このチュートリアルでは、Mikolovらによって提案されたWord2Vecと呼ばれる新興で著名な単語埋め込み技術の一つを説明しようとしています。 2013年に。 私たちは、単一の場所で読者を容易にするために、さまざまなチュートリアルやソースからこれらのコンテンツを収集しています。 私はそれが役立つことを願っています。
Word2Vecは、コーパスC内の単語の分散表現を表すために使用されるモデルの組み合わせです。Word2Vec(W2V)は、下の図に示すように、テキストコーパスを入力とし、各単語のベクトル表現を出力するアルゴリズムです:

このアルゴリズムには、CBOWとSkip-Gramの2つのフレーバーがあります。 一連の文(コーパスとも呼ばれる)が与えられた場合、モデルは各文の単語をループし、現在の単語wを使用してその隣接語(すなわちその文脈)を予測しようとするか、このアプローチは”Skip-Gram”と呼ばれるか、またはこれらのコンテキストのそれぞれを使用して現在の単語wを予測するために、その場合、メソッドは”Continuous Bag Of Words”(CBOW)と呼ばれる。 各コンテキスト内の単語の数を制限するために、”ウィンドウサイズ”と呼ばれるパラメータが使用されます。

単語を表現するために使用するベクトルは神経語埋め込みと呼ばれ、表現は奇妙です。 これら二つのことは根本的に異なっているにもかかわらず、一つのことは、別のものを説明しています。 エルヴィス-コステロが言ったように:”音楽について書くことは、建築について踊るようなものです。”Word2vec”は単語について”ベクトル化し、そうすることによって自然言語をコンピュータで読みやすくします。
だから、ニューラルワード埋め込みは、数字を持つ単語を表します。 これは、単純な、まだありそうもない、翻訳です。 Word2vecはオートエンコーダーに似ており、各単語をベクトルでエンコードしますが、制限されたボルツマンマシンが行うように、word2vecは入力コーパス内で隣接する他の単語に対して単語を訓練します。
これは、contextを使用してターゲット単語を予測する方法(continuous bag of words、またはCBOWとして知られている方法)、またはskip-gramと呼ばれるターゲットコンテキストを予測するために単語を使用する方法のいずれかでこれを行います。 後者の方法は、大規模なデータセットでより正確な結果が得られるためです。

単語に割り当てられた特徴ベクトルを使用してその単語のコンテキストを正確に予測できない場合、ベクトルの成分が調整されます。 コーパス内の各単語のコンテキストは、教師が特徴ベクトルを調整するためにエラー信号を送り返すことです。 文脈によって類似していると判断された単語のベクトルは、ベクトル内の数字を調整することによって、より近くにナッジされます。 このチュートリアルでは、上の図に示すように、CBOWとは対照的に、センターワードを入力として考慮し、コンテキストワードを予測するSkip-Gramモデルに焦点を当て
モデルの概要
私たちは、いくつかの奇妙なニューラルネットワークにいくつかの単語のペアを与えなければならないことを理解しましたが、実際の文字を入力として使用してそれを行うことはできません。 これを行う1つの方法は、テキスト内のすべての単語の語彙を作成し、単語を語彙の同じ次元のベクトルとしてエンコードすることです。 各次元は、私たちの語彙の中の単語として考えることができます。 したがって、すべてのゼロを持つベクトルと、語彙内の対応する単語を表す1があります。 この符号化技術は、ワンホットエンコーディングと呼ばれています。 私たちの例を考えると、”the”、”quick”、”brown”、”fox”、”jumps”、”over”、”the”、”lazy”、”dog”という単語から作られた語彙がある場合、”brown”という単語は次のベクトルで表されます。

Skip-gramモデルは、テキストのコーパスを取り込み、各単語のホットベクトルを作成します。 ホットベクトルは、単語のベクトル表現であり、ベクトルは語彙のサイズ(一意の単語の合計)です。 すべての次元は、その時点で入力として使用される単語を表す次元を除いて0に設定されます。 ホットベクトルの例を次に示します:

