区分的回帰は、データセットをモデル化するのに1本の線では不十分な場合に発生する特殊なタイプの線形回帰です。 区分的回帰は、ドメインを潜在的に多くの”セグメント”に分割し、それぞれを介して別々の線を適合させます。 たとえば、以下のグラフでは、1本の線ではデータをモデル化できず、3本の線で区分的回帰もモデル化できません:
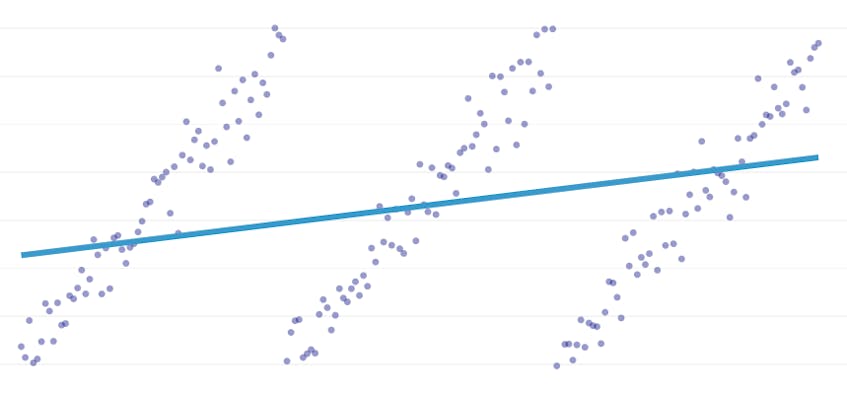
この記事では、時系列データの区分的回帰を自動化するためのDatadogのアプローチを紹介します。
目的
区分的回帰は、異なる文脈でわずかに異なることを意味することができるので、区分的回帰アルゴリズムで達成しようとしている正確に何を明確にするために時間を割いてみましょう。
自動ブレークポイント検出。 古典的な統計学の文献では、区分的回帰は、手動回帰分析作業中にしばしば示唆され、ある線形傾向が別の線形傾向に移行することは肉眼では明らかで その場合、人間は区分的セグメント間のブレークポイントを指定し、データセットを分割し、各セグメントに対して独立して線形回帰を実行できます。 私たちのユースケースでは、毎秒数百回の回帰を行いたいのですが、人間がすべてのブレークポイントを指定することは現実的ではありません。 代わりに、区分的回帰アルゴリズムが独自のブレークポイントを識別するという要件があります。
自動セグメント数検出。 データセットが正確に2つのセグメントを持っていることを知っていれば、可能なセグメントのペアのそれぞれを簡単に見ることができます。 しかし、実際には、任意の時系列が与えられた場合、複数のセグメントまたは3または4または5未満でなければならないと信じる理由はありません。 このアルゴリズムは,ユーザが指定することなく適切な数のセグメントを選択する必要がある。
連続性の要件はありません。 区分的回帰のためのいくつかの方法は、各セグメントの終了点が次のセグメントの開始点である連結セグメントを生成します。 このアルゴリズムにはそのような要件は課していません。
課題
自動ブレークポイント検出による区分的回帰を実装するための最も明白な課題は、解探索空間のサイズが大きいことです。 時系列をセグメントに分割することができる方法の数は、時系列の長さにおいて指数関数的である。 動的プログラミングは、単純なブルートフォース実装よりもはるかに効率的にこの検索空間を横断するために使用できますが、実際にはまだ遅すぎます。 検索空間の広い領域をすばやく破棄するには、貪欲なヒューリスティックが必要です。
