Av Doble Engineering Company in Enterprise Asset Management / juni 25, 2020
Del dette…

Facebook

Pinterest

Twitter

Linkedin
verden av data og analyse er i stadig utvikling. I sine enklere dager besto typisk dataorganisasjon av noen filer, applikasjons-eller transaksjonsdatabaser, datalager og rapporterende datamart. Etter hvert som datakilder, volumer, generasjonshastigheter og innsamlingsprosessen har vokst gjennom årene, må dagens databehandlingsmiljø håndtere ekstremt store datasett-ofte referert til som ‘big data’ – som avslører mønstre, trender og mer, som organisasjoner kan basere beslutninger på.
de fleste organisasjoner har i Dag mange, om ikke alle, av komponentene uthevet i referansearkitekturen som formidles I Figur 1 – applikasjoner, systemer og kilder, dataoverføring, bedriftsdatalag, datatjenester, analyse og rapportering og avansert databehandling.
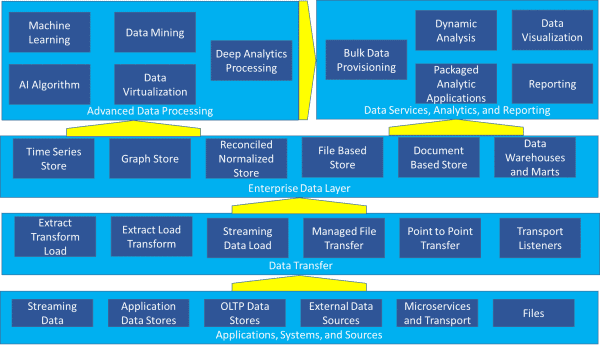
Figur 1-Kompleks Referansearkitektur
med datavarehus og marts representert som en av 28 mulige komponenter, er det vanskelig å forstå hvordan de passer inn i bildet ved første øyekast. Men de fleste organisasjoner er for tiden opptatt av mer enn et datalager – de må sammenhengende håndtere et komplekst miljø som det som er avbildet i Figur 1.
kimball og Inmon arkitekturer tilbyr begge rammer for å hjelpe til med utviklingen av kompleks referansearkitektur.
Rask oppfriskning på de to tilnærmingene
før Du bruker Kimball-eller Inmon-mønstrene, er det verdt å vurdere forskjellene mellom de to tilnærmingene. Sjekk ut de visuelle representasjonene av Hver I Figur 21 Og Figur 32 .
Arbeidet Til Kimball og Inmon – grunnleggerne av de respektive modellene – utfordret hverandre. Mens begge tilnærmingene hovedsakelig drives av utviklingssyklusen til en datamodell, er modellene basert på et målbevisst fokus på enten en bunn opp eller en topp ned tilnærming. Disse spenningene spilte ut i utviklingen av de generelle datalagrings-og analysemiljøene.
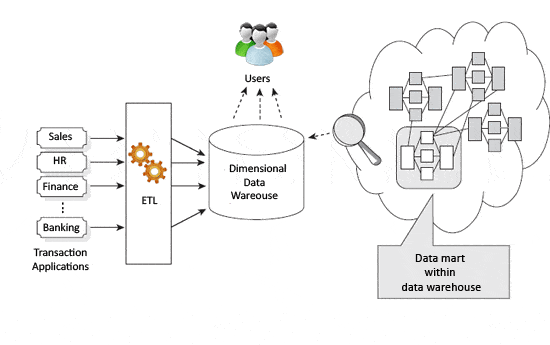
Figur 2-Visuell Kimball

Se Figur 3-Visuell Inmon-Visning
Kimball-tilnærmingen indikerer at datalagre og datamarker drives av forretningsprosesser og forretningsspørsmål. Den åpenbare faren for dette er at nyttige data ikke nødvendigvis kategoriseres eller fanges, siden de ikke passer inn i forretningsprosessen som defineres.
Inmon-tilnærmingen angir opprettelsen av et bedriftsdatalager med logiske modeller utformet for hver enhet rundt et emne, for eksempel måler, faktura og aktiva. Utfordringen er mens de store temaene kan representere differensiering, kan enhetene som støtter dem representere fellestrekk som kan gå tapt.
for eksempel kan plasseringen av en måler som representeres av en tjenesteplassering, faktureringsadressen som er representert i fakturaen, og lagerplasseringen eller distribusjonsplasseringen til et aktivum dele felles attributter. Selv under Inmon er det fare for at tjenestestedet, faktureringsadressen, eiendelen, lagerplasseringen og distribusjonsstedet for eiendelen kan representeres som fem forskjellige objekter, siden de anses å støtte forskjellige vertikaler i organisasjonen med forskjellige datamarter.
Både Inmon og Kimball tilnærminger er drevet av syklusen for å utvikle den konseptuelle datamodellen, og deretter implementere datamodellene i en fysikalisert form. Denne syklusen kan støtte mer smidige utviklingsmetoder, men det vil nærmest tilpasse seg en foss type utviklingsmetode på grunn av lineariteten til forskningen (basert på prosessen eller bedriftsemnet), utviklingen av den konseptuelle modellen (basert på dataene i prosessen eller bedriftsemnet) og utviklingen av den fysiske modellen.
Å Ta neste trinn
en smidig prosess kan gjøre det vanskelig å injisere sykluser i denne typen utviklingsaktivitet. Utfordringen for enhver organisasjon vil være å ta erfaringene Fra Inmon og Kimball tilnærminger, og bruke dem i en ny sammenheng.
Flere detaljer om hvordan du bruker mønstrene til et komplekst miljø for å komme i del to av denne bloggserien – følg med!
i mellomtiden, sjekk ut vårt siste innlegg om vellykket implementering av enterprise information management (EIM).