上記の入力は、単一の隠れ層を持つニューラルネットワークに与えられます。
“ants”のような入力単語をワンホットベクトルとして表現します。 このベクトルは10,000個のコンポーネント(語彙内のすべての単語に1つ)を持ち、単語”ants”に対応する位置に”1″を配置し、他のすべての位置に0を配置します。 ネットワークの出力は、私たちの語彙のすべての単語について、ランダムに選択された近くの単語がその語彙単語である確率を含む単一のベクトル(10,000
word2vecでは、単語の分散表現が使用されます。 数百次元(例えば1000)のベクトルを取る。 各単語は、これらの要素間の重みの分布によって表されます。 したがって、ベクトル内の要素と単語との間の一対一のマッピングの代わりに、単語の表現はベクトル内のすべての要素に広がり、ベクトル内の各要素は多くの単語の定義に寄与します。
仮説的な単語ベクトルで次元にラベルを付けると(もちろんアルゴリズムにそのような事前に割り当てられたラベルはありません)、次のようにな:

そのようなベクトルは、単語の「意味」を抽象的な方法で表現するようになります。 そして、我々は次のように、単に大きなコーパスを調べることによって、それは驚くほど表現力豊かな方法で単語間の関係をキャプチャすることができ また、ベクトルをニューラルネットワークへの入力として使用することもできます。 入力ベクトルは1ホットであるため、入力ベクトルに重み行列W1を乗算すると、W1から行を選択するだけになります。
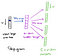

隠れ層から出力層まで、第2の重み行列W2は、語彙内の各単語のスコアを計算するために使用され、softmaxは、単語の事後分布を得るために使用され得る。 Skip-gramモデルはCBOWモデルの反対です。 これは、単一の入力ベクトルとしてフォーカスワードを使用して構築され、ターゲットコンテキストワードは出力レイヤになりました。 隠れ層の活性化関数は、前に見たように、重み行列W1(linear)から対応する行をコピーすることになります。 出力層では、1つだけではなくCの多項分布を出力します。 学習の目的は、出力層内のすべてのコンテキストワードにわたって合計された予測誤差を最小化することです。 この例では、入力は「学習」であり、出力層で(「an」、「efficient」、「method」、「for」、「high」、「quality」、「distributed」、「vector」)を見ることを願っています。
ここに私たちのニューラルネットワークのアーキテクチャがあります。

この例では、300の特徴を持つ単語ベクトルを学習していると言います。 したがって、隠された層は、10,000行(私たちの語彙のすべての単語に1つ)と300列(隠されたニューロンごとに1つ)の重み行列で表されます。 300の機能は、Googleニュースデータセットで訓練された公開モデルでGoogleが使用したものです(ここからダウンロードできます)。 機能の数は、アプリケーションに合わせて調整するだけの”ハイパーパラメータ”です(つまり、異なる値を試して、最良の結果が得られるものを確認します)。
この重み行列の行を見ると、これらは私たちの単語ベクトルになります!

だから、このすべての最終目標は、実際にはこの隠された層の重み行列を学ぶことです—出力層は、私たちが完了したらちょうど投げるでしょう! その後、”蟻”の1×300ワードベクトルが出力層に供給されます。 出力層はsoftmax回帰分類器です。 具体的には、各出力ニューロンは、隠れ層からの単語ベクトルに対して乗算する重みベクトルを持ち、関数exp(x)を結果に適用します。 最後に、出力を合計して1にするために、この結果を10,000個のすべての出力ノードからの結果の合計で除算します。 ここでは、”car”という単語の出力ニューロンの出力を計算する図を示します。

二つの異なる単語が非常に類似した”コンテキスト”を持っている場合(つまり、どの単語がそれらの周りに現れる可能性が高いか)、私たちのモデルは、こ ネットワークがこれら2つの単語に対して同様の文脈予測を出力する1つの方法は、単語ベクトルが類似している場合です。 したがって、二つの単語が同様の文脈を持っている場合、私たちのネットワークは、これら二つの単語のための同様の単語ベク タダ!
入力の各次元は、隠れ層の各ノードを通過します。 ディメンションには、非表示レイヤーにつながるウェイトが乗算されます。 入力はホットベクトルであるため、入力ノードの1つだけがゼロ以外の値(つまり1の値)を持ちます。 これは、上の画像に示すように、単語の場合、値1の入力ノードに関連付けられた重みのみがアクティブになることを意味します。
この場合の入力はホットベクトルであるため、入力ノードの1つだけがゼロ以外の値を持ちます。 これは、その入力ノードに接続されているウェイトのみが非表示ノードでアクティブ化されることを意味します。 考慮される重みの例は、語彙の第二の単語について以下に示されています:
語彙の第二の単語のベクトル表現(上記のニューラルネットワークに示されてい:
これらの重みはランダムな値として始まります。 次に、入力単語を表すように重みを調整するために、ネットワークを訓練します。 ここで、出力層が重要になります。 単語のベクトル表現を持つ隠れ層にいるので、単語が特定のコンテキストに収まることをどれだけ予測しているかを判断する方法が必要です。 単語のコンテキストは、以下に示すように、その周りのウィンドウ内の単語のセットです:

