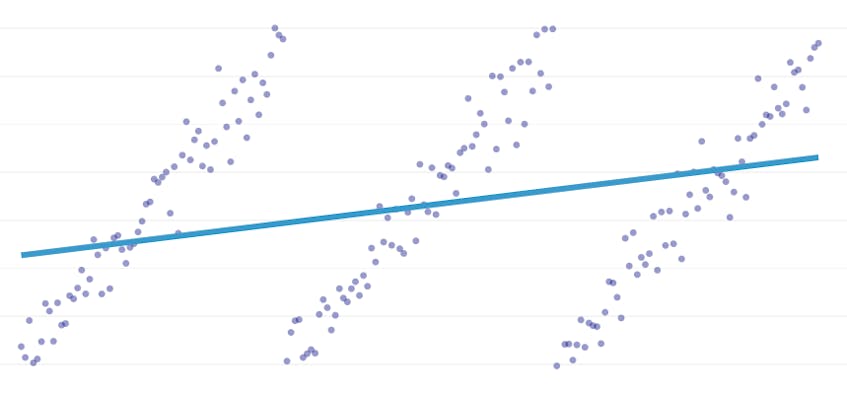
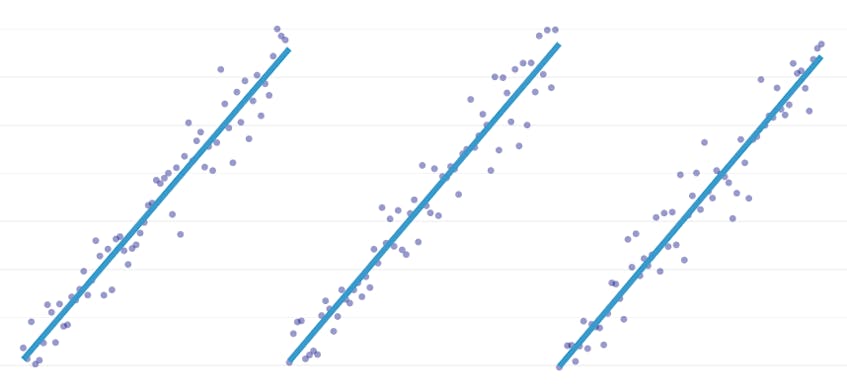
Stykkevis regresjon er en spesiell type lineær regresjon som oppstår når en enkelt linje ikke er tilstrekkelig til å modellere et datasett. Stykkevis regresjon bryter domenet inn i potensielt mange «segmenter» og passer en egen linje gjennom hver enkelt. For eksempel, i grafene nedenfor, kan en enkelt linje ikke modellere dataene, så vel som en stykkevis regresjon med tre linjer:
dette innlegget presenterer Datadog tilnærming til å automatisere stykkevis regresjon på tidsseriedata.
Mål
Stykkvis regresjon kan bety litt forskjellige ting i forskjellige sammenhenger, så la oss ta et minutt å avklare hva vi prøver å oppnå med vår stykkvis regresjonsalgoritme.
automatisk registrering av stoppunkt. I klassisk statistikklitteratur foreslås stykkevis regresjon ofte under manuell regresjonsanalysearbeid, hvor det er åpenbart for det blotte øye hvor en lineær trend gir vei til en annen. I så fall kan et menneske angi brytepunktet mellom stykkevis segmenter, dele datasettet og utføre en lineær regresjon på hvert segment uavhengig. I våre brukstilfeller vil vi gjøre hundrevis av regresjoner per sekund, og det er ikke mulig å få et menneske til å spesifisere alle brytepunkter. I stedet har vi kravet om at vår stykkevis regresjonsalgoritme identifiserer sine egne brytepunkter.
automatisk gjenkjenning av segmentantall. Hvis vi skulle vite at et datasett har nøyaktig to segmenter, kan vi enkelt se på hvert av de mulige par segmenter. Men i praksis, når det gis en vilkårlig tidsserie, er det ingen grunn til å tro at det må være mer enn ett segment eller mindre enn 3 eller 4 eller 5. Vår algoritme må velge et passende antall segmenter uten at det er brukerdefinert.
ingen kontinuitetskrav. Noen metoder for stykkevis regresjoner genererer tilkoblede segmenter, hvor hvert segments sluttpunkt er det neste segmentets startpunkt. Vi stiller ingen slike krav til vår algoritme.
Utfordringer
den mest åpenbare utfordringen med å implementere en stykkevis regresjon med automatisert brytpunktdeteksjon er den store størrelsen på løsningssøkeplassen; et brute-force-søk av alle mulige segmenter er uoverkommelig dyrt. Antall måter en tidsserie kan deles inn i segmenter er eksponentiell i lengden av tidsserien. Mens dynamisk programmering kan brukes til å krysse dette søkeområdet mye mer effektivt enn en naiv brute-force-implementering, er det fortsatt for sakte i praksis. En grådig heuristisk vil være nødvendig for å raskt kaste bort store områder av søkeområdet.
En mer subtil utfordring er at vi trenger en måte å sammenligne kvaliteten på en løsning til en annen. For vår versjon av problemet, med ukjente tall og steder av segmenter, må vi sammenligne potensielle løsninger med forskjellige antall segmenter og forskjellige brytepunkter. Vi finner oss selv prøver å balansere to konkurrerende mål:
- Minimere feilene. Det vil si, gjør hvert segments regresjonslinje nær de observerte datapunktene.
- Bruk færrest antall segmenter som modellerer dataene godt. Vi kan alltid få null feil ved å lage et enkelt segment for hvert punkt (eller til og med ett segment for hvert to poeng). Likevel ville det beseire hele poenget med å gjøre en regresjon; vi ville ikke lære noe om det generelle forholdet mellom et tidsstempel og dets tilhørende metriske verdi, og vi kunne ikke lett bruke resultatet for interpolering eller ekstrapolering.
vår løsning
vi bruker følgende grådige algoritme for stykkevis regresjonsproblem:
- gjør en stykkevis regresjon med n / 2 segmenter, hvor n er antall observasjoner i tidsserien. Regresjonslinjen i hvert segment er egnet ved hjelp av ordinær minste kvadraters (OLS) regresjon. Denne innledende stykkevis regresjon vil ha knapt noen feil, men det vil alvorlig overfit datasettet.
- Iterativt, til det bare er ett segment:
- for alle par av nabosegmenter, evaluer økningen i total feil som ville oppstå hvis de to segmentene ble kombinert, og deres to regresjonslinjer ble erstattet av en enkelt regresjonslinje.
- Slå sammen de to segmentene som vil resultere i den minste feiløkningen.
- hvis du utfører denne flettingen oppfyller våre stoppkriterier (definert nedenfor), kan det hende at vi har gått for langt og slått sammen to segmenter som skal forbli separate. Hvis dette er tilfelle, husk tilstanden til segmentene fra før denne iterasjonens fusjon.
- Hvis ingen fusjon resulterte i å huske tilstanden til segmenter i (2c) ovenfor, er den beste løsningen ett stort segment. Ellers er den siste segmenttilstanden som skal huskes i (2c) den beste løsningen.
Stoppkriterier
vi anser en fletting som et potensielt stopppunkt hvis den øker summen av kvadrerte feil med mer enn noen tidligere fletting. For å unngå å stoppe for tidlig i tilfeller der det bare burde være ett segment, vil vi ikke vurdere en fusjon for å være et potensielt stopppunkt, med mindre det resulterer i en økning i total feil som er mindre enn 3% av den totale feilen i en regresjon med ett segment. (3% er en vilkårlig terskel, men vi har funnet det å fungere bra i praksis.) Nedenfor er et par eksempler for å demonstrere hvorfor dette stoppkriteriet fungerer.
La Oss først se på et datasett som ble generert ved å legge til normalt distribuert støy til punkter langs en enkelt linje. Algoritmen passer riktig bare et enkelt segment gjennom dette datasettet.
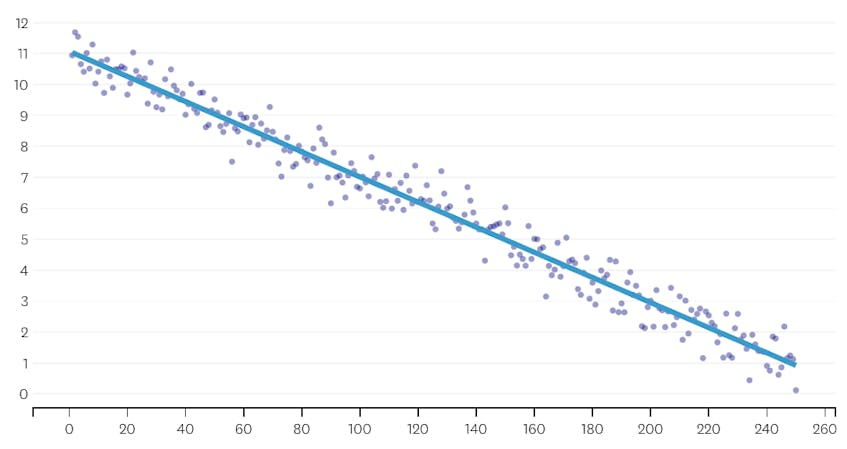
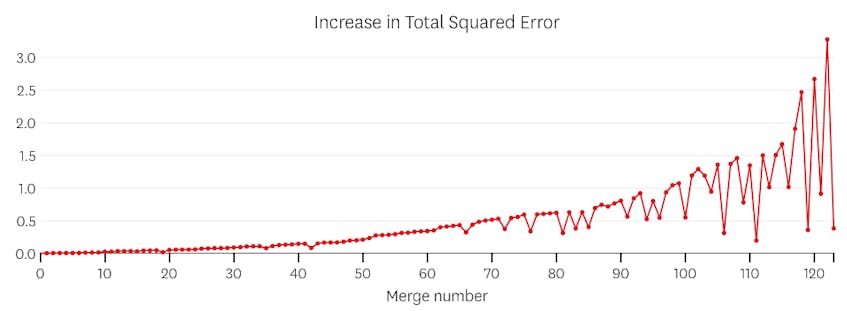
i dette tilfellet øker ingen sammenslåing den totale summen av kvadrerte feil med mer enn 3%. Derfor anses ingen sammenslåing som et tilstrekkelig stoppested, og vi bruker den endelige tilstanden etter at alle sammenslåinger er utført. I plottet nedenfor ser vi at senere sammenslåinger har en tendens til å introdusere flere feil enn tidligere (noe som gir mening fordi de hver påvirker flere poeng), men økningen i feil øker bare gradvis etter hvert som flere segmenter slås sammen.
For Det Andre, la oss se et eksempel der det er syv forskjellige segmenter i datasettet.
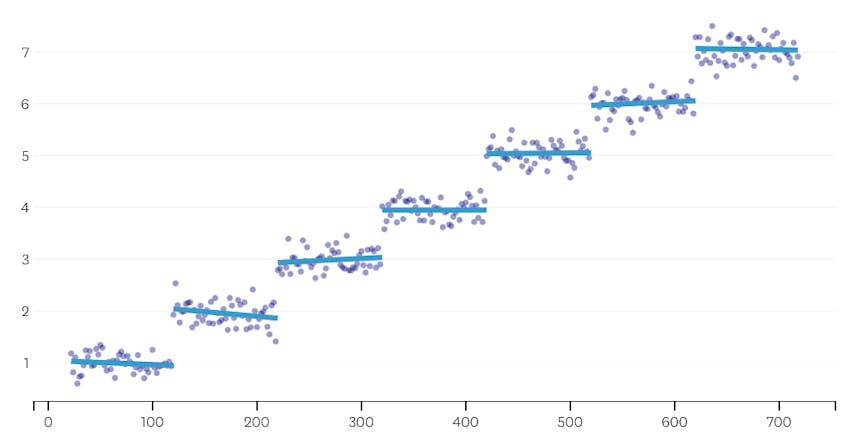
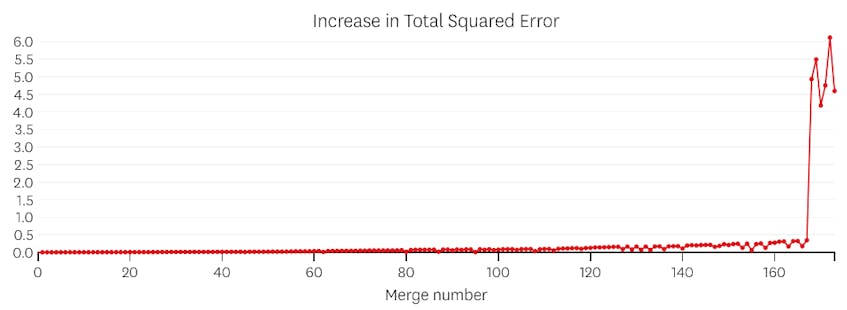
I dette tilfellet, når vi ser på plottet av feil introdusert av hver fusjon, ser vi at de siste seks fusjoner innført mye mer feil enn noen av de tidligere fusjoner. Derfor husket vår algoritme tilstanden til segmentene fra før 6. til siste fusjon og brukte det som den endelige løsningen.
koden
I Datadog / piecewise Github repo finner du Vår Python-implementering av algoritmen. Funksjonen piecewise() er der den tunge løftingen skjer; gitt et sett med data, vil det returnere lokasjons – og regresjonskoeffisientene for hvert av de monterte segmentene.
også inkludert i hovedpunkt er plot_data_with_regression() – en wrapper funksjon for rask og enkel plotting. Et raskt eksempel på hvordan dette kan brukes:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)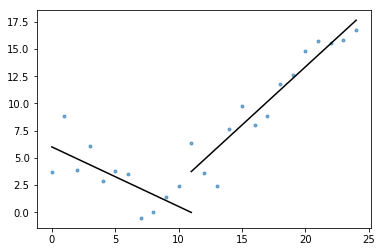
MENS denne implementeringen bruker OLS lineær regresjon, kan det samme rammeverket tilpasses for å løse relaterte problemer. Ved å erstatte squared feil med absolutt feil eller Huber tap, kan regresjonen gjøres robust. Eller en trinnfunksjon kan passe ved å tildele hvert segment en konstant verdi som er lik gjennomsnittet av observasjonene i domenet.