a Non-uniform memory access (numa) egy megosztott memória architektúra, amelyet a mai többprocesszoros rendszerekben használnak. Minden CPU saját helyi memóriával rendelkezik, és a rendszer többi CPU-jából is hozzáférhet a memóriához. A helyi memóriahozzáférés alacsony késleltetést biztosít – nagy sávszélességű teljesítményt. Míg a másik CPU tulajdonában lévő memória elérése nagyobb késleltetéssel és alacsonyabb sávszélességgel rendelkezik. A Modern alkalmazások és operációs rendszerek, mint például az ESXi alapértelmezés szerint támogatják a NUMA-t, de a legjobb teljesítmény érdekében a virtuális gépek konfigurálását a numa architektúra szem előtt tartásával kell elvégezni. Helytelen tervezés, következetlen viselkedés vagy általános teljesítményromlás következik be az adott virtuális gépen, vagy a legrosszabb esetben az adott ESXi-gazdagépen futó összes virtuális gép esetében.
a sorozat célja, hogy betekintést nyújtson a CPU architektúrájába, a memória alrendszerbe, valamint az ESXi CPU-ba és a memória ütemezőbe. Lehetővé teszi egy nagy teljesítményű platform létrehozását, amely megalapozza a magasabb szolgáltatásokat és a megnövekedett konszolidációs arányokat. Mielőtt elérkeznénk a modern számítási architektúrákhoz, hasznos áttekinteni a megosztott memóriájú többprocesszoros architektúrák történetét, hogy megértsük, miért használjuk ma a NUMA rendszereket.
- a megosztott memóriájú többprocesszoros architektúra fejlődése az elmúlt évtizedekben
- a snoop protokollok gyorsítótárazásának bevezetése
- egységes memória-hozzáférési architektúra
- Non-Uniform Memory Access Architecture
- 1: Non-Uniform Memory Access organization
- 2: Point-to-Point interconnect
- 3: skálázható gyorsítótár koherencia
- nem interleaved enabled numa = suma
- Nehalem & Core mikroarchitektúra áttekintés
a megosztott memóriájú többprocesszoros architektúra fejlődése az elmúlt évtizedekben
úgy tűnik, hogy az egységes memória-hozzáférésnek nevezett architektúra jobban illeszkedne egy következetesen alacsony késleltetésű, nagy sávszélességű platform tervezéséhez. A modern rendszerarchitektúrák azonban korlátozzák, hogy valóban egységes legyen. Ahhoz, hogy megértsük ennek az okát, vissza kell mennünk a történelembe, hogy azonosítsuk a párhuzamos számítástechnika legfontosabb mozgatórugóit.
a relációs adatbázisok bevezetésével a hetvenes évek elején általánossá vált az olyan rendszerek iránti igény, amelyek egyszerre több felhasználói műveletet és túlzott adattermelést tudnak kiszolgálni. Az egyprocesszor teljesítményének lenyűgöző üteme ellenére a többprocesszoros rendszerek jobban fel voltak szerelve ennek a munkaterhelésnek a kezelésére. A költséghatékony rendszer biztosítása érdekében a megosztott memória címterülete a kutatás középpontjába került. Korán a keresztrúd kapcsolót használó rendszereket támogatták, azonban ezzel a tervezési bonyolultsággal a processzorok növekedésével együtt skálázták, ami vonzóbbá tette a busz alapú rendszert. A buszrendszer processzorai hozzáférhetnek a teljes memóriaterülethez azáltal, hogy kéréseket küldenek a buszon, ez egy nagyon költséghatékony módszer a rendelkezésre álló memória lehető legoptimálisabb felhasználására.
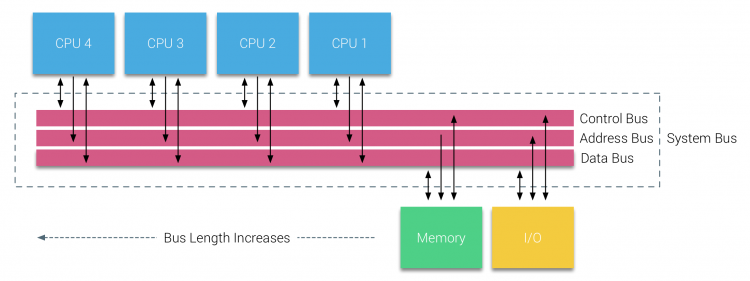
a busz alapú rendszereknek azonban saját skálázhatósági problémáik vannak. A fő kérdés a korlátozott sávszélesség, ez korlátozza a processzorok számát, amelyeket a busz képes befogadni. A CPU – k hozzáadása a rendszerhez két fő aggodalomra ad okot:
- a rendelkezésre álló sávszélesség csomópontonként csökken minden egyes CPU hozzá.
