Non-uniform memory access (NUMA) jest architekturą pamięci współdzielonej używaną w dzisiejszych systemach wieloprocesorowych. Każdy procesor ma przypisaną własną pamięć lokalną i może uzyskać dostęp do pamięci z innych procesorów w systemie. Lokalny dostęp do pamięci zapewnia niskie opóźnienia – wysoką przepustowość. Podczas uzyskiwania dostępu do pamięci posiadanej przez inny procesor ma wyższe opóźnienia i niższą przepustowość. Nowoczesne aplikacje i systemy operacyjne, takie jak ESXi, domyślnie obsługują NUMA, jednak aby zapewnić najlepszą wydajność, konfiguracja maszyny wirtualnej powinna odbywać się z myślą o architekturze NUMA. Jeśli projekt jest nieprawidłowy, to dla danej maszyny Wirtualnej lub w najgorszym przypadku dla wszystkich maszyn wirtualnych działających na tym hoście ESXi wystąpi niespójne zachowanie lub ogólna degradacja wydajności.
ta seria ma na celu dostarczenie wglądu w architekturę procesora, podsystem pamięci oraz procesor ESXi i harmonogram pamięci. Pozwalając na stworzenie wysokowydajnej platformy, która stanowi fundament dla wyższych usług i zwiększonych współczynników konsolidacji. Zanim przejdziemy do nowoczesnych architektur obliczeniowych, warto przejrzeć historię architektur wieloprocesorowych pamięci współdzielonej, aby zrozumieć, dlaczego obecnie używamy systemów NUMA.
- ewolucja architektury wieloprocesorów pamięci współdzielonej w ostatnich dziesięcioleciach
- wprowadzenie buforowania protokołów snoop
- Uniform Memory Access Architecture
- niejednolita Architektura dostępu do pamięci
- 1: niejednolita organizacja dostępu do pamięci
- 2: Point-to-Point interconnect
- 3: skalowalna spójność pamięci podręcznej
- nie przeplatane włączone NUMA = SUMA
- Nehalem &przegląd mikroarchitektury rdzenia
ewolucja architektury wieloprocesorów pamięci współdzielonej w ostatnich dziesięcioleciach
wydaje się, że architektura o nazwie Uniform Memory Access byłaby lepszym rozwiązaniem przy projektowaniu spójnej platformy o niskim opóźnieniu i dużej przepustowości. Jednak nowoczesne architektury systemowe ograniczą go do bycia prawdziwie jednolitym. Aby zrozumieć przyczynę tego, musimy cofnąć się do historii, aby zidentyfikować kluczowe czynniki obliczeniowe równoległe.
wraz z wprowadzeniem relacyjnych baz danych na początku lat siedemdziesiątych zapotrzebowanie na systemy mogące obsługiwać wiele jednoczesnych operacji użytkowników i nadmierne generowanie danych stało się głównym nurtem. Pomimo imponującej wydajności uniprocesorów, systemy wieloprocesorowe były lepiej wyposażone do obsługi tego obciążenia. Aby zapewnić opłacalny system, przestrzeń adresowa pamięci współdzielonej stała się przedmiotem badań. Na początku zalecano systemy wykorzystujące przełącznik poprzeczny, jednak złożoność projektu została skalowana wraz ze wzrostem liczby procesorów, co uatrakcyjniło system oparty na magistrali. Procesory w systemie magistrali mają dostęp do całej przestrzeni pamięci poprzez wysyłanie żądań na magistrali, co jest bardzo opłacalnym sposobem na optymalne wykorzystanie dostępnej pamięci.
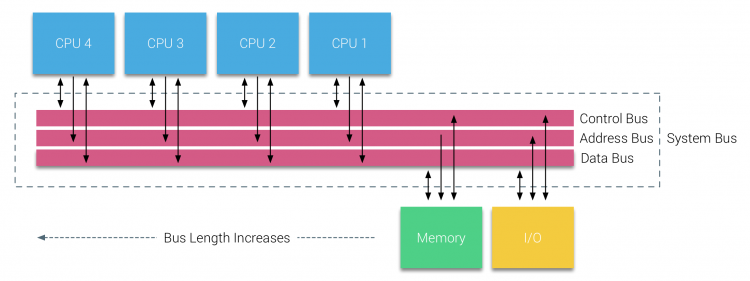
jednak systemy oparte na magistrali mają własne problemy ze skalowalnością. Głównym problemem jest ograniczona ilość przepustowości, co ogranicza liczbę procesorów, które może pomieścić magistrala. Dodanie procesorów do systemu wprowadza dwa główne obszary zainteresowania:
- dostępna przepustowość na węzeł maleje wraz z każdym dodanym procesorem.
