i denne opplæringen skal vi forklare, en av de nye og fremtredende ord embedding teknikk kalt Word2Vec foreslått Av Mikolov et al. i 2013. Vi har samlet dette innholdet fra forskjellige opplæringsprogrammer og kilder for å lette leserne på ett sted. Jeg håper det hjelper.
Word2vec er en kombinasjon av modeller som brukes til å representere distribuerte representasjoner av ord i et corpus C. Word2Vec (W2V) er en algoritme som aksepterer tekstkorpus som en inngang og gir en vektorrepresentasjon for hvert ord, som vist i diagrammet nedenfor:

det er to smaker av denne algoritmen nemlig: CBOW og Skip-Gram. Gitt et sett med setninger (også kalt corpus) modellen løkker på ordene i hver setning og enten prøver å bruke det nåværende ordet w for å forutsi sine naboer (dvs. dens kontekst), kalles denne tilnærmingen «Skip-Gram», eller den bruker hver av disse sammenhenger til å forutsi det nåværende ordet w, i så fall kalles metoden «Kontinuerlig Pose Med Ord» (CBOW). For å begrense antall ord i hver kontekst, brukes en parameter kalt «window size».

vektorene vi bruker til å representere ord kalles nevrale ordinnbygginger, og representasjoner er merkelige. En ting beskriver en annen, selv om disse to tingene er radikalt forskjellige. Som Elvis Costello sa: «Å Skrive om musikk er som å danse om arkitektur.»Word2vec» vektoriserer » om ord, og ved å gjøre det gjør det naturlig språk lesbart-vi kan begynne å utføre kraftige matematiske operasjoner på ord for å oppdage deres likheter.
så representerer et nevralt ord embedding et ord med tall. Det er en enkel, men usannsynlig, oversettelse. Word2vec er lik en autoencoder, koding hvert ord i en vektor, men i stedet for trening mot inngangs ord gjennom rekonstruksjon, som en begrenset Boltzmann maskin gjør, word2vec tog ord mot andre ord som nabo dem i input corpus.
Det gjør Det på en av to måter, enten ved å bruke kontekst for å forutsi et målord (en metode kjent som kontinuerlig pose med ord, ELLER CBOW), eller ved å bruke et ord for å forutsi en målkontekst, som kalles skip-gram. Vi bruker sistnevnte metode fordi den gir mer nøyaktige resultater på store datasett.

når funksjonsvektoren som er tilordnet et ord, ikke kan brukes til å forutsi ordets kontekst nøyaktig, justeres vektorens komponenter. Hvert ords kontekst i corpus er at læreren sender feilsignaler tilbake for å justere funksjonsvektoren. Vektorene av ord som dømmes likt av deres kontekst, blir nudget nærmere sammen ved å justere tallene i vektoren. I denne opplæringen skal vi fokusere På Skip-Gram-modellen som i motsetning TIL CBOW anser senterord som inngang som vist i figur over og forutsi kontekstord.
Modelloversikt
vi forsto at vi må mate et merkelig nevralt nettverk med noen par ord, men vi kan ikke bare gjøre det ved å bruke som innganger de faktiske tegnene, vi må finne en måte å representere disse ordene matematisk slik at nettverket kan behandle dem. En måte å gjøre dette på er å lage et ordforråd av alle ordene i teksten vår og deretter kode vårt ord som en vektor av de samme dimensjonene i vårt ordforråd. Hver dimensjon kan betraktes som et ord i vårt ordforråd. Så vi vil ha en vektor med alle nuller og en 1 som representerer det tilsvarende ordet i vokabularet. Denne kodingsteknikken kalles en-varm koding. Med tanke på vårt eksempel, hvis vi har et ordforråd laget av ordene «den», «rask», «brun», «rev», «hopp», «over», «den» «lat», «hund», er ordet «brun» representert av denne vektoren: .