もっと微妙な課題は、ある解決策の品質を別の解決策と比較する方法が必要であるということです。 私たちのバージョンの問題では、セグメントの数と場所が不明な場合、セグメントの数とブレークポイントが異なる潜在的な解決策を比較する必要が 私たちは二つの競合する目標のバランスを取ろうとしています:
- エラーを最小限に抑えます。 つまり、各セグメントの回帰線を観測されたデータポイントに近づけるようにします。
- データを適切にモデル化するセグメントの最小数を使用します。 各点に1つのセグメント(または2点ごとに1つのセグメント)を作成することで、常にエラーがゼロになる可能性があります。 タイムスタンプとそれに関連するメトリック値の一般的な関係については何も学ばず、結果を内挿や外挿に簡単に使用することはできませんでした。
私たちの解
私たちは、区分的回帰問題のために、次の貪欲アルゴリズムを使用します:
- n/2セグメントを使用して区分的回帰を行います。nは時系列の観測値の数です。 各セグメントの回帰直線は、通常の最小二乗(OLS)回帰を使用して近似されます。 この最初の区分的回帰には誤差はほとんどありませんが、データセットに深刻なオーバーフィットが発生します。
- 繰り返し、セグメントが一つだけになるまで:
- 隣接するセグメントのすべてのペアについて、二つのセグメントが結合され、それらの二つの回帰線が単一の回帰線に置き換えられた場合に生じる総誤差の増加を評価する。
- 誤差が最小に増加するセグメントのペアをマージします。
- このマージを実行することが停止基準(以下で定義)を満たしている場合、分離したままにする必要がある二つのセグメントをマージしすぎている可能性があります。 このような場合は、この反復のマージ前のセグメントの状態を覚えておいてください。
- マージによって上記の(2c)のセグメントの状態が記憶されない場合、最良の解決策は一つの大きなセグメントです。 それ以外の場合は、(2c)で記憶される最後のセグメント状態が最良の解決策です。
停止基準
マージが前のマージよりも二乗誤差の合計を増加させる場合、マージは潜在的な停止点であると考えます。 セグメントが1つだけである必要がある場合にあまりにも早く停止するのを防ぐために、マージが1つのセグメントを持つ回帰の総誤差の3%未満の総誤差の増加をもたらさない限り、マージが潜在的な停止点であるとはみなされません。 (3%は任意のしきい値ですが、実際にはうまく機能することがわかりました。)以下は、この停止基準が機能する理由を示すためのいくつかの例です。
