内部リンクとは何ですか?
内部リンクは、リンクが存在するドメイン(ソース)と同じドメイン(ターゲット)を指すハイパーリンクです。 素人の言葉では、内部リンクは、同じウェブサイト上の別のページを指すものです。
コードサンプル
<a href="http://www.same-domain.com/" title="Keyword Text">Keyword Text</a>
最適な形式
ソースページがターゲットにしようとしているトピックやキーワードの感覚を与えるアンカーテキストで説明的なキーワードを使
内部リンクとは何ですか?
内部リンクは、ドメイン上のあるページから同じドメイン上の別のページに移動するリンクです。 それらは主なナビゲーションに一般的に使用されています。
これらのタイプのリンクは、三つの理由で有用です:
- ユーザーがwebサイトをナビゲートできるようにします。
- 指定されたウェブサイトの情報階層を確立するのに役立ちます。
- それらはウェブサイトのまわりでリンク公平(ランキング力)を広げるのを助ける。
SEOのベストプラクティス
内部リンクは、サイトアーキテクチャを確立し、リンクエクイティを広めるために最も有用です(Urlも不可欠です)。 このため、このセクションでは、内部リンクを使用してSEOに優しいサイトアーキテクチャを構築するこ
個々のページでは、検索エンジンは膨大なキーワードベースのインデックスでページを一覧表示するためにコンテンツを表示する必要があります。 それらはまたcrawlableリンク構造へのアクセスがある必要がある—くもがウェブサイトの細道を拾い読みすることを可能にする構造—ウェブサイトのペー 何十万もの場所は調査エンジンがアクセスできない方法で主要なリンク運行を隠すか、または埋めることの重大な間違いを作る。 これは調査エンジンの索引にリストされているページを得る機能を妨げる。 以下は、この問題がどのように発生するかを示しています:
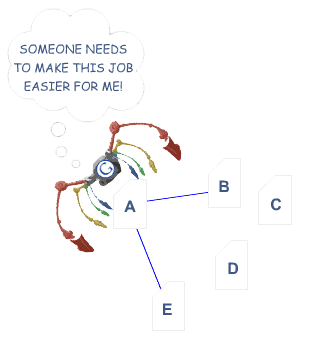
上記の例では、Googleの多彩なくもはページ”A”に達し、ページ”B”および”E.”への内部リンクを見る重要なページCおよびDが場所にあるかもしれないどんなに、くもにそれらに達する方法がない—また更にそれらが存在することを知っている—直接、crawlableリンクがそれらのページを指しないので。 Googleが懸念している限りでは、これらのページは基本的に存在しない–くもが最初の場所のそれらのページに達することができなければ大きい内容、よいキーワー
ウェブサイトの最適な構造はピラミッドに似ています(上部の大きな点がホームページです):
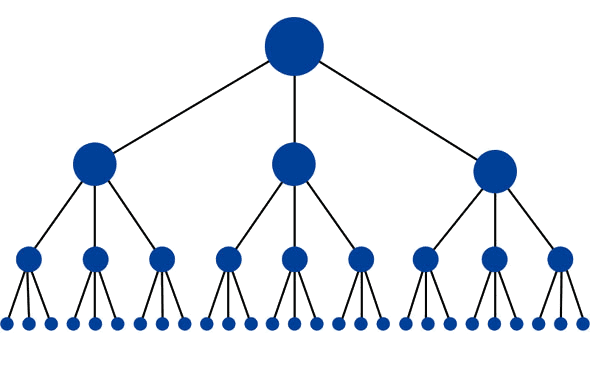
この構造は、ホームページと任意のページとの間で可能なリンクの最小量を持っています。 これはリンク公平(ランキング力)が全体の場所中流れるようにする従って各ページのためのランキングの潜在性を高めるので有用である。 この構造は、多くのパフォーマンスの高いwebサイト(以下のようなもの)で一般的ですAmazon.com)カテゴリとサブカテゴリーシステムの形で。
しかし、これはどのように達成されますか? これを行う最善の方法は、内部リンクと補足URL構造を使用することです。 たとえば、http://www.example.com/mammalsにあるページに内部的にリンクします。.. アンカーテキストで”猫。”以下は、正しくフォーマットされた内部リンクの形式です。 このリンクがドメインにあると想像してくださいjonwye.com…..

上の図では、”a”タグはリンクの開始を示しています。 リンクタグには、画像、テキスト、またはその他のオブジェクトを含めることができ、それらはすべて、ユーザーが別のページに移動するために従事できるペー これはインターネットの元の概念である:”ハイパーリンク。”リンク紹介の場所は、ブラウザと検索エンジンにリンクが指す場所を伝えます。 この例では、URL<9 3 8>が参照される。 次に、SEOの世界の”アンカーテキスト”と呼ばれる訪問者のためのリンクの目に見える部分はリンクが指しているページを記述する。 この例では、jon Wyeという名前の男によって作られたカスタムベルトに関するページであるため、リンクはアンカーテキスト”Jon Wye’s Custom Designed Belts”を使用します。”</a>タグはリンクを閉じるので、ページの後の要素にはlink属性が適用されません。
これはリンクの最も基本的な形式であり、検索エンジンにとって非常に理解しやすいものです。 検索エンジンのスパイダーは、このリンクをウェブのエンジンのリンクグラフに追加し、それを使用してクエリに依存しない変数(MozRankなど)を計算し、それ
以下に、ページに到達できない可能性があるため、インデックス化されない可能性がある一般的な理由をいくつか示します。
提出必須フォームのリンク
フォームには、ドロップダウンメニューのような基本的な要素や、本格的な調査のような複雑な要素を含めることができます。 いずれの場合も、調査のくもは形態を”堤出”するように試みないし、こうして、形態によって入手しやすいリンクか内容はエンジンに見えない。
内部検索ボックスを介してのみアクセス可能なリンク
スパイダーはコンテンツを見つけるために検索を実行しようとしないため、何百万ページものページが完全にアクセスできない内部検索ボックスの壁の後ろに隠されていると推定されています。
解析不可能なJavascriptのリンク
Javascriptを使用して構築されたリンクは、実装に応じて、クロールできないか、重みが切り下げられる可能性があります。 このため、検索エンジンが参照するトラフィックが重要なページでは、Javascriptベースのリンクの代わりに、標準のHTMLリンクを使用することをお勧めします。
Flash、Java、その他のプラグイン内のリンク
Flash、Javaアプレット、その他のプラグイン内に埋め込まれたリンクは、通常、検索エンジンにアクセスできません。
Meta RobotsタグまたはRobotsによってブロックされたページを指すリンク。txt
メタロボットタグとロボット。txtファイルは、両方のサイトの所有者は、ページへのスパイダーのアクセスを制限することができます。
数百または数千のリンクを持つページへのリンク
検索エンジンはすべて、元のページからリンクされた追加のページをスパイダーするのを止める前に、ページあたり150リンクの大まかなクロール制限を持っています。 この制限はやや柔軟性があり、特に重要なページには200または250のリンクが続く場合がありますが、一般的には、特定のページのリンク数を150に制限するか、追加のページをクロールする能力を失う危険性があることが賢明です。
フレームまたはIフレーム内のリンク
技術的には、フレームとIフレームの両方のリンクはクロール可能ですが、どちらも組織とフォローの面でエンジンに構造的な問題を提示しています。 検索エンジンのインデックスとフレーム内のリンクのフォロー方法を技術的に理解している上級ユーザーのみが、これらの要素を内部リンクと組み合
これらの落とし穴を避けることによって、ウェブマスターはくもに満足なページへの容易なアクセスを可能にするきれいな、spiderable HTMLリンクを持つことがで リンクには追加の属性を適用することができますが、エンジンはこれらのほとんどすべてを無視しますが、rel="nofollow"タグは重要な例外です。
あなたのサイトのインデックス化を簡単に垣間見ることをしたいですか? Moz Pro、Link Explorer、Screaming Frogなどのツールを使用して、サイトクロールを実行します。 次に、googleでsite:searchを実行したときにクロールされたページ数と表示されたページ数を比較します。
Rel=”nofollow”は、次の構文で使用できます:
<pre><a href=”/”rel=”nofollow”>nofollow this link</a></pre>
この例では、リンクタグにrel="nofollow"属性を追加することにより、ウェブマスターは検索エンジンにこのリンクを通常のジュースパスとして解釈したくない”と編集部の投票。”Nofollowは自動化されたblogのコメント、ゲストブック、およびリンク注入のスパムを停止するのを助ける方法として約来たが、通常渡されるリンク価値を割り引くようにエンジンに言う方法に時間をかけて変形した。 Nofollowでタグ付けされたリンクは、各エンジンによってわずかに異なる解釈がされます。
学び続ける
- アンカーテキスト
- リンク公平
- ウェブマスターの指針ウェブマスターのためのGoogleの公式の指針。
- テキストリンクとPageRank GoogleのWebspamチームの元ヘッド、Matt Cutts’、SEOとGoogleに関連したハイパーリンクに関する考え。