Skip-gram modellen tar i et korpus av tekst og skaper en hot-vektor for hvert ord. En varm vektor er en vektorrepresentasjon av et ord hvor vektoren er størrelsen på vokabularet(totalt unike ord). Alle dimensjoner er satt til 0 unntatt dimensjonen som representerer ordet som brukes som en inngang på det tidspunktet. Her er et eksempel på en varm vektor:

ovennevnte inngang er gitt til et nevralt nettverk med et enkelt skjult lag.
Vi skal representere et inngangsord som «maur» som en en-varm vektor. Denne vektoren vil ha 10.000 komponenter (en for hvert ord i vårt ordforråd), og vi plasserer en «1» i stillingen som svarer til ordet «maur» og 0s i alle de andre stillingene. Utgangen av nettverket er en enkelt vektor (også med 10.000 komponenter) som inneholder, for hvert ord i vårt ordforråd, sannsynligheten for at et tilfeldig valgt nærliggende ord er det vokabularordet.
i word2vec brukes en distribuert representasjon av et ord. Ta en vektor med flere hundre dimensjoner (si 1000). Hvert ord er representert ved en fordeling av vekter på tvers av disse elementene. Så i stedet for en en-til-en-kartlegging mellom et element i vektoren og et ord, er representasjonen av et ord spredt over alle elementene i vektoren, og hvert element i vektoren bidrar til definisjonen av mange ord.
hvis jeg merker dimensjonene i en hypotetisk ordvektor (det finnes ingen slike forhåndsdefinerte etiketter i algoritmen selvfølgelig), kan det se litt ut som dette:

en slik vektor kommer til å representere på en abstrakt måte betydningen av et ord. Og som vi ser neste, bare ved å undersøke et stort korpus er det mulig å lære ordvektorer som er i stand til å fange forholdet mellom ord på en overraskende uttrykksfull måte. Vi kan også bruke vektorene som innganger til et nevralt nettverk. Siden våre inngangsvektorer er en-varme, multipliserer en inngangsvektor Med vektmatrisen W1 til å bare velge en rad Fra W1.
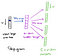

fra det skjulte laget til utgangslaget kan den andre vektmatrisen W2 brukes Til å beregne en poengsum for hvert ord i vokabularet, og softmax kan brukes til å oppnå bakre fordeling av ord. Skip-gram-modellen er motsatt AV CBOW-modellen. Den er konstruert med fokusordet som enkeltinngangsvektor, og målkontekstordene er nå på utgangslaget. Aktiveringsfunksjonen for det skjulte laget utgjør ganske enkelt å kopiere den tilsvarende raden Fra vektmatrisen W1 (lineær) som vi så før. På utgangslaget sender vi Nå c multinomiale distribusjoner i stedet for bare en. Treningsmålet er å etterligne den summerte prediksjonsfeilen på tvers av alle kontekstord i utgangslaget. I vårt eksempel vil inngangen være «læring», og vi håper å se («en»,» effektiv»,» metode»,» for»,» høy»,» kvalitet»,» distribuert»,» vektor») på utgangslaget.
her er arkitekturen i vårt nevrale nettverk.

For vårt eksempel skal vi si at vi lærer ordvektorer med 300 funksjoner. Så det skjulte laget skal representeres av en vektmatrise med 10.000 rader (en for hvert ord i vårt ordforråd) og 300 kolonner (en for hver skjult nevron). 300-funksjoner Er Hva Google brukte I sin publiserte modell trent På Google nyheter datasett (du kan laste den ned herfra). Antall funksjoner er en «hyper parameter» som du bare må stille inn på søknaden din (det vil si, prøv forskjellige verdier og se hva som gir de beste resultatene).
hvis du ser på radene i denne vektmatrisen, er dette hva som vil være våre ordvektorer!

så målet med alt dette er egentlig bare å lære denne skjulte lagvektmatrisen-utgangslaget vi bare kaster når vi er ferdige! 1 x 300 ordvektoren for «maur» blir deretter matet til utgangslaget. Utgangslaget er en softmax regresjon klassifiserer. Spesielt har hver utgangsneuron en vektvektor som den multipliserer mot ordet vektor fra det skjulte laget, da gjelder funksjonen exp (x) til resultatet. Til slutt, for å få utgangene til å oppsummere til 1, deler vi dette resultatet med summen av resultatene fra alle 10.000 utgangsnoder. Her er en illustrasjon av å beregne utgangen av utgangsneuronen for ordet «bil».

