Non-uniform memory access (NUMA) er en delt minnearkitektur som brukes i dagens multiprosesseringssystemer. HVER CPU er tildelt sitt eget lokale minne og kan få tilgang til minne fra andre Cpuer i systemet. Lokal minnetilgang gir lav latens – høy båndbredde ytelse. Mens tilgang til minne eid av den andre CPU har høyere ventetid og lavere båndbredde ytelse. Moderne applikasjoner og operativsystemer som ESXi støtter NUMA som standard, men for å gi den beste ytelsen, bør virtuell maskinkonfigurasjon gjøres med NUMA-arkitekturen i tankene. Hvis feil utformet, ubetydelig oppførsel eller generell ytelsesforringelse oppstår for den aktuelle virtuelle maskinen eller i verste fall for alle Vm-er som kjører På Den ESXi-verten.
denne serien tar sikte på å gi innsikt I CPU-arkitekturen, minnesundersystemet Og ESXi CPU og memory scheduler. Slik at du i å skape en høy ytelse plattform som legger grunnlaget for høyere tjenester og økt konsolidering prosenter. Før vi kommer til moderne databehandlingsarkitekturer, er det nyttig å gjennomgå historien til multiprosessorarkitekturer med delt minne for å forstå hvorfor VI bruker NUMA-systemer i dag.
- utviklingen av delt minne multiprosessorer arkitektur i de siste tiårene
- Innføring av caching snoop protokoller
- Uniform Memory Access Architecture
- Ikke-Uniform Minne Tilgang Arkitektur
- 1: Non-Uniform Memory Access organization
- 2: Punkt-Til-punkt interconnect
- 3: Skalerbar Bufferkoherens
- ikke-interleaved enabled NUMA = SUMA
- Nehalem & Kjerne mikroarkitektur oversikt
utviklingen av delt minne multiprosessorer arkitektur i de siste tiårene
det ser ut til at en arkitektur kalt Uniform Memory Access ville være en bedre passform når du utformer en konsekvent lav latens, høy båndbredde plattform. Likevel vil moderne systemarkitekturer begrense det fra å være virkelig ensartet. For å forstå årsaken bak dette må vi gå tilbake i historien for å identifisere de viktigste driverne for parallell databehandling.
med innføringen av relasjonsdatabaser i begynnelsen av syttitallet behovet for systemer som kan betjene flere samtidige brukeroperasjoner og overdreven datagenerering ble mainstream. Til tross for den imponerende hastigheten på uniprosessorytelse, var multiprosessorsystemer bedre rustet til å håndtere denne arbeidsbelastningen. For å gi et kostnadseffektivt system ble delt minneadresseplass fokus for forskning. Tidlig ble systemer som brukte en tverrstangbryter, men med denne designkompleksiteten skalert sammen med økningen av prosessorer, noe som gjorde det bussbaserte systemet mer attraktivt. Prosessorer i et bussystem får tilgang til hele minneplassen ved å sende forespørsler på bussen, en svært kostnadseffektiv måte å bruke det tilgjengelige minnet så optimalt som mulig.
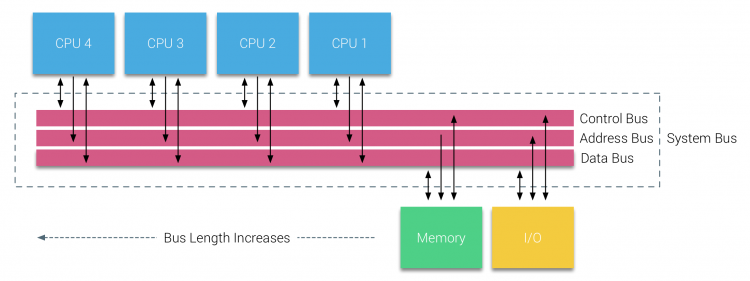
men bussbaserte systemer har sine egne skalerbarhetsproblemer. Hovedproblemet er den begrensede mengden båndbredde, dette hindrer antall prosessorer bussen kan huse. Legge Cpuer til systemet introduserer to store områder av bekymring:
- den tilgjengelige båndbredden per node reduseres etter hvert SOM HVER CPU legges til.
- busslengden øker når du legger til flere prosessorer, og øker dermed ventetiden.
ytelsesveksten TIL CPU og spesielt hastighetsgapet mellom prosessoren og minneytelsen var, og er faktisk fortsatt, ødeleggende for multiprosessorer. Siden minnegapet mellom prosessor og minne var forventet å øke, gikk det mye arbeid i å utvikle effektive strategier for å håndtere minnesystemene. En av disse strategiene var å legge til minnebuffer, som introduserte en rekke utfordringer. Å løse disse utfordringene er fortsatt hovedfokus i DAG FOR CPU-designteam, mye forskning er gjort på caching strukturer og sofistikerte algoritmer for å unngå cache savner.