まず、単線に沿った点に正規分布ノイズを追加して生成されたデータセットを見てみましょう。 アルゴリズムは、このデータセットを介して単一のセグメントだけを正しく適合させます。
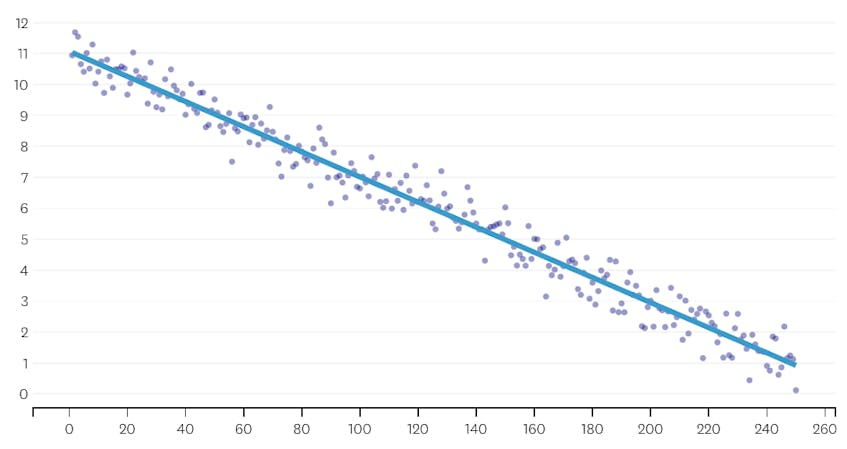
この場合、マージは二乗誤差の合計を3%以上増加させません。 したがって、マージは適切な停止点とはみなされず、すべてのマージが実行された後に最終状態を使用します。 下のプロットでは、後でマージすると以前のマージよりも多くのエラーが発生する傾向があります(それぞれがより多くのポイントに影響するため理にか
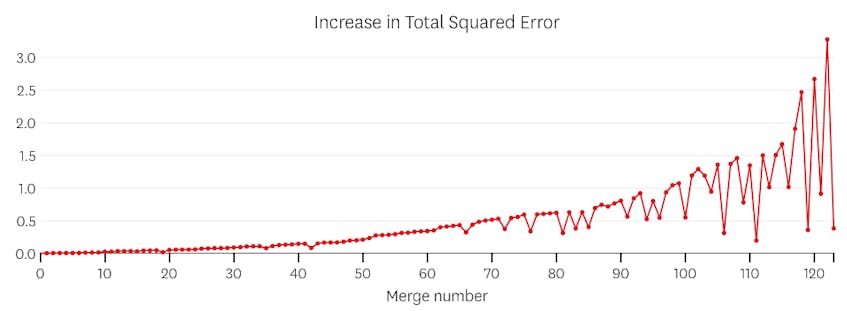
次に、データセットに7つの異なるセグメントがある例を見てみましょう。
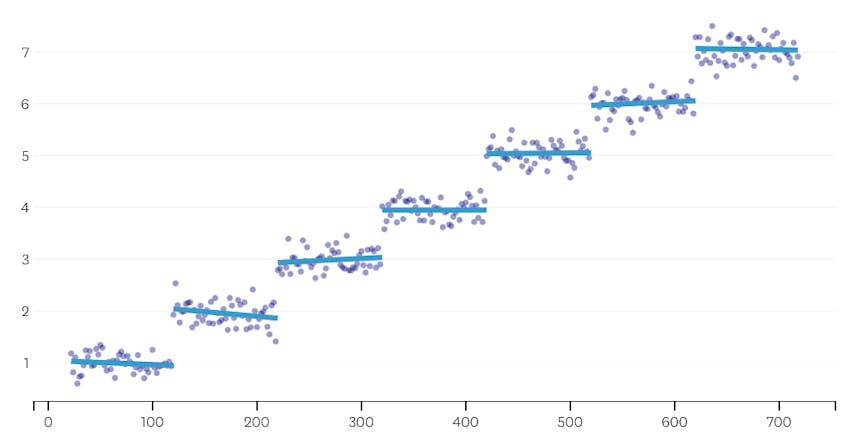
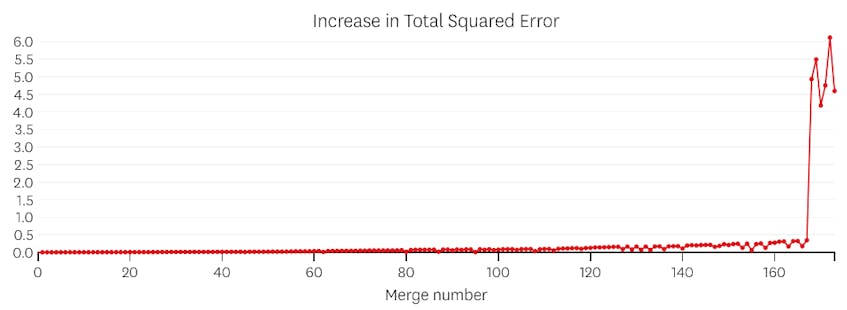
この場合、各マージによって導入されたエラーのプロットを見ると、最後の6つのマージでは、以前のマージよりもはるかに多くのエラーが導入されています。 したがって、我々のアルゴリズムは、6番目から最後までのマージ前のセグメントの状態を記憶し、それを最終的な解決策として使用しました。
コード
Datadog/piecewise Github repoには、アルゴリズムのPython実装があります。 一連のデータが与えられた場合、適合された各セグメントの位置と回帰係数が返されます。piecewise()関数は、重いリフティングが発生する場所です。
も要点に含まれていますplot_data_with_regression()—迅速かつ簡単にプロットするためのラッパー関数です。 これがどのように使用されるかの簡単な例:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)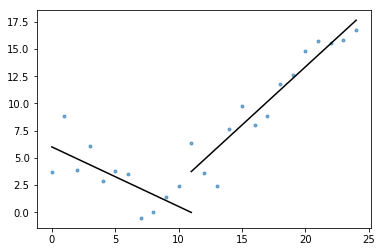
この実装ではOLS線形回帰を使用しますが、関連する問題を解決するために同じフレームワークを適応させることができます。 二乗誤差を絶対誤差またはヒューバー損失に置き換えることにより、回帰をロバストにすることができます。 または、各セグメントにそのドメイン内の観測値の平均に等しい定数値を割り当てることによって、ステップ関数を近似することができます。