Hvis to forskjellige ord har svært like «sammenhenger» (det vil si hvilke ord som sannsynligvis vil vises rundt dem), må modellen vår gi svært like resultater for disse to ordene. Og en måte for nettverket å utføre lignende kontekstforutsigelser for disse to ordene er om ordvektorer er like. Så, hvis to ord har lignende sammenhenger, er vårt nettverk motivert for å lære lignende ordvektorer for disse to ordene! Ta da!
hver dimensjon av inngangen passerer gjennom hver node i det skjulte laget. Dimensjonen multipliseres med vekten som fører den til det skjulte laget. Fordi inngangen er en varm vektor, vil bare en av inngangsnodene ha en ikke-null verdi (nemlig verdien av 1). Dette betyr at for et ord vil bare vektene knyttet til inngangsnoden med verdi 1 bli aktivert, som vist på bildet ovenfor.
da inngangen i dette tilfellet er en varm vektor, vil bare en av inngangsnodene ha en ikke-null verdi. Dette betyr at bare vektene som er koblet til den inngangsnoden, vil bli aktivert i de skjulte nodene. Et eksempel på vektene som vil bli vurdert, er vist nedenfor for det andre ordet i vokabularet:
vektorrepresentasjonen av det andre ordet i vokabularet (vist i nevrale nettverket ovenfor) vil se ut som følger, en gang aktivert i det skjulte laget:
disse vektene starter som tilfeldige verdier. Nettverket blir deretter trent for å justere vektene for å representere inntastingsordene. Det er her utgangslaget blir viktig. Nå som vi er i det skjulte laget med en vektorrepresentasjon av ordet, trenger vi en måte å bestemme hvor godt vi har spådd at et ord vil passe inn i en bestemt sammenheng. Konteksten til ordet er et sett med ord i et vindu rundt det, som vist nedenfor:

bildet ovenfor viser at konteksten for fredag inneholder ord som » katt «og » er». Målet med det nevrale nettverket er å forutsi at «fredag» faller innenfor denne konteksten.
vi aktiverer utgangslaget ved å multiplisere vektoren som vi passerte gjennom det skjulte laget (som var inngangsvektoren * vekter inn i skjult node) med en vektorrepresentasjon av kontekstordet(som er den varme vektoren for kontekstordet * vekter inn i utgangsnoden). Tilstanden til utgangslaget for det første kontekstordet kan visualiseres nedenfor:

ovennevnte multiplikasjon er gjort for hvert ord til kontekstordpar. Vi beregner deretter sannsynligheten for at et ord tilhører et sett med kontekstord ved hjelp av verdiene som følge av de skjulte og utdatalagene. Til slutt bruker vi stokastisk gradientnedstigning for å endre verdiene til vektene for å få en mer ønskelig verdi for sannsynligheten beregnet.
i gradient descent må vi beregne gradienten til funksjonen som optimaliseres ved punktet som representerer vekten vi endrer. Gradienten brukes deretter til å velge retningen for å gjøre et skritt for å bevege seg mot det lokale optimumet, som vist i minimeringseksemplet nedenfor.
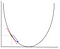
vekten vil bli endret ved å gjøre et skritt i retning av det optimale punktet (i eksemplet ovenfor, det laveste punktet i grafen). Den nye verdien beregnes ved å trekke fra den nåværende vektverdien den avledede funksjonen ved punktet for vekten skalert av læringsfrekvensen. Det neste trinnet er Å bruke Backpropagation, for å justere vektene mellom flere lag. Feilen som beregnes på slutten av utdatalaget, sendes tilbake fra utdatalaget til det skjulte laget ved å bruke Kjederegelen. Gradient descent brukes til å oppdatere vekter mellom disse to lagene. Feilen justeres deretter på hvert lag og sendes videre tilbake. Her er et diagram som representerer backpropagation:

Forstå Ved Hjelp Av Eksempel
Word2vec bruker et enkelt skjult lag, fullt tilkoblet nevralt nettverk som vist nedenfor. Nevronene i det skjulte laget er alle lineære nevroner. Inngangslaget er satt til å ha så mange nevroner som det er ord i vokabularet for trening. Den skjulte lagstørrelsen er satt til dimensjonaliteten til de resulterende ordvektorer. Størrelsen på utgangslaget er det samme som inngangslaget. Således, hvis vokabularet for å lære ordvektorer består Av V-ord og N for å være dimensjonen av ordvektorer, kan inngangen til skjulte lagforbindelser representeres av matrise WI av størrelse VxN med hver rad som representerer et ordforrådord. På samme måte kan forbindelsene fra skjult lag til utgangslag beskrives av matrise wo av størrelse NxV. I dette tilfellet representerer hver kolonne AV wo-matrise et ord fra det oppgitte vokabularet.

inngangen til nettverket er kodet ved hjelp av» 1-ut Av-V » – representasjon, noe som betyr at bare en inngangslinje er satt til en og resten av inngangslinjene er satt til null.
la oss anta at vi har et treningskorpus med følgende setninger:
«hunden så en katt», «hunden jaget katten»,»katten klatret et tre»
korpusordforrådet har åtte ord. Når bestilt alfabetisk, kan hvert ord refereres av indeksen. For dette eksemplet vil vårt nevrale nettverk ha åtte inngangsneuroner og åtte utgangsneuroner. La oss anta at vi bestemmer oss for å bruke tre nevroner i det skjulte laget. DETTE betyr at WI og WO vil være henholdsvis 8×3 og 3×8 matriser. Før treningen begynner, er disse matriser initialisert til små tilfeldige verdier som er vanlig i nevrale nettverk trening. Bare for illustrasjonens skyld, la OSS anta AT WI OG WO skal initialiseres til følgende verdier:

Anta at vi vil at nettverket skal lære forholdet mellom ordene «katt » og»klatret». Det vil si at nettverket skal vise stor sannsynlighet for «klatret» når «katt» er lagt inn i nettverket. I ord embedding terminologi, ordet «cat» er referert som kontekstordet og ordet «klatret» er referert som målordet. I dette tilfellet vil inngangsvektoren X være t. Legg Merke til at bare den andre komponenten av vektoren er 1. Dette skyldes at inngangsordet er » cat » som holder nummer to posisjon i sortert liste over corpus ord. Gitt at målordet er «klatret», vil målvektoren se ut som t. med inngangsvektoren som representerer» cat», kan utgangen på de skjulte lagneuronene beregnes som:
Ht = XtWI =
det bør ikke overraske oss at vektoren H av skjulte neuronutganger etterligner vektene i DEN andre raden AV WI-matrisen på grunn av 1-out-of-Vrepresentation. Så funksjonen til inngangen til skjulte lagforbindelser er i utgangspunktet å kopiere inngangsordvektoren til skjult lag. Gjennomføring av lignende manipulasjoner for skjult til utgangslag, aktiveringsvektoren for utgangslagneuroner kan skrives som
HtWO =
siden målet er å produsere sannsynligheter for ord i utgangslaget, Pr(wordk|wordcontext) for k = 1, V, for å reflektere deres neste ordforhold med kontekstordet ved inngang, trenger vi summen av neuronutganger i utgangslaget for å legge til en. Word2vec oppnår dette ved å konvertere aktiveringsverdier av utgangssjiktneuroner til sannsynligheter ved hjelp av softmax-funksjonen. Dermed beregnes utgangen av k-th-nevronen ved følgende uttrykk hvor aktivering (n) representerer aktiveringsverdien til n-th-utgangslaget neuron:
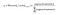
dermed er sannsynlighetene for åtte ord i corpus:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
sannsynligheten i fet skrift er for det valgte målordet «klatret». Gitt målvektoren t, beregnes feilvektoren for utgangslaget enkelt ved å trekke sannsynlighetsvektoren fra målvektoren. Når feilen er kjent, kan vektene I matrices WO OG WI oppdateres ved hjelp av backpropagation. Dermed kan treningen fortsette ved å presentere forskjellige kontekstmålord par fra corpus. Slik Lærer Word2vec relasjoner mellom ord og i prosessen utvikler vektorrepresentasjoner for ord i corpus.
ideen bak word2vec er å representere ord med en vektor av reelle tall av dimensjon d. Derfor er den andre matrisen representasjonen av disse ordene. I-linjen i denne matrisen er vektorrepresentasjonen av det i-ordet. La oss si at i ditt eksempel har du 5 ord:, da betyr den første vektoren at du vurderer ordet » Hest «og så er representasjonen av» Hest». Tilsvarende er representasjonen av ordet «Løve».

