-Norvégia példát). Például:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
A vec.wordsNearest("word1", numWordsNearest) segítségével a képernyőre nyomtatott szavak lehetővé teszik, hogy szemantikailag hasonló szavakat csoportosítson-e a háló. A legközelebbi szavak számát A wordsNearest második paraméterével állíthatja be. Például:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec a Java-ban http://deeplearning4j.org/word2vec.html
7) Word2Vec és Doc2Vec Pythonban a genizmusban http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html