- a busz hossza növekszik, ha több processzort ad hozzá, ezáltal növelve a késleltetést.
a CPU teljesítménynövekedése és különösen a processzor és a memória teljesítménye közötti sebességkülönbség pusztító volt, és valójában még mindig pusztító a Multiprocesszorok számára. Mivel a processzor és a memória közötti memóriahézag várhatóan növekedni fog, sok erőfeszítést tettek a memóriarendszerek kezelésére szolgáló hatékony stratégiák kidolgozására. Az egyik ilyen stratégia a memória gyorsítótár hozzáadása volt, amely számos kihívást vezetett be. Ezeknek a kihívásoknak a megoldása ma is a CPU-tervező csapatok fő fókusza, sok kutatást végeznek a gyorsítótárazási struktúrákról és a kifinomult algoritmusokról a gyorsítótár hiányának elkerülése érdekében.
a snoop protokollok gyorsítótárazásának bevezetése
gyorsítótár csatolása minden CPU-hoz sok szempontból növeli a teljesítményt. A memória közelebb hozása a CPU-hoz csökkenti az átlagos memóriahozzáférési időt, ugyanakkor csökkenti a memóriabusz sávszélesség-terhelését. A megosztott memória architektúrában az egyes CPU-k gyorsítótárának hozzáadásával az a kihívás, hogy lehetővé teszi a memóriablokk több példányának létezését. Ez az úgynevezett cache-koherencia probléma. Ennek megoldására a Snoop protokollok gyorsítótárazását találták ki, megpróbálva létrehozni egy olyan modellt, amely a helyes adatokat szolgáltatta, miközben nem próbálta elfogyasztani a busz összes sávszélességét. A legnépszerűbb protokoll, írja érvényteleníteni, törli az összes többi adatmásolatot a helyi gyorsítótár írása előtt. Az adatok más processzorok általi későbbi olvasása gyorsítótár-hiányt észlel a helyi gyorsítótárban, és egy másik CPU gyorsítótárából kerül kiszolgálásra, amely a legutóbb módosított adatokat tartalmazza. Ez a modell sok busz sávszélességet mentett meg, és lehetővé tette az egységes memória-hozzáférési rendszerek megjelenését az 1990-es évek elején. a Modern gyorsítótár-koherencia protokollokat részletesebben a 3.rész tárgyalja.
egységes memória-hozzáférési architektúra
a Buszalapú Multiprocesszorok processzorait, amelyek a rendszer bármely memóriamoduljához azonos – egységes – hozzáférési időt tapasztalnak, gyakran Uniform Memory Access (UMA) rendszereknek vagy szimmetrikus Multi-processzoroknak (SMP) nevezik.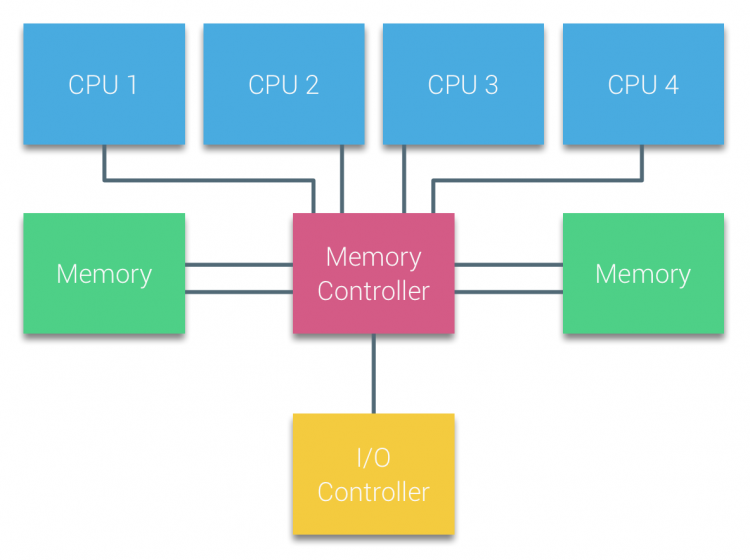
az UMA rendszerekkel a CPU-k rendszerbuszon (elülső busz) keresztül kapcsolódnak az északi hídhoz. Az északi híd tartalmazza a memóriavezérlőt, és minden memóriába irányuló és onnan érkező kommunikációnak az Északi hídon kell áthaladnia. Az I/O vezérlő, amely az összes eszköz I / O kezeléséért felelős, csatlakozik az északi hídhoz. Ezért minden I / O – nak át kell mennie az Északi hídon, hogy elérje a CPU-t.
több buszt és memóriacsatornát használnak a rendelkezésre álló sávszélesség megduplázására és az északi híd szűk keresztmetszetének csökkentésére. A memória sávszélességének további növelése érdekében egyes rendszerek külső memóriavezérlőket csatlakoztattak az északi hídhoz, javítva a sávszélességet és több memória támogatását. Az északi híd belső sávszélessége és a korai snoopy gyorsítótár protokollok sugárzási jellege miatt azonban UMA korlátozott skálázhatóságúnak tekinthető. A nagy sebességű flash eszközök mai használatával, másodpercenként több százezer IO-t tolva, teljesen igazuk volt abban, hogy ez az architektúra nem méreteződik a jövőbeli munkaterhelésekhez.
Non-Uniform Memory Access Architecture
a skálázhatóság és a teljesítmény javítása érdekében három kritikus változtatás történik a megosztott memóriás multiprocesszor architektúrán;
- nem egységes memória hozzáférési szervezet
- pont-pont összekapcsolási topológia
- skálázható gyorsítótár koherencia megoldások
1: Non-Uniform Memory Access organization
a NUMA eltávolodik a központi memóriakészlettől, és topológiai tulajdonságokat vezet be. A memóriahely-bázisok osztályozásával a processzortól a memóriáig terjedő jelút hossza alapján elkerülhető a késleltetés és a sávszélesség szűk keresztmetszete. Ez a processzor és a lapkakészlet teljes rendszerének újratervezésével történik. A NUMA architektúrák a 90-es évek végén váltak népszerűvé, amikor olyan SGI szuperszámítógépeken használták, mint a Cray Origin 2000. A numa segített azonosítani a memória helyét, ebben az esetben ezeknek a rendszereknek azon kellett gondolkodniuk, hogy melyik memóriaterület melyik alvázban tartja a memóriabiteket.
a millenniumi évtized első felében az AMD a numa-t a vállalati környezetbe hozta, ahol az UMA rendszerek uralkodtak. 2003-ban bemutatták az AMD Opteron családot, amely integrált memóriavezérlőkkel rendelkezik, mindegyik CPU rendelkezik kijelölt memóriabankokkal. Minden CPU-nak megvan a saját memória címtere. A numa optimalizált operációs rendszer, mint például az ESXi, lehetővé teszi a munkaterhelés számára, hogy mindkét memóriacím-helyről memóriát fogyasszon, miközben optimalizálja a helyi memória-hozzáférést. Használjunk egy példát két CPU rendszerre, hogy tisztázzuk a különbséget a helyi és a távoli memória hozzáférés között egyetlen rendszeren belül.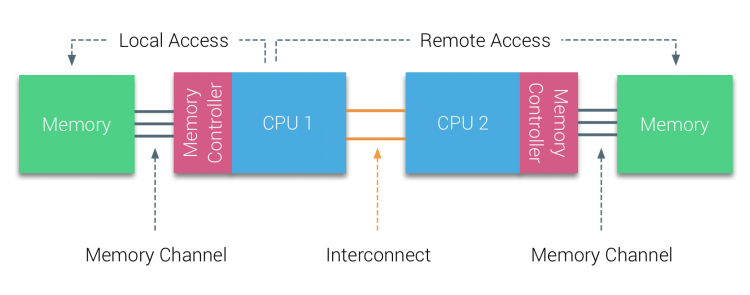
a CPU1 memóriavezérlőjéhez csatlakoztatott memória helyi memóriának minősül. A másik CPU aljzathoz (CPU2)csatlakoztatott memória idegen vagy távoli a CPU1 számára. A távoli memóriahozzáférés a helyi memóriahozzáféréshez képest további késéssel jár, mivel át kell haladnia egy összeköttetésen (pont-pont kapcsolat), és csatlakoznia kell a távoli memóriavezérlőhöz. A különböző memóriahelyek eredményeként ez a rendszer “nem egységes” memória-hozzáférési időt tapasztal.
2: Point-to-Point interconnect
az AMD bemutatta a pont-pont kapcsolat HyperTransport az AMD Opteron mikroarchitektúra. Az Intel 2007-ben eltávolodott kettős független busz-architektúrájuktól a QuickPath architektúra bevezetésével Nehalem Processzorcsaládjuk tervezésében.
a Nehalem architektúra jelentős tervezési változás volt az Intel mikroarchitektúráján belül, és az Intel Core sorozat első igazi generációjának tekinthető. A jelenlegi Broadwell architektúra az Intel Core márka 4. generációja (Intel Xeon E5 v4), az utolsó bekezdés további információkat tartalmaz a mikroarchitektúra generációiról. A QuickPath architektúrán belül a memóriavezérlők a CPU-ra költöztek, és bevezették a QuickPath point-to-point Interconnect-et (QPI), mint adatkapcsolatot a CPU-k között a rendszerben.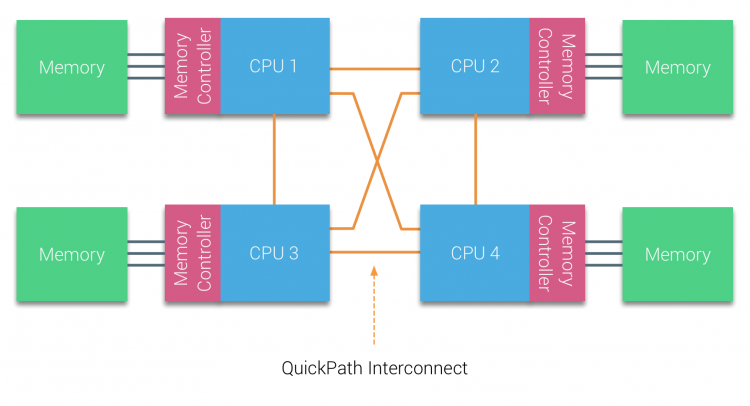
a Nehalem mikroarchitektúra nemcsak a régi elülső buszt váltotta fel, hanem az egész alrendszert moduláris felépítéssé alakította át a szerver CPU számára. Ezt a moduláris kialakítást “Uncore” néven vezették be, és létrehoz egy építőelem könyvtárat a gyorsítótárazáshoz és az összekapcsolási sebességekhez. Az elülső busz eltávolítása javítja a sávszélesség skálázhatóságát, de a processzoron belüli és a processzorok közötti kommunikációt meg kell oldani, ha hatalmas mennyiségű memóriakapacitással és sávszélességgel foglalkozik. Mind az integrált memóriavezérlő, mind a QuickPath összeköttetések az Uncore részét képezik, és MODELLSPECIFIKUS regiszterek (MSR) ). Egy MSR – hez csatlakoznak, amely biztosítja az intra-és a processzorok közötti kommunikációt. Az Uncore modularitása lehetővé teszi az Intel számára, hogy különböző QPI sebességeket kínáljon, az Intel Broadwell-EP mikroarchitektúra (2016) írásakor 6, 4 Giga-transzfert kínál másodpercenként (GT/s), 8, 0 GT/s és 9, 6 GT/s. illetve elméleti maximális sávszélességet biztosít 25, 6 GB/s, 32 GB/s és 38, 4 GB/s a CPU-k között. Ennek perspektívájába helyezve az utoljára használt elülső busz 1,6 GT/s vagy 12,8 GB/s platform sávszélességet biztosított. A Sandy Bridge bevezetésekor az Intel átnevezte az Uncore-t a System Agent-be, ennek ellenére a Uncore kifejezést továbbra is használják a jelenlegi dokumentációban. A QuickPath-ról és az Uncore-ról többet a 2.részben talál.
3: skálázható gyorsítótár koherencia
minden magnak volt egy privát elérési útja Az L3 gyorsítótárhoz. Minden út ezer vezetékből állt, és el lehet képzelni, hogy ez nem méretezhető jól, ha csökkenteni szeretné a nanométeres gyártási folyamatot, miközben növeli a gyorsítótárhoz hozzáférni kívánt magokat is. Annak érdekében, hogy méretezni lehessen, a Sandy Bridge architektúra az L3 gyorsítótárat áthelyezte az Uncore-ból, és bevezette a skálázható ring on-die Interconnect-et. Ez lehetővé tette az Intel számára, hogy az L3 gyorsítótárat egyenlő szeletekre osztja. Ez nagyobb sávszélességet és asszociativitást biztosít. Minden szelet 2,5 MB, és egy szelet van társítva minden maghoz. A gyűrű lehetővé teszi, hogy minden mag hozzáférjen minden más szelethez is. Az alábbi képen a Broadwell mikroarchitektúra (v4) (2016) alacsony Magszámú (LCC) Xeon CPU szerszámkonfigurációja látható.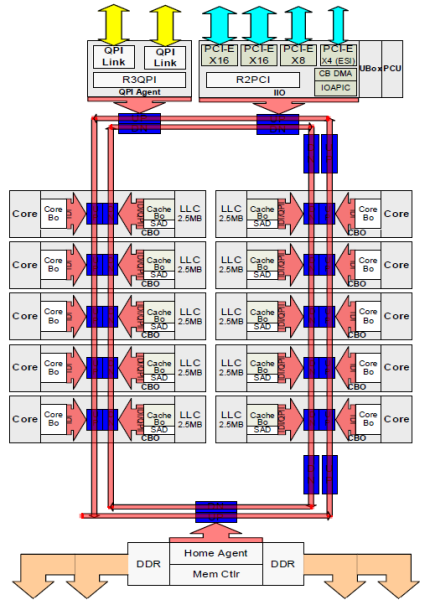
ez a gyorsítótár-architektúra olyan snooping protokollt igényel, amely magában foglalja mind az elosztott helyi gyorsítótárat, mind a rendszer többi processzorát a gyorsítótár koherenciájának biztosítása érdekében. További magok hozzáadásával a rendszerben növekszik a snoop forgalom mennyisége, mivel minden magnak megvan a saját állandó gyorsítótár-áramlása. Ez befolyásolja a QPI linkek és az utolsó szintű gyorsítótárak fogyasztását, ami folyamatos fejlesztést igényel a snoop koherencia protokollokban. Az Uncore, skálázható ring on-Die Interconnect részletes áttekintése és a snoop protokollok gyorsítótárazásának fontossága a NUMA teljesítményében a 3. részben szerepel.
nem interleaved enabled numa = suma
a fizikai memória elosztva van az alaplapon, azonban a rendszer egyetlen memória címtartományt tud biztosítani a memória interleaving a két numa csomópont között. Ezt Node-interleavingnek nevezzük (a beállítást a 2.rész tartalmazza). Ha a csomópont-átlapolás engedélyezve van, a rendszer kellően egységes memória-Architektúrává (SUMA) válik. Ahelyett, hogy továbbítaná a topológiai információkat és a rendszerben lévő processzorok és memória jellegét az operációs rendszernek, a rendszer a teljes memóriatartományt 4KB címezhető régiókra bontja, és körmérkőzéses módon térképezi fel őket minden csomópontról. Ez egy ‘interleaved’ memóriaszerkezetet biztosít, ahol a memória címtere eloszlik a csomópontok között. Amikor az ESXi memóriát rendel a virtuális géphez, akkor két különböző csomópontból származó fizikai memóriát foglal le, amikor a 0 csomópontban található fizikai CPU-nak le kell töltenie a memóriát az 1.csomópontból, a memória áthalad a QPI linkeken.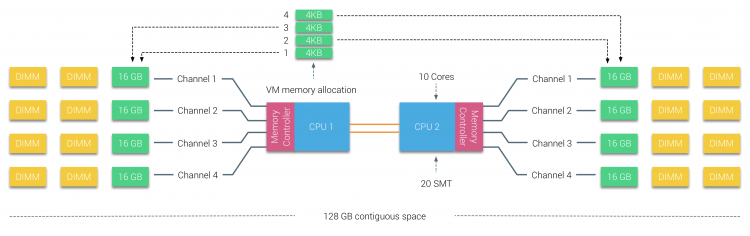
az érdekes dolog az, hogy a SUMA rendszer egységes memória hozzáférési időt biztosít. Csak nem a legoptimálisabb, és erősen függ a QPI architektúra vitaszintjeitől. Az Intel Memory Latency Checker-t arra használták, hogy bemutassák a numa és a SUMA konfigurációja közötti különbségeket ugyanazon a rendszeren.