Etter min kunnskap er det ingen» menneskelig mening » spesifikt for hvert av tallene i disse representasjonene. Ett tall representerer ikke om ordet er et verb eller ikke, et adjektiv eller ikke… Det er bare vektene du endrer for å løse optimaliseringsproblemet ditt for å lære representasjonen av ordene dine.
en visuell diagram beste utdype word2vec matrise multiplikasjon prosessen er avbildet i følgende figur:

den første matrisen representerer inngangsvektoren i ett varmt format. Den andre matrisen representerer synaptiske vekter fra inngangslagneuronene til de skjulte lagneuronene. Legg spesielt merke til venstre øverste hjørne hvor Inngangslagsmatrisen multipliseres med Vektmatrisen. Se nå øverst til høyre. Denne matrise multiplikasjon InputLayer dot-producted Med Vekter Transponere er bare en hendig måte å representere nevrale nettverk øverst til høyre.
den første delen representerer inngangsordet som en varm vektor og den andre matrisen representerer vekten for tilkoblingen av hver av inngangslagneuronene til de skjulte lagneuronene. Som Word2Vec tog, det backpropagates (ved hjelp av gradient nedstigning) i disse vekter og endrer dem for å gi bedre representasjoner av ord som vektorer. Når treningen er fullført, bruker du bare denne vektmatrisen, tar for å si ‘hund’ og multipliserer den med den forbedrede vektmatrisen for å få vektorrepresentasjonen av ‘hund’ i en dimensjon = ingen skjulte lagneuroner. I diagrammet er antall skjulte lagneuroner 3.
I et nøtteskall reverserer Skip-gram-modellen bruken av mål-og kontekstord. I dette tilfellet blir målordet matet ved inngangen, det skjulte laget forblir det samme, og utgangslaget i det nevrale nettverket replikeres flere ganger for å imøtekomme det valgte antall kontekstord. Ved å ta eksemplet på » cat » og » tree «som kontekstord og» klatret » som målordet, ville inngangsvektoren i skumgrammodellen være t, mens de to utgangslagene ville ha henholdsvis t og t som målvektorer. I stedet for å produsere en vektor av sannsynligheter, vil to slike vektorer bli produsert for det nåværende eksemplet. Feilvektoren for hvert utgangslag er produsert på den måten som diskutert ovenfor. Feilvektorene fra alle utgangslag er imidlertid oppsummert for å justere vektene via backpropagation. Dette sikrer at vektmatrise WO for hvert utgangslag forblir identisk gjennom trening.
Vi trenger noen ekstra modifikasjoner på den grunnleggende skip-gram-modellen som er viktige for å gjøre det mulig å trene. Kjører gradient nedstigning på et nevralt nettverk som stort kommer til å være sakte. Og for å gjøre vondt verre, trenger du en stor mengde treningsdata for å justere at mange vekter og unngå overmontering. millioner av vekter ganger milliarder av treningsprøver betyr at trening denne modellen kommer til å bli et dyr. For det har forfattere foreslått to teknikker kalt subsampling og negativ prøvetaking der ubetydelige ord fjernes og bare en bestemt prøve av vekter oppdateres.
Mikolov et al. bruk også en enkel subsampling-tilnærming for å motvirke ubalansen mellom sjeldne og hyppige ord i treningssettet(for eksempel» i»,» den «og» a » gir mindre informasjonsverdi enn sjeldne ord). Hvert ord i treningssettet kastes med sannsynlighet P (wi) hvor

