By Doble Engineering Company in Enterprise Asset Management / czerwiec 25, 2020
podziel się tym…Facebook
Facebook

Pinterest

Twitter

Linkedin
świat danych i analityki stale się rozwija. W swoich prostszych czasach typowa organizacja danych składała się z niektórych plików, aplikacji lub baz danych transakcyjnych, hurtowni danych i raportowania danych. Ponieważ źródła danych, wolumeny, szybkość generowania i proces zbierania danych rosły na przestrzeni lat, dzisiejsze środowisko obliczeniowe musi radzić sobie z bardzo dużymi zbiorami danych – powszechnie zwanymi „big data” – które ujawniają wzorce, trendy i inne elementy, na których organizacje mogą opierać decyzje.
większość organizacji ma obecnie wiele, jeśli nie wszystkie, komponentów wyróżnionych w architekturze referencyjnej przedstawionej na rysunku 1 – aplikacje, systemy i źródła, transfer danych, korporacyjna Warstwa danych, usługi danych, analityka i raportowanie oraz zaawansowane przetwarzanie danych.
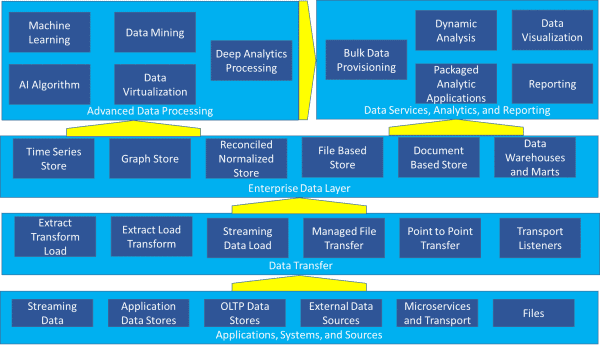
Rysunek 1-złożona architektura referencyjna
z hurtownią danych i Mart reprezentowanymi jako jeden z 28 możliwych komponentów, trudno jest zrozumieć, jak na pierwszy rzut oka pasują do obrazu. Ale większość organizacji zajmuje się obecnie czymś więcej niż hurtownią danych-muszą spójnie zarządzać złożonym środowiskiem, takim jak to pokazane na rysunku 1.
architektury Kimball i Inmon oferują frameworki, które pomagają w rozwoju złożonej architektury referencyjnej.
szybkie odświeżenie dwóch podejść
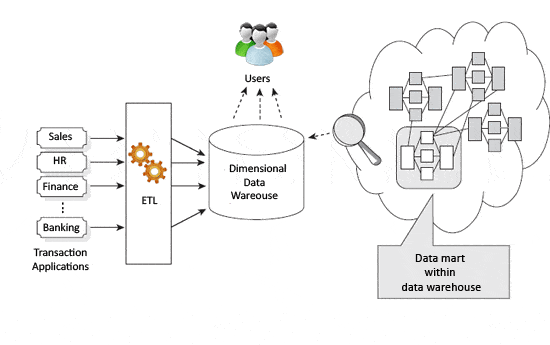
przed zastosowaniem wzorców Kimball lub Inmon warto przejrzeć różnice między tymi dwoma podejściami. Sprawdź wizualne reprezentacje każdego z nich na fig. 21 i Fig. 32 .
praca Kimballa i Inmona-założycieli poszczególnych modeli-rzuciła sobie wyzwanie. Podczas gdy oba podejścia są głównie napędzane przez cykl rozwoju modelu danych, modele opierają się na jednostronnym skupieniu się na podejściu oddolnym lub odgórnym. Napięcia te wystąpiły w rozwoju ogólnych środowisk przechowywania danych i analityki.
Rysunek 2-Visual Kimball

Widok Rysunek 3-wizualny Widok Inmon
podejście Kimballa wskazuje, że hurtownie danych i Marty danych są napędzane przez procesy biznesowe i pytania biznesowe. Oczywiste zagrożenie dla tego jest przydatne dane nie muszą być kategoryzowane lub przechwytywane, ponieważ nie mieści się w procesie biznesowym jest zdefiniowany.
podejście Inmon wskazuje na utworzenie korporacyjnej hurtowni danych z modelami logicznymi zaprojektowanymi dla każdego podmiotu wokół tematu, takiego jak licznik, faktura i zasób. Wyzwanie polega na tym, że podczas gdy główne tematy mogą reprezentować zróżnicowanie, wspierające je podmioty mogą reprezentować wspólne cechy, które mogą zostać utracone.
na przykład lokalizacja licznika reprezentowana przez lokalizację usługi, adres rozliczeniowy reprezentowany na fakturze oraz lokalizacja zapasów lub lokalizacja wdrożenia zasobu mogą mieć wspólne atrybuty. Nawet w przypadku Inmon istnieje niebezpieczeństwo, że Lokalizacja Usługi, adres rozliczeniowy, zasób, lokalizacja zapasów i lokalizacja wdrożenia zasobów mogą być reprezentowane jako pięć różnych obiektów, ponieważ uważa się, że obsługują różne branże w organizacji z różnymi martami danych.
zarówno podejście Inmon, jak i Kimball są napędzane przez cykl w celu opracowania koncepcyjnego modelu danych, a następnie wdrożenia modeli danych w formie fizykalnej. Cykl ten może wspierać bardziej zwinne podejścia rozwojowe, ale będzie najbardziej zgodny z podejściem rozwoju typu waterfall ze względu na liniowość badań (w oparciu o proces lub temat przedsiębiorstwa), Rozwój modelu koncepcyjnego (w oparciu o dane w procesie lub temat przedsiębiorstwa) oraz rozwój modelu fizycznego.
kolejny krok
zwinny proces może utrudnić wprowadzanie cykli do tego typu aktywności programistycznej. Wyzwaniem dla każdej organizacji będzie wyciągnięcie wniosków z metod Inmon i Kimball i zastosowanie ich w nowym kontekście.
więcej szczegółów na temat stosowania wzorców w złożonym środowisku, które pojawią się w drugiej części tej serii blogów – bądź na bieżąco!
w międzyczasie sprawdź nasz ostatni post na temat pomyślnego wdrożenia enterprise information management (EIM).