rejtett Markov-modell (Hmm) egy statisztikai Markov-modell amelyben a modellezett rendszert feltételezzük, hogy a Markov-folyamat megfigyeletlen (azaz rejtett) állapotokkal.
a rejtett Markov modellek különösen ismertek a megerősítéses tanulásban és az időbeli mintafelismerésben való alkalmazásukról, mint például a beszéd, a kézírás, a gesztusfelismerés, a beszédrész-címkézés, a kotta követése, a részleges kisülések és a bioinformatika.
terminológia a HMM-ben
a rejtett kifejezés a megfigyelés mögött álló elsőrendű Markov-folyamatra utal. A megfigyelés azokra az adatokra vonatkozik, amelyeket ismerünk és megfigyelhetünk. A Markov-folyamatot az “esős” és a “napos” közötti kölcsönhatás mutatja az alábbi ábrán, és ezek mindegyike Rejtett állapot.

a megfigyelések ismert adatok, és a fenti ábrán a “séta”, “bolt” és “tiszta”. Gépi tanulási értelemben a megfigyelés a képzési adataink, a rejtett állapotok száma pedig a modellünk hiperparamétere. A modell értékelését később tárgyaljuk.

T = még nincs megfigyelés, N = 2, M = 3, Q = {“esős”, “napos”}, V = {“séta”, “bolt”, “tiszta”}
az állapotátmeneti valószínűségek az egyes rejtett állapotokra mutató nyilak. A megfigyelési valószínűségi mátrix a kék és a piros nyilak, amelyek az egyes rejtett állapotokból származó megfigyelésekre mutatnak. A mátrix sor sztochasztikus, vagyis a sorok összeadódnak 1.


a mátrix elmagyarázza, hogy mekkora a valószínűsége annak, hogy egyik állapotból a másikba megy, vagy egyik állapotból a megfigyelésbe megy.
a kezdeti állapoteloszlás a modellt egy rejtett állapotból kiindulva indítja el.
teljes modell ismert állapotátmeneti valószínűségekkel, megfigyelési valószínűségi mátrixszal és kezdeti állapoteloszlással,
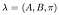
hogyan építhetjük fel a fenti modellt Pythonban?
a fenti esetben a kibocsátás diszkrét {“Walk”, “Shop”, “Clean”}. A fenti modellhez a hmmlearn könyvtár MultinomialHMM-jét használjuk. A GaussianHMM és a GMMHMM más modellek a könyvtárban.
most a HMM milyen kulcsfontosságú problémákat kell megoldani?
- 1. probléma, ismert modell alapján mekkora az O sorozat valószínűsége?
- 2. probléma, ismert modell és O szekvencia esetén mi az optimális Rejtett állapot szekvencia? Ez akkor lesz hasznos, ha tudni akarjuk, hogy az időjárás “esős” vagy “napos”
- 3. probléma, adott o szekvencia és a rejtett állapotok száma, mi az optimális modell, amely maximalizálja az O valószínűségét?
1. probléma Pythonban
az első megfigyelés “séta” valószínűsége megegyezik a kezdeti állapoteloszlás és emissziós valószínűségi mátrix szorzatával. 0, 6 x 0, 1 + 0, 4 x 0, 6 = 0, 30 (30%). A napló valószínűsége a hívásból származik .pont.
2. probléma Pythonban

figyelembe véve az ismert modellt és a megfigyelést {“Shop”, “Clean”, “Walk”}, az időjárás valószínűleg {“Rainy”, “Rainy”, “Sunny”} volt ~1,5% valószínűséggel.
az ismert modell és a {“Clean”, “Clean”, “Clean”} megfigyelés alapján az időjárás valószínűleg {“Rainy”, “Rainy”, “Rainy”} volt, ~3,6% valószínűséggel.
intuitív módon, amikor “séta” történik, az időjárás valószínűleg nem lesz “esős”.
3. probléma a Pythonban
beszédfelismerés hangfájllal: jósolja meg ezeket a szavakat

amplitúdó lehet használni, mint a megfigyelés HMM, de feature engineering ad nekünk nagyobb teljesítményt.

funkció stft és peakfind generál funkció audio jelet.
a fenti példát innen vettük. Kyle Kastner épített HMM osztály, amely úgy 3D tömbök, én használ hmmlearn amely csak lehetővé teszi 2d tömbök. Ezért csökkentem a Kyle Kastner által generált funkciókat X_test néven.átlag (tengely=2).
ennek a modellezésnek a megértése sok időt vett igénybe. Az volt a benyomásom, hogy a célváltozónak a megfigyelésnek kell lennie. Ez igaz az idősorokra. Az osztályozás úgy történik, hogy minden osztályra hmm-t építünk, és összehasonlítjuk a kimenetet a bemenet logprobjának kiszámításával.
matematikai megoldás az 1. problémára: előre algoritmus

az Alpha pass a megfigyelés és az állapot szekvencia adott modell valószínűsége.
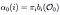
Alfa pass időben (t) = 0, kezdeti állapot Eloszlás i és onnan az első megfigyelés O0.
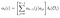
Alfa pass idején (t) = t, összege utolsó alfa pass minden rejtett állapotban szorozva emisszió Ot.
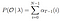
matematikai megoldás a 2. problémára: Visszafelé algoritmus


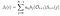

adott modell és megfigyelés, valószínűsége, hogy az állam qi időben t.
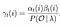
matematikai megoldás a 3. problémára: Előre-hátra algoritmus


valószínűsége az állam qi qj időben t adott modell és megfigyelés
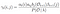
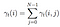
az összes átmenet valószínűségének összege i – től j-ig.
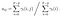
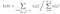
az átmeneti és emissziós valószínűségi mátrixot di-gammával becsüljük meg.
iteráció, ha a P(O|modell) valószínűsége növekszik