Innføring av caching snoop protokoller
Feste en cache til HVER CPU øker ytelsen på mange måter. Å bringe minne nærmere CPU reduserer gjennomsnittlig minnetilgangstid og samtidig redusere båndbreddebelastningen på minnebussen. Utfordringen med å legge til cache til HVER CPU i en delt minnearkitektur er at den tillater flere kopier av en minneblokk å eksistere. Dette kalles cache-coherency problem. For å løse dette ble caching snoop-protokoller oppfunnet for å forsøke å lage en modell som ga de riktige dataene mens de ikke prøvde å spise opp all båndbredde på bussen. Den mest populære protokollen, skriv ugyldig, sletter alle andre kopier av data før du skriver den lokale hurtigbufferen. Eventuell senere lesing av disse dataene av andre prosessorer vil oppdage en cache-savner i sin lokale cache og vil bli betjent fra cachen til en ANNEN CPU som inneholder de sist endrede dataene. Denne modellen sparte mye bussbåndbredde og gjorde Det mulig For Ensartede Minnetilgangssystemer å dukke opp tidlig på 1990-tallet. Moderne cache-koherensprotokoller er dekket mer detaljert av del 3.
Uniform Memory Access Architecture
Prosessorer Av Bus-baserte multiprosessorer som opplever samme – uniform – tilgang tid til en minnemodul i systemet blir ofte referert til Som Uniform Memory Access (UMA) systemer eller Symmetriske Multi-Prosessorer (SMPs).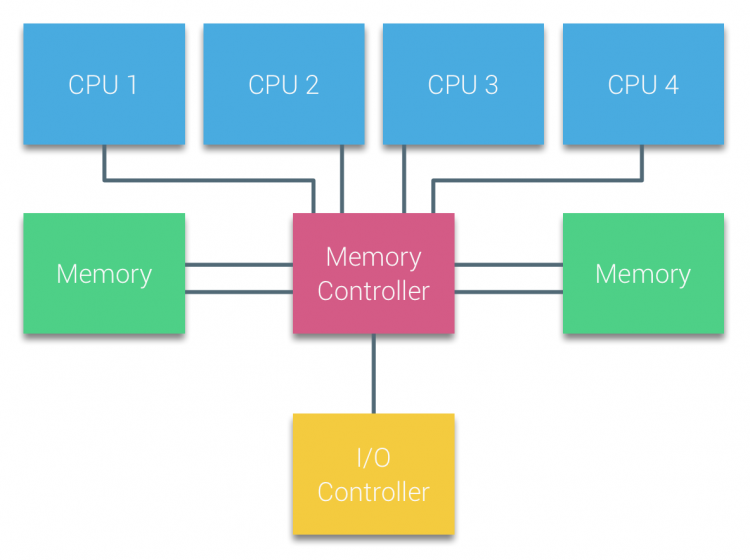
MED UMA-systemer er Cpuene koblet via en systembuss (Frontbuss) til Northbridge. Northbridge inneholder minnekontrolleren og all kommunikasjon til og fra minnet må passere Gjennom Northbridge. I/O-kontrolleren, som er ansvarlig for å administrere i / O til alle enheter, er koblet Til Northbridge. Derfor må hver I/O gå Gjennom Northbridge for å nå CPU.
Flere busser og minnekanaler brukes til å doble tilgjengelig båndbredde og redusere flaskehalsen På Northbridge. For å øke minnebåndbredden ytterligere noen systemer koblet eksterne minnekontrollere Til Northbridge, bedre båndbredde og støtte for mer minne. MEN på grunn Av Den interne båndbredden Til Northbridge og kringkasting natur tidlige snoopy cache protokoller, UMA ble ansett for å ha en begrenset skalerbarhet. Med dagens bruk av høyhastighets flash-enheter, som presset hundretusener AV IO per sekund, var de helt riktige at denne arkitekturen ikke ville skalere for fremtidige arbeidsbelastninger.
Ikke-Uniform Minne Tilgang Arkitektur
for å forbedre skalerbarhet og ytelse tre kritiske endringer er gjort i delt minne multiprosessorer arkitektur;
- Ikke-Uniform Minnetilgang organisasjon
- punkt-Til-Punkt interconnect topologi
- Skalerbare cache-koherensløsninger
1: Non-Uniform Memory Access organization
NUMA beveger seg bort fra et sentralisert minne og introduserer topologiske egenskaper. Ved å klassifisere minneplasseringsbaser på signalbanelengden fra prosessoren til minnet, kan ventetid og båndbreddeflaskehalser unngås. Dette gjøres ved å omforme hele systemet med prosessor og brikkesett. NUMA arkitekturer vunnet popularitet på slutten av 90-tallet da den ble brukt PÅ SGI superdatamaskiner Som Cray Origin 2000. NUMA bidro til å identifisere plasseringen av minnet, i dette tilfellet av disse systemene måtte de lure på hvilket minneområde der chassiset holdt minnebitene.
I første halvdel av årtusenskiftet brakte AMD NUMA til bedriftslandskapet der UMA systems regjerte øverste. I 2003 BLE AMD Opteron-familien introdusert, med integrerte minnekontrollere med HVER CPU som eier utpekte minnebanker. HVER CPU har nå sin egen minneadresseplass. ET NUMA-optimalisert operativsystem som ESXi tillater arbeidsbelastning å forbruke minne fra begge minneadressene, samtidig som det optimaliseres for lokal minnetilgang. La oss bruke et eksempel på et TO CPU-system for å klargjøre skillet mellom lokal og ekstern minnetilgang i et enkelt system.
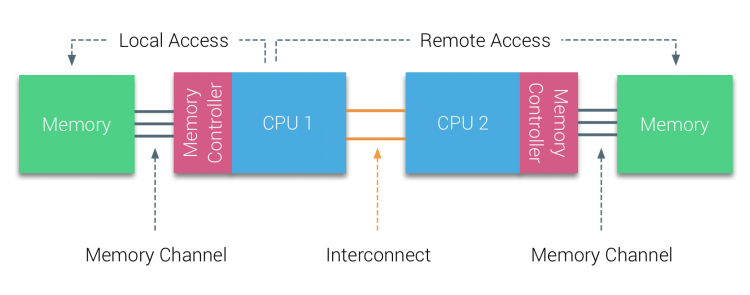
minnet som er koblet til MINNEKONTROLLEREN TIL CPU1, anses å være lokalt minne. Minne som er koblet til en ANNEN CPU-kontakt (CPU2)anses å være utenlandsk eller ekstern FOR CPU1. Ekstern minnetilgang har ekstra ventetid overhead til lokal minnetilgang, da den må krysse en interconnect (punkt-til-punkt-kobling) og koble til den eksterne minnekontrolleren. Som et resultat av de forskjellige minneplasseringene, opplever dette systemet «ikke-uniform» minnetilgangstid.
2: Punkt-Til-punkt interconnect
AMD introduserte sin punkt-til-punkt-tilkobling HyperTransport MED AMD Opteron mikroarkitektur. Intel flyttet bort fra sin doble uavhengige bussarkitektur i 2007 ved å introdusere QuickPath-Arkitekturen i Deres Nehalem-Prosessorfamilie design.
nehalem-arkitekturen var en betydelig designendring innen Intel-mikroarkitekturen og regnes som Den første sanne generasjonen Av Intel Core-serien. Den nåværende Broadwell-arkitekturen er 4. generasjon Av Intel Core-merket (Intel Xeon E5 v4), det siste avsnittet inneholder mer informasjon om mikroarkitekturgenerasjonene. Innenfor QuickPath-arkitekturen flyttet minnekontrollene til CPU og introduserte QuickPath point-to-point Interconnect (QPI) som datakoblinger mellom Cpuer i systemet.
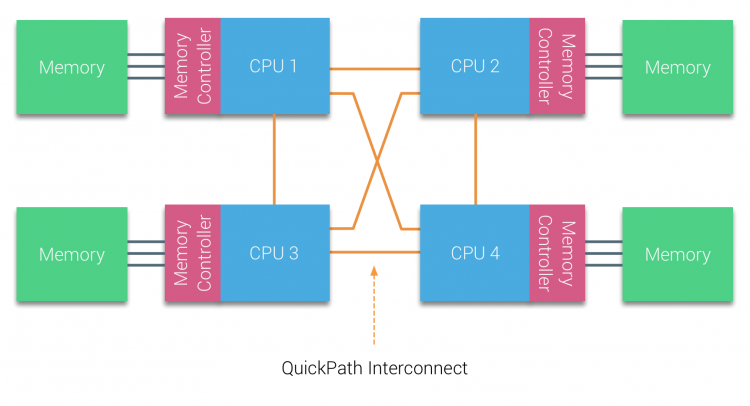
nehalem-mikroarkitekturen erstattet ikke bare den eldre frontbussen, men reorganiserte hele delsystemet til en modulær DESIGN for server-CPU. Denne modulære designen ble introdusert som «Uncore» og skaper et byggeblokkbibliotek for caching og interconnect-hastigheter. Fjerning av front-side bussen forbedrer båndbredde skalerbarhet problemer, men intra – og interprosessor kommunikasjon må løses når du arbeider med enorme mengder minnekapasitet og båndbredde. Både den integrerte minnekontrolleren og QuickPath-Sammenkoblingene er En del Av Uncore og Er Modellspesifikke Registre (MSR) ). De kobler til EN MSR som gir intra – og inter-prosessor kommunikasjon. Modulariteten Til Uncore tillater Også Intel å tilby forskjellige qpi-hastigheter, Ved Skriving Tilbyr Intel Broadwell-EP-mikroarkitekturen (2016) 6,4 Giga-overføringer per sekund (GT / s), 8,0 GT / s og 9,6 GT / s.henholdsvis gir en teoretisk maksimal båndbredde på 25,6 GB/s, 32 GB/s og 38,4 GB/S mellom Cpuene. For å sette dette i perspektiv ga den sist brukte frontbussen 1,6 GT / s eller 12,8 GB / s plattformbåndbredde. Når du introduserer Sandy Bridge Intel rebranded Uncore Til System Agent, men begrepet Uncore brukes fortsatt i gjeldende dokumentasjon. Du kan finne mer Om QuickPath og The Uncore i del 2.
3: Skalerbar Bufferkoherens
hver kjerne hadde en privat bane Til l3-hurtigbufferen. Hver bane besto av tusen ledninger, og du kan forestille deg at dette ikke skalerer bra hvis du vil redusere nanometerproduksjonsprosessen samtidig som du øker kjernene som vil ha tilgang til hurtigbufferen. For å kunne skalere, Sandy Bridge Arkitektur flyttet l3 cache ut Av Uncore og introduserte skalerbar ring på dør Interconnect. Dette tillot Intel å partisjonere Og distribuere l3-cachen i like skiver. Dette gir høyere båndbredde og assosiativitet. Hver skive er 2,5 MB og en skive er knyttet til hver kjerne. Ringen tillater hver kjerne å få tilgang til hver annen skive også. Bildet nedenfor er dørkonfigurasjonen Av En Low Core Count (LCC) Xeon CPU av Broadwell Microarchitecture (v4) (2016).
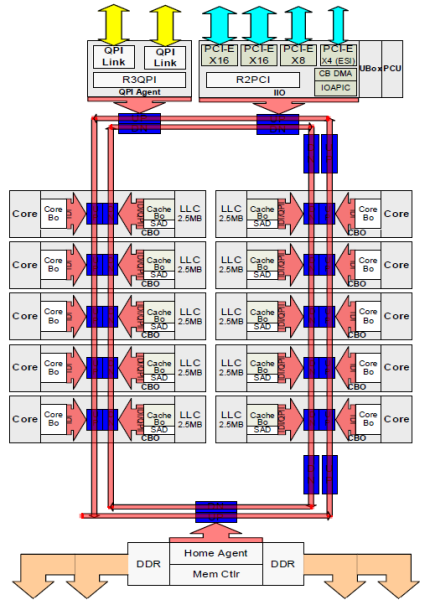
denne caching-arkitekturen krever en snooping-protokoll som inkorporerer både distribuert lokal cache og de andre prosessorene i systemet for å sikre cache-sammenheng. Med tillegg av flere kjerner i systemet vokser mengden snoop-trafikk, siden hver kjerne har sin egen jevne strøm av cache-savner. Dette påvirker forbruket AV QPI-koblinger OG siste nivå cacher, som krever kontinuerlig utvikling i snoop coherency protokoller. En grundig visning Av Uncore, skalerbar ring on-Die Interconnect og betydningen av caching snoop protokoller PÅ NUMA ytelse vil bli inkludert i del 3.
ikke-interleaved enabled NUMA = SUMA
Fysisk minne distribueres over hovedkortet, men systemet kan gi et enkelt minneadresseområde ved å interleaving minnet mellom DE TO NUMA-nodene. Dette kalles Node-interleaving(innstillingen er dekket i del 2). Når node interleaving er aktivert, blir systemet En Tilstrekkelig Jevn Minnearkitektur (SUMA). I stedet for å videresende topologi info og natur prosessorer og minne i systemet til operativsystemet, bryter systemet ned hele minneområdet I 4kb adresserbare regioner og kartlegger dem i en round robin mote fra hver node. Dette gir en’ interleaved ‘ minnestruktur der minneadresseområdet er fordelt over nodene. Når ESXi tilordner minne til virtuell maskin, tildeler det fysisk minne fra to forskjellige noder når den fysiske CPUEN i Node 0 må hente minnet fra Node 1, vil minnet krysse qpi-koblingene.