上の画像は、金曜日のコンテキストに”cat”や”is”のような単語が含まれていることを示しています。 ニューラルネットワークの目的は、”金曜日”がこの文脈の中にあることを予測することです。
hidden layerを通過したベクトル(hidden nodeに入る入力hot vector*weights)に、context wordのベクトル表現(出力ノードに入るcontext word*weightsのホットベクトル)を乗算することにより、出力レ 最初のコンテキストワードの出力レイヤーの状態は、以下で視覚化できます:

上記の乗算は、各単語からコンテキスト単語のペアに対して行われます。 次に、隠された層と出力層から得られる値を使用して、単語がコンテキスト単語のセットに属する確率を計算します。 最後に,計算された確率に対してより望ましい値を得るために,確率的勾配降下法を適用して重みの値を変更した。
勾配降下法では、変化している重みを表す点で最適化されている関数の勾配を計算する必要があります。 次に、勾配を使用して、以下の最小化の例に示すように、局所的な最適値に向かって移動するステップを作成する方向を選択します。
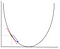
重みは、最適な点(上記の例では、グラフ内の最低点)の方向にステップを行うことによって変更されます。 新しい値は、現在の重み値から、学習率によってスケーリングされた重みの点で導出された関数を減算することによって計算されます。 次のステップは、複数のレイヤー間の重みを調整するために、逆伝播を使用しています。 出力レイヤーの最後で計算された誤差は、チェーンルールを適用することによって、出力レイヤーから非表示レイヤーに戻されます。 勾配降下法は、これら2つのレイヤー間の重みを更新するために使用されます。 エラーは、各レイヤーで調整され、さらに送り返されます。 ここでは、逆伝播を表す図です:

例
を使用した理解Word2Vecは、以下に示すように、単一の隠れ層、完全に接続されたニューラルネットワークを使用します。 隠された層のニューロンはすべて線形ニューロンです。 入力層は、訓練のための語彙に単語があるのと同じくらい多くのニューロンを持つように設定されています。 隠れ層のサイズは、結果として得られる単語ベクトルの次元に設定されます。 出力層のサイズは入力層と同じです。 このように、単語ベクトルを学習するための語彙がV個の単語とn個の単語ベクトルの次元で構成されている場合、隠れ層接続への入力は、サイズVxn 同様に、隠れ層から出力層への接続は、サイズNxVの行列WOによって記述することができる。 この場合、WO行列の各列は、与えられた語彙からの単語を表す。

ネットワークへの入力は、1つの入力ラインのみが1に設定され、残りの入力ラインがゼロに設定されることを意味する”1-out of-V”表現を使用してエンコー
次の文章を持つトレーニングコーパスがあるとします。
“犬は猫を見た”、”犬は猫を追いかけた”、”猫は木に登った”
コーパス語彙は八つの単語を持っています。 アルファベット順に並べ替えると、各単語はそのインデックスで参照できます。 この例では、ニューラルネットワークには8つの入力ニューロンと8つの出力ニューロンがあります。 隠された層に三つのニューロンを使用することにしたと仮定しましょう。 これは、W iおよびWOがそれぞれ8×3および3×8の行列であることを意味する。 学習を開始する前に、これらの行列は、ニューラルネットワークの学習で通常のように小さなランダムな値に初期化されます。 説明のために、WIとWOが次の値に初期化されると仮定しましょう:

我々は、ネットワークが単語”猫”と”登った”との関係を学習したいとします。 つまり、ネットワークに”cat”が入力されたときに、ネットワークは”上昇”の確率が高いはずです。 単語の埋め込み用語では、単語”cat”は文脈語と呼ばれ、単語”climbed”はターゲット語と呼ばれます。 ベクトルの2番目の成分のみが1であることに注意してください。 これは、入力単語がコーパス単語のソートされたリスト内の2番目の位置を保持している”cat”であるためです。 入力ベクトルが”cat”を表す場合、隠れ層ニューロンの出力は次のように計算できます。
Ht=XtWI=
隠れ層ニューロンの出力のベクトルHが、1-out-of-Vrepresentationのため、WI行列の二行目の重みを模倣することは驚くべきことではありません。 したがって、非表示層接続への入力の機能は、基本的に入力ワードベクトルを非表示層にコピーすることです。 出力層のニューロンの活性化ベクトルは
HtWO=
と書くことができます。目標は、出力層の単語の確率を生成することです。Pr(wordk|wordcontext)for k=1,Vは、入力時のコンテキストワードとの次の単語の関係を反映するために、出力層のニューロン出力の合計を加算する必要があります。 Word2vecは、出力層ニューロンの活性化値を関数softmaxを使用して確率に変換することによってこれを実現します。 したがって、k番目のニューロンの出力は、次の式によって計算されます。activation(n)は、n番目の出力層ニューロンの活性化値を表します:
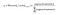
したがって、コーパス内の八つの単語の確率は次のとおりです:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
太字の確率は、選択されたターゲット単語”登った”の確率です。 ターゲットベクトルtが与えられると、出力層の誤差ベクトルは、ターゲットベクトルから確率ベクトルを減算することによって容易に計算されます。 誤差が判明すると、行列WOおよびWIの重みは、逆伝播を使用して更新することができる。 このように,コーパスから異なる文脈-対象単語ペアを提示することにより,訓練を進めることができる。 これは、Word2Vecが単語間の関係を学習し、その過程でコーパス内の単語のベクトル表現を開発する方法です。
word2vecの背後にある考え方は、d次元の実数のベクトルで単語を表すことです。 したがって、2番目の行列はそれらの単語の表現です。 この行列のi番目の行は、i番目の単語のベクトル表現です。 あなたの例では5つの単語があるとしましょう:、最初のベクトルはあなたが単語「馬」を検討していることを意味し、「馬」の表現はそうです。 同様に、単語”ライオン”の表現です。

私の知る限りでは、これらの表現の各数値には「人間の意味」はありません。 単語が動詞であるかどうか、形容詞であるかどうかを表すものではありません…それはあなたの言葉の表現を学ぶためにあなたの最適化問題を解
word2vec行列乗算プロセスを最も詳しく説明する視覚的な図は、次の図に示されています:

最初の行列は、入力ベクトルを1つのホット形式で表します。 第二の行列は、入力層ニューロンから隠された層ニューロンへのシナプス重みを表します。 特に、入力層行列が重み行列と乗算される左上隅に注目してください。 今、右上を見てください。 この行列乗算InputLayer dot-producted With Weights Transposeは、右上のニューラルネットワークを表現するのに便利な方法です。
最初の部分は、入力ワードを一方のホットベクトルとして表し、もう一方の行列は、各入力層ニューロンの隠れ層ニューロンへの接続の重みを表します。 Word2Vec列車として、それはこれらの重みに(勾配降下を使用して)逆伝播し、ベクトルとしての単語のより良い表現を与えるためにそれらを変更します。 トレーニングが完了したら、この重み行列のみを使用し、’dog’と言い、それを改良された重み行列と乗算して、次元=隠れ層ニューロンのnoで’dog’のベクトル表現を 図では、隠れ層ニューロンの数は3です。
一言で言えば、Skip-gramモデルはターゲット語とコンテキスト語の使用を逆にします。 この場合、ターゲットワードは入力で供給され、隠れ層は同じままであり、ニューラルネットワークの出力層は選択された数のコンテキストワードに対応するた コンテキストワードとして”cat”と”tree”、ターゲットワードとして”climed”の例を取ると、skim-gramモデルの入力ベクトルはtになり、2つの出力レイヤーはそれぞれtとtをターゲッ 確率の1つのベクトルを生成する代わりに、現在の例では2つのそのようなベクトルが生成されます。 各出力層の誤差ベクトルは、上記のようにして生成される。 ただし、すべての出力層からの誤差ベクトルは、逆伝播によって重みを調整するために合計されます。 これにより、各出力層の重み行列WOは、トレーニングを通じてすべて同一のままになります。
基本的なskip-gramモデルには、訓練を可能にするために重要な追加の変更はほとんど必要ありません。 大規模なニューラルネットワーク上で勾配降下を実行することは遅くなるだろう。 さらに悪いことに、その多くの重みを調整し、過度のフィッティングを避けるためには、膨大な量のトレーニングデータが必要です。 何百万もの重みと何十億もの訓練サンプルは、このモデルを訓練することが獣になることを意味します。 そのために,重要でない単語を除去し,重みの特定のサンプルのみを更新するサブサンプリングと負のサンプリングと呼ばれる二つの技術を提案した。
Mikolov et al. また、単純なサブサンプリングアプローチを使用して、トレーニングセット内のまれな単語と頻繁な単語の間の不均衡に対抗します(たとえば、”in”、”the”、”a”は、まれな単語よりも少ない情報値を提供します)。 トレーニングセット内の各単語は、確率P(wi)で破棄されます。

f(w i)はワードw iの頻度であり、tは選択された閾値であり、典型的には約1 0−5である。
実装の詳細
Word2Vecはさまざまな言語で実装されていますが、ここでは特にJavaに焦点を当てます。、Deeplearning4j、darks-学習とpython。 Dl4Jでは様々なニューラルネットアルゴリズムが実装されており、コードはGitHubで入手可能である。Dl4Jで実装するには、次のようないくつかの手順を実行します。
a)Word2Vec Setup
Mavenを使用してIntelliJで新しいプロジェクトを作成します。 次に、pomでプロパティと依存関係を指定します。プロジェクトのルートディレクトリ内のxmlファイル。
b)データをロード
今、Javaで新しいクラスを作成し、名前を付けます。 その後、あなたはあなたの中の生の文章を取るでしょう。txtファイルをイテレータでトラバースし、すべての単語を小文字に変換するなど、ある種の前処理を行います。
String filePath=new ClassPathResource(“raw_sentences.txt”)。getFile()。getAbsolutePath();
log.info(“ロード&文章をベクトル化………..”);
// 各行の前後に空白を取り除く
SentenceIterator iter=new BasicLineIterator(filePath);
この例で提供されている文章以外にテキストファイルをロードする場合は、次のようにします:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c)データをトークン化する
Word2Vecは文全体ではなく単語を入力する必要があるため、次のステップはデータをトークン化することです。 テキストをトークン化するには、たとえば、空白を打つたびに新しいトークンを作成して、そのアトミック単位に分割することです。
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d)モデルのトレーニング
データの準備ができたので、Word2Vecニューラルネットを設定し、トークンをフィードできます。
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
この設定では、いくつかのハイパーパラメータを使用できます。 いくつかは、いくつかの説明が必要です:
- batchSizeは、一度に処理する単語の量です。
- minWordFrequencyは、単語がコーパスに表示される必要がある最小回数です。 ここでは、それが5回未満であれば、それは学習されません。 単語に関する有用な機能を学習するには、単語を複数のコンテキストで表示する必要があります。 非常に大きなコーパスでは、最小値を上げるのが合理的です。
- useAdaGrad—Adagradはフィーチャごとに異なるグラデーションを作成します。 ここではそれには関係ありません。
- layerSizeは、ワードベクトル内のフィーチャの数を指定します。 これは、機能の次元の数に等しいスペース。 500の特徴によって表される単語は、500次元空間内の点になります。
- learningRateは、単語が特徴空間内で再配置されるため、係数の更新ごとのステップサイズです。
- minLearningRateは学習率のフロアです。 学習率は、あなたが減少する上で訓練する単語の数として減衰します。 学習率があまりにも縮小すると、ネットの学習はもはや効率的ではありません。 これにより、係数が移動し続けます。
- iterateは、学習しているデータセットのバッチをネットに伝えます。
- tokenizerは現在のバッチから単語をフィードします。
- fit()は、設定されたnetにトレーニングを開始するように指示します。
e)Word2Vec
を使用してモデルを評価する次のステップは、特徴ベクトルの品質を評価することです。
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
行vec.similarity("word1","word2")は、入力した2つの単語のコサイン類似度を返します。 それが1に近いほど、ネットはそれらの単語をより似ていると認識します(上記のスウェーデン-ノルウェーの例を参照)。 例えば:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
vec.wordsNearest("word1", numWordsNearest)では、画面に印刷された単語は、ネットが意味的に類似した単語をクラスタ化しているかどうかを調べることができます。 あなたはwordsNearestの第二のパラメータで必要な最も近い単語の数を設定することができます。 例えば:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) JavaのWord2Vechttp://deeplearning4j.org/word2vec.html
7) genismのPythonでのWord2VecとDoc2Vechttp://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html