ez a teszt méri az üresjárati késleltetést (nanoszekundumban) az egyes aljzatoktól a rendszer másik aljzatáig. A 0 memóriacsomag 0 által jelentett késleltetés a helyi memóriahozzáférés, a memória-hozzáférés az 1 memóriacsomag 0 aljzatából távoli memóriahozzáférés a numa-ként konfigurált rendszerben.
| NUMA | memória csomópont 0 | memória csomópont 1 | – | SUMA | memória csomópont 0 | memória csomópont 1 |
| Socket 0 | 75.7 | 132.0 | – | foglalat 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
a várakozásoknak megfelelően az interleaving hatással van a QPI kapcsolatok állandó áthaladására. A tétlen memória teszt a legjobb eset, egy érdekesebb teszt a betöltött késések mérése. Rossz befektetés lett volna, ha az ESXi szerverei alapjáraton vannak, ezért feltételezheti, hogy egy ESXi rendszer feldolgozza az adatokat. A betöltött késleltetések mérése jobb betekintést nyújt a rendszer normál terhelés alatt történő teljesítésébe. A vizsgálat során a terhelés befecskendezésének késleltetése 2 másodpercenként automatikusan megváltozik, és mind a sávszélességet, mind a megfelelő késleltetést ezen a szinten mérik. Ez a teszt 100% – os olvasási forgalmat használ.A numa teszt eredményei a bal oldalon, a SUMA teszt eredményei a jobb oldalon.
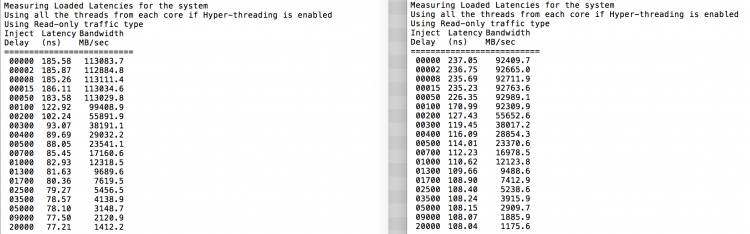
a Suma rendszer jelentett sávszélessége alacsonyabb, miközben magasabb késleltetést tart fenn, mint a NUMA-ként konfigurált rendszer. Ezért a virtuális gép méretének optimalizálására kell összpontosítani a rendszer NUMA jellemzőinek kihasználása érdekében.
Nehalem & Core mikroarchitektúra áttekintés
a Nehalem mikroarchitektúra 2008-as bevezetésével az Intel eltávolodott a Netburst architektúrától. A Nehalem mikroarchitektúra bemutatta az Intel ügyfeleit a NUMA – nak. Az évek során az Intel új mikroarchitektúrákat és optimalizálásokat vezetett be, a híres Tick-Tock modell szerint. Minden pipával optimalizálás történik, a folyamat technológia zsugorítása és minden egyes Tockkal egy új mikroarchitektúra kerül bevezetésre. Annak ellenére, hogy az Intel 2012 óta következetes márkamodellt kínál, az emberek hajlamosak az Intel architektúra kódneveire, hogy megvitassák a CPU tick and tock generációkat. Még az EVC alapvonalai is felsorolják ezeket a belső Intel kódneveket, mind a márkaneveket, mind az építészeti kódneveket ebben a sorozatban használják:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tak | 22nm |
| Broadwell | E5 – 26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Pipa | 14 nm |
következő rész: 2. rész: rendszerarchitektúra
a 2016-os Numa mély merülési sorozat:
0. rész: Bevezetés NUMA mély merülési sorozat
1. rész: UMA-tól NUMA-ig
2. rész: rendszerarchitektúra
3. rész: gyorsítótár koherencia
4. rész: helyi memória optimalizálás
5. rész: ESXi VMkernel NUMA konstrukciók