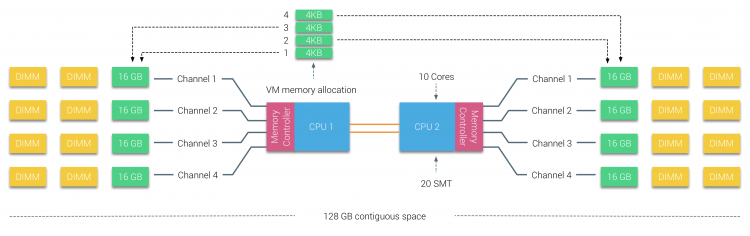
det interessante er AT SUMA-systemet gir en jevn minnetilgangstid. Bare ikke den mest optimale og tungt avhenger av stridsnivåer I QPI-arkitekturen. Intel Memory Latency Checker ble brukt til å demonstrere forskjellene MELLOM NUMA og SUMA konfigurasjon på samme system.
denne testen måler tomgangsforsinkelsene (i nanosekunder) fra hver kontakt til den andre kontakten i systemet. Ventetiden rapportert Av Memory Node 0 Av Socket 0 er lokal minnetilgang, minnetilgang fra socket 0 av memory node 1 er ekstern minnetilgang i systemet konfigurert SOM NUMA.
| NUMA | Minnenode 0 | Minnenode 1 | – | SUMA | Minnenode 0 | Minnenode 1 |
| Socket 0 | 75.7 | 132.0 | – | Stikkontakt 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
som forventet interleaving påvirkes av konstant traversering AV QPI-koblingene. Tomgangsminnetesten er det beste tilfellet, en mer interessant test måler lastede latenser. Det ville vært en dårlig investering hvis ESXi-serverne dine er tomgang, derfor kan du anta at Et ESXi-system behandler data. Måling av belastede ventetider gir bedre innsikt i hvordan systemet vil utføre under normal belastning. Under testen endres belastningsinjeksjonsforsinkelsene automatisk hvert 2. sekund, og både båndbredden og den tilsvarende ventetiden måles på det nivået. Denne testen bruker 100% lese trafikk.NUMA testresultater til venstre, SUMA testresultater til høyre.
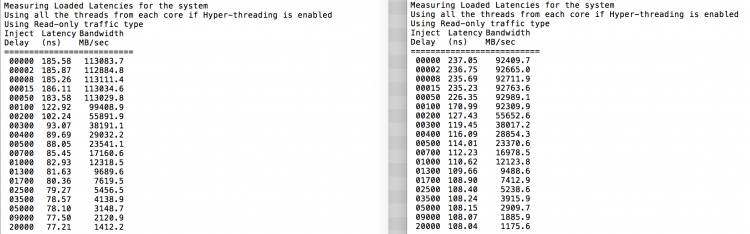
den rapporterte båndbredden for SUMA-systemet er lavere, samtidig som den opprettholder en høyere ventetid enn SYSTEMET som ER konfigurert SOM NUMA. Derfor bør fokuset være på å optimalisere VM-størrelsen for å utnytte SYSTEMETS NUMA-egenskaper.
Nehalem & Kjerne mikroarkitektur oversikt
Med innføringen Av nehalem mikroarkitektur i 2008, Intel flyttet bort Fra Netburst arkitektur. Nehalem-mikroarkitekturen introduserte Intel-kunder TIL NUMA. Gjennom årene Introduserte Intel nye mikroarkitekturer og optimaliseringer, ifølge sin berømte Tick-Tock-modell. Med hvert Kryss skjer optimalisering, krymping av prosessteknologien og med hver Takk innføres en ny mikroarkitektur. Selv Om Intel gir en konsekvent merkevaremodell siden 2012, har folk en Tendens Til Intel arkitektur kodenavn for å diskutere CPU tick og tock generasjoner. SELV EVC-grunnlinjene viser disse interne Intel-kodenavnene, både merkevarenavn og arkitekturkodenavn vil bli brukt i hele denne serien:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Takk | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Kryss | 14 nm |
Opp neste, Del 2: Systemarkitektur
2016 NUMA Deep Dive Series:
Del 0: Introduksjon NUMA Deep Dive Series
Del 1: FRA UMA TIL NUMA
Del 2: Systemarkitektur
Del 3: Cache Coherency
Del 4: Lokal Minneoptimalisering
Del 5: ESXi VMKERNEL NUMA Constructs