klasyfikacja danych jest istotnym elementem każdego programu bezpieczeństwa informacji i zgodności, zwłaszcza jeśli Twoja organizacja przechowuje duże ilości danych. Zapewnia solidne podstawy dla strategii bezpieczeństwa danych, pomagając zrozumieć, gdzie przechowujesz poufne i regulowane DANE, zarówno lokalnie, jak i w chmurze. Ponadto klasyfikacja danych poprawia produktywność użytkowników i podejmowanie decyzji oraz zmniejsza koszty przechowywania i konserwacji, umożliwiając eliminację niepotrzebnych danych.
w tym artykule dowiesz się, jakie korzyści oferuje klasyfikacja danych, jak ją wdrożyć i jak wybrać odpowiednie rozwiązanie programowe.
- kluczowe terminy i definicje klasyfikacji danych
- cel klasyfikacji danych
- zalety klasyfikacji danych
- rodzaje klasyfikacji danych
- przykłady kategorii klasyfikacji danych
- proces klasyfikacji danych
- jak wybrać rozwiązanie klasyfikacji danych
- FAQ
- kluczowe terminy i definicje klasyfikacji danych
- cel klasyfikacji danych
- korzyści z klasyfikacji danych
- bezpieczeństwo danych
- zgodność z przepisami
- rodzaje klasyfikacji danych
- przykłady kategorii klasyfikacji danych
- przykład podstawowego schematu klasyfikacji
- przykład rządowego schematu klasyfikacji
- przykład klasyfikacji handlowej
- proces klasyfikacji danych
- skuteczna klasyfikacja informacji w pięciu krokach
- budowanie skutecznej polityki klasyfikacji danych
- jak wybrać rozwiązanie klasyfikacji danych
- FAQ
kluczowe terminy i definicje klasyfikacji danych
klasyfikacja danych to proces organizowania ustrukturyzowanych i nieustrukturyzowanych danych w zdefiniowane kategorie, które reprezentują różne typy danych. Standardowe klasyfikacje stosowane w kategoryzacji danych obejmują:
- publiczne
- poufne
- wrażliwe
- osobiste
dane wrażliwe to ogólny termin reprezentujący dane ograniczone do wykorzystania przez określone osoby lub grupy. Dane wrażliwe i poufne są często używane zamiennie. Przykładami danych wrażliwych są własność intelektualna i tajemnice handlowe.
reklasyfikacja danych to ponowna Kategoryzacja danych w celu zastosowania odpowiednich aktualizacji, na przykład w oparciu o zmiany zobowiązań prawnych lub umownych, wykorzystanie lub wartość danych lub nowe lub zmienione mandaty regulacyjne.
oznaczanie lub etykietowanie danych dodaje metadane do plików wskazujących wyniki klasyfikacji.
cel klasyfikacji danych
klasyfikacja danych pomaga zrozumieć, jakie typy danych przechowujesz i gdzie się znajdują. Ta inteligencja:
- informuje procesy zarządzania ryzykiem, wykrywania przepisów i zgodności z przepisami
- pomaga nadać priorytet środkom bezpieczeństwa
- poprawia produktywność użytkowników i podejmowanie decyzji poprzez usprawnienie wyszukiwania i e-discovery
- zmniejsza koszty utrzymania i przechowywania danych, identyfikując zduplikowane i przestarzałe dane
- pomaga zespołom IT uzasadniać wnioski o inwestycje w bezpieczeństwo danych.
korzyści z klasyfikacji danych
ogólnie rzecz biorąc, klasyfikacja danych pomaga organizacjom poprawić bezpieczeństwo danych i zapewnić zgodność z przepisami.
bezpieczeństwo danych
klasyfikacja jest skutecznym sposobem ochrony cennych danych. Identyfikując typy przechowywanych danych i wskazując, gdzie znajdują się dane wrażliwe, masz dobrą pozycję:
- ustalaj priorytety środków bezpieczeństwa, dostosowując środki bezpieczeństwa w oparciu o wrażliwość danych
- dowiedz się, kto może uzyskać dostęp do danych, modyfikować je lub usuwać
- oceniaj zagrożenia, takie jak skutki biznesowe naruszenia, atak ransomware lub inne zagrożenie
zgodność z przepisami
przepisy dotyczące zgodności wymagają od organizacji ochrony określonych danych, takich jak informacje o posiadaczu karty (PCI DSS) lub dane osobowe mieszkańców UE (RODO). Klasyfikacja danych umożliwia identyfikację podmiotu danych zgodnie z określonymi przepisami, dzięki czemu można zastosować wymagane kontrole i przejść audyty.
oto, jak klasyfikacja danych może pomóc w spełnieniu wspólnych standardów zgodności:
- RODO-klasyfikacja danych pomaga chronić prawa osób, których dane dotyczą, w tym zaspokajać żądania dostępu osób, których dane dotyczą, poprzez pobieranie zestawu dokumentów z danymi o danej osobie.
- HIPAA-Wiedza o tym, gdzie przechowywane są wszystkie dane zdrowotne, pomaga wdrożyć środki kontroli bezpieczeństwa w celu właściwej ochrony danych.
- ISO 27001-klasyfikowanie informacji według wartości i czułości pomaga spełnić wymagania dotyczące zapobiegania nieautoryzowanemu ujawnieniu lub modyfikacji.
- NIST SP 800-53-Kategoryzacja danych pomaga agencjom federalnym w prawidłowym projektowaniu i zarządzaniu ich systemami informatycznymi.
- PCI DSS — klasyfikacja danych umożliwia identyfikację i zabezpieczenie informacji finansowych konsumentów wykorzystywanych w kartach płatniczych

rodzaje klasyfikacji danych
- klasyfikacja oparta na treści sprawdza i interpretuje pliki w celu identyfikacji informacji wrażliwych.
- klasyfikacja kontekstowa patrzy na aplikację, lokalizację, tagi twórcy i inne zmienne jako pośrednie wskaźniki wrażliwych informacji.
- klasyfikacja oparta na użytkowniku zależy od ręcznego wyboru każdego dokumentu przez osobę.
przykłady kategorii klasyfikacji danych
przykład podstawowego schematu klasyfikacji
najprostszym schematem jest klasyfikacja trzypoziomowa:
- dane publiczne — dane, które mogą być swobodnie ujawniane publicznie. Przykłady obejmują dane kontaktowe firmy i Politykę plików cookie przeglądarki.
- Dane wewnętrzne-dane, które mają niskie wymagania bezpieczeństwa, ale nie są przeznaczone do publicznego ujawnienia, takie jak badania marketingowe.
- ograniczone dane — bardzo wrażliwe dane wewnętrzne. Ujawnienie może negatywnie wpłynąć na operacje i umieścić organizację na ryzyko finansowe lub prawne. Ograniczone dane wymagają najwyższego poziomu ochrony.
przykład rządowego schematu klasyfikacji
agencje rządowe często używają trzech poziomów czułości, ale nadają im inne oznaczenia niż wymienione powyżej: ściśle tajne, tajne i publiczne. W przypadku bardziej złożonych struktur danych można dodać więcej poziomów. Oto pięciopoziomowa strategia z przykładami:
- ściśle tajne — kryptologia i wywiad komunikacyjny
- tajne — Wybierz plany wojskowe
- poufne — dane wskazujące na siłę sił lądowych
- poufne — dane oznaczone „tylko do użytku oficjalnego”
- niesklasyfikowane — dane, które mogą być publicznie udostępnione za zgodą
przykład klasyfikacji handlowej
zazwyczaj organizacje, które przechowują i przetwarzają dane handlowe, używają czterech poziomów do klasyfikacji danych: trzech poziomów poufnych i jednego poziomu publicznego. Niektórzy rozszerzają to do pięciopoziomowego systemu o następujących poziomach:
- wrażliwe — własność intelektualna, PHI
- poufne — umowy z dostawcami, opinie pracowników
- prywatne — nazwy lub obrazy klientów
- zastrzeżone — procesy organizacyjne
- publiczne — informacje, które mogą zostać ujawnione każdemu
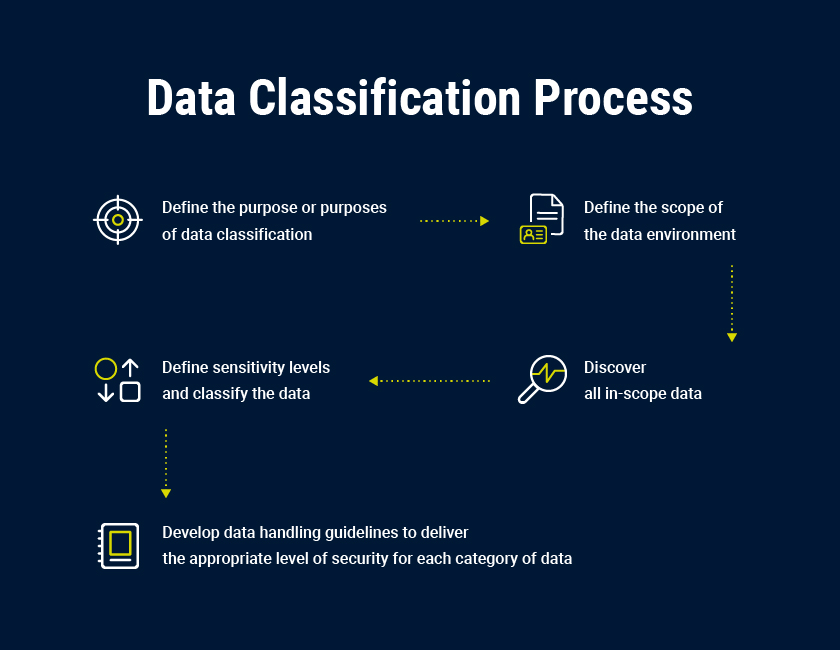
proces klasyfikacji danych
skuteczna klasyfikacja informacji w pięciu krokach
- ustal zasady klasyfikacji danych, w tym cele, przepływy pracy, schemat klasyfikacji danych, właścicieli danych i ich obsługi
- Zidentyfikuj przechowywane dane wrażliwe.
- Zastosuj etykiety, oznaczając dane.
- użyj wyników, aby poprawić bezpieczeństwo i zgodność.
- dane są dynamiczne, a klasyfikacja jest procesem ciągłym.
budowanie skutecznej polityki klasyfikacji danych
Polityka klasyfikacji danych to dokument, który zawiera ramy klasyfikacji, listę obowiązków w zakresie identyfikacji danych wrażliwych oraz opisy różnych poziomów klasyfikacji danych.
dobra polityka klasyfikacji:
- używa kryteriów, które są proste i unikają dwuznaczności, ale które są wystarczająco OGÓLNE, Aby zastosować je do różnych zestawów danych i okoliczności
- jest jasne i napisane prostym językiem
- pasuje do działalności organizacji
- jest ograniczony do 3 lub 4 poziomów klasyfikacji
- zawiera punkt kontaktowy w celu wyjaśnienia
- ustanawia przegląd harmonogram
jak wybrać rozwiązanie klasyfikacji danych
poszukaj tych funkcji:
- wyszukiwanie złożone — poprawia dokładność poprzez minimalizację fałszywych alarmów i fałszywych negatywów.
- indeks-umożliwia identyfikację wrażliwych terminów bez ponownego przeszukiwania danych.
- Elastyczny menedżer taksonomii-ułatwia dodawanie i modyfikowanie terminów i reguł.
- przepływy pracy — Automatycznie wykonuje określone działania, gdy dokument jest klasyfikowany w określony sposób. Na przykład przepływ pracy może przenieść poufne dane z udziału publicznego.
- szeroki zasięg — obsługuje zarówno źródła danych w chmurze, jak i lokalne, w tym dane strukturalne i nieustrukturyzowane.
FAQ
jaki jest cel klasyfikacji danych?
klasyfikacja danych sortuje dane na kategorie na podstawie ich wartości i czułości.
dlaczego klasyfikacja danych jest ważna? Jakie korzyści oferuje?
klasyfikacja danych pomaga nadać priorytet wysiłkom w zakresie ochrony danych w celu poprawy bezpieczeństwa danych i zgodności z przepisami. Poprawia również produktywność użytkowników i podejmowanie decyzji oraz obniża koszty, umożliwiając eliminację niepotrzebnych danych.
jakie są wspólne poziomy klasyfikacji danych?
dane są często klasyfikowane jako publiczne, poufne, wrażliwe lub osobiste.
jakie są typy klasyfikacji danych?
klasyfikacja może być oparta na treści, kontekście lub na użytkowniku (podręcznik).
jakiego oprogramowania powinienem użyć do klasyfikacji danych?
poszukaj oprogramowania do klasyfikacji danych, takiego jak oferowane przez Netwrix, które:
- wykorzystuje wyszukiwanie złożonych słów, aby zapewnić dokładną klasyfikację, która minimalizuje fałszywe alarmy
- ma indeks, dzięki czemu można znaleźć wrażliwe terminy bez ponownego indeksowania sklepów danych
- zawiera elastyczny menedżer taksonomii, który umożliwia dostosowanie parametrów klasyfikacji
- zapewnia przepływy pracy w celu automatyzacji procesów, takich jak migracja poufnych danych z akcji publicznych
- obsługuje zarówno lokalne i chmurowe źródła treści, w tym zarówno dane strukturalne, jak i nieustrukturyzowane
kto jest odpowiedzialny za klasyfikację danych w organizacja?
organizacje zazwyczaj wyznaczają menedżera ds. bezpieczeństwa i ryzyka, menedżera ds. ochrony danych, Komitet ds. zgodności lub podobny podmiot.

wiceprezes ds. zarządzania produktami w Netwrix. Ilia jest odpowiedzialna za wizję i strategię produktu Netwrix. Jest uznanym ekspertem w dziedzinie bezpieczeństwa informacji i oficjalnym członkiem Rady technologicznej Forbes. Ilia posiada ponad 15-letnie doświadczenie na rynku oprogramowania do zarządzania IT. Na blogu Netwrix Ilia koncentruje się na trendach cyberbezpieczeństwa, strategiach i ocenie ryzyka.