f (wi) er frekvensen av ordet wi og t er en valgt terskel, vanligvis rundt 10-5.
Implementeringsdetaljer
Word2vec er implementert på forskjellige språk, men her vil vi fokusere spesielt På Java dvs., DeepLearning4j, darks-læring og python . Ulike nevrale nettalgoritmer er implementert I DL4j, kode er tilgjengelig på GitHub.
for å implementere Det I DL4j, vil vi gå gjennom noen få trinn gitt som følger:
a) Word2Vec Setup
Opprett et nytt prosjekt I IntelliJ ved Hjelp Av Maven. Angi deretter egenskaper og avhengigheter i POM.xml-fil i prosjektets rotkatalog.
b) Last inn data
opprett Og navngi en ny klasse I Java. Etter det tar du de rå setningene i din .txt-fil, krysse dem med iteratoren din, og underkast dem til en slags forbehandling, for eksempel å konvertere alle ord til små bokstaver.
String filePath = ny ClassPathResource («raw_sentences.txt»).getFile().getAbsolutePath();
log.info («Last & Vektoriser Setninger….»);
// Strip hvitt mellomrom før og etter for hver linje
SentenceIterator iter = ny BasicLineIterator(filePath);
hvis du vil laste inn en tekstfil i tillegg til setningene i vårt eksempel, gjør du dette:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenisering Av Dataene
Word2vec må mates ord i stedet for hele setninger, så neste trinn er å tokenisere dataene. Å tokenisere en tekst er å bryte den opp i atomenhetene, og skape et nytt token hver gang du treffer et hvitt mellomrom, for eksempel.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Trening Av Modellen
Nå som dataene er klare, kan Du konfigurere Word2vec-nevrale nettet og mate i tokens.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
denne konfigurasjonen godtar flere hyperparametere. Noen krever noen forklaring:
- batchSize er mengden ord du behandler om gangen.
- minwordfrekvens er det minste antall ganger et ord må vises i korpuset. Her, hvis det vises mindre enn 5 ganger, blir det ikke lært. Ord må vises i flere sammenhenger for å lære nyttige funksjoner om dem. I svært store korpora er det rimelig å heve minimumet.
- useAdaGrad-Adagrad skaper en annen gradering for hver funksjon. Her er vi ikke opptatt av det.
- layerSize angir antall funksjoner i word-vektoren. Dette er lik antall dimensjoner i funksjoneneplass. Ord representert av 500 funksjoner blir poeng i et 500-dimensjonalt rom.
- learningRate er trinnstørrelsen for hver oppdatering av koeffisientene, ettersom ord flyttes i funksjonsområdet.
- minLearningRate er gulvet på lærings rate. Lærings rate henfaller som antall ord du trener på avtar. Hvis læringsraten krymper for mye, er nettets læring ikke lenger effektiv. Dette holder koeffisientene i bevegelse.
- iterate forteller nettet hvilken batch av datasettet det trener på.
- tokenizer mater det ordene fra gjeldende batch.
- vec.fit () forteller det konfigurerte nettet for å begynne å trene.
e) Evaluering Av Modellen, Ved Hjelp Av Word2vec
det neste trinnet er å evaluere kvaliteten på funksjonsvektorer.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
linjen vec.similarity("word1","word2") returnerer cosinuslikheten til de to ordene du skriver inn. Jo nærmere det er å 1, jo mer lik nettet oppfatter disse ordene å være (se Sverige-Norge eksempelet ovenfor). Eksempelvis:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
med vec.wordsNearest("word1", numWordsNearest) lar ordene som skrives ut på skjermen, deg se om nettet har gruppert semantisk lignende ord. Du kan angi antall nærmeste ord du vil ha med den andre parameteren wordsNearest. For eksempel:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec I Java i http://deeplearning4j.org/word2vec.html
7) Word2Vec Og Doc2Vec I Python i genisme http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html