- długość szyny zwiększa się po dodaniu większej liczby procesorów, zwiększając tym samym opóźnienie.
wzrost wydajności procesora, a w szczególności różnica prędkości między procesorem a wydajnością pamięci, była i nadal jest katastrofalna dla wieloprocesorów. Ponieważ oczekiwano, że luka w pamięci między procesorem a pamięcią wzrośnie, wiele wysiłku włożył się w opracowanie skutecznych strategii zarządzania systemami pamięci. Jedną z tych strategii było dodanie pamięci podręcznej, która wprowadziła wiele wyzwań. Rozwiązywanie tych problemów jest nadal głównym celem dzisiejszych zespołów projektowych procesorów, wiele badań jest prowadzonych na strukturach buforowania i wyrafinowanych algorytmów, aby uniknąć braków w pamięci podręcznej.
wprowadzenie buforowania protokołów snoop
dołączenie pamięci podręcznej do każdego procesora zwiększa wydajność na wiele sposobów. Przybliżenie pamięci do procesora skraca średni czas dostępu do pamięci i jednocześnie zmniejsza obciążenie przepustowości magistrali pamięci. Wyzwaniem związanym z dodaniem pamięci podręcznej do każdego procesora w architekturze pamięci współdzielonej jest to, że pozwala ona na istnienie wielu kopii bloku pamięci. Nazywa się to problemem spójności pamięci podręcznej. Aby rozwiązać ten problem, wymyślono buforowanie protokołów snoop, próbując stworzyć model, który dostarczy poprawne dane, nie próbując jednocześnie zjeść całej przepustowości w magistrali. Najpopularniejszy protokół, write invalidate, usuwa wszystkie inne kopie danych przed zapisaniem lokalnej pamięci podręcznej. Każdy kolejny odczyt tych danych przez inne procesory wykryje brak pamięci podręcznej w ich lokalnej pamięci podręcznej i będzie obsługiwany z pamięci podręcznej innego procesora zawierającego Ostatnio zmodyfikowane dane. Model ten zaoszczędził dużo przepustowości magistrali i pozwolił na stworzenie jednolitych systemów dostępu do pamięci na początku lat 90. XX wieku.nowoczesne protokoły spójności pamięci podręcznej zostały omówione bardziej szczegółowo w części 3.
Uniform Memory Access Architecture
Procesory wieloprocesorów opartych na magistralach, które mają ten sam jednolity czas dostępu do dowolnego modułu pamięci w systemie, są często określane jako systemy uma (Uniform Memory Access) lub symetryczne Wieloprocesory (SMPs).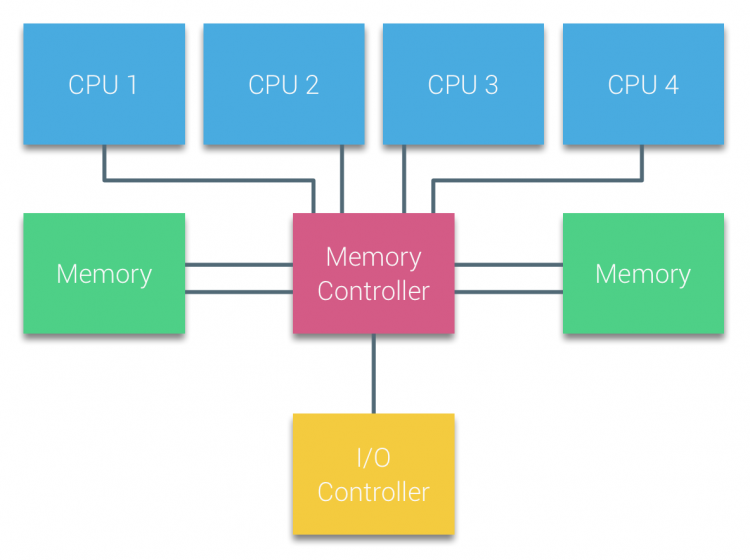
w systemach UMA procesory są podłączane za pomocą magistrali systemowej (Magistrala frontowa) do Mostu Północnego. Mostek północny zawiera kontroler pamięci i cała komunikacja do i z pamięci musi przebiegać przez mostek północny. Kontroler WE/WY, odpowiedzialny za zarządzanie We / Wy na wszystkich urządzeniach, jest podłączony do Mostu Północnego. Dlatego każde wejście / wyjście musi przejść przez mostek północny, aby dotrzeć do procesora.
wiele magistral i kanałów Pamięci są używane do podwojenia dostępnej przepustowości i zmniejszenia wąskiego gardła Mostu Północnego. Aby jeszcze bardziej zwiększyć przepustowość pamięci, niektóre systemy podłączyły zewnętrzne kontrolery pamięci do Mostu Północnego, poprawiając przepustowość i obsługę większej ilości pamięci. Jednak ze względu na wewnętrzną przepustowość Mostu Północnego i charakter nadawania wczesnych protokołów snoopy cache, UMA została uznana za mającą ograniczoną skalowalność. Przy dzisiejszym użyciu szybkich urządzeń flash, przepychając setki tysięcy IO na sekundę, mieli całkowitą rację, że ta architektura nie będzie skalować dla przyszłych obciążeń.
niejednolita Architektura dostępu do pamięci
aby poprawić skalowalność i wydajność, wprowadzono trzy krytyczne zmiany w architekturze wieloprocesorów pamięci współdzielonej;
- niejednolita organizacja dostępu do pamięci
- Topologia połączeń punkt-punkt
- skalowalne rozwiązania spójności pamięci podręcznej
1: niejednolita organizacja dostępu do pamięci
NUMA odchodzi od scentralizowanej puli pamięci i wprowadza właściwości topologiczne. Klasyfikując lokalizację pamięci na podstawie długości ścieżki sygnału od procesora do pamięci, można uniknąć opóźnień i wąskich gardeł przepustowości. Odbywa się to poprzez przeprojektowanie całego systemu procesora i chipsetu. Architektura NUMA zyskała popularność pod koniec lat 90-tych, kiedy została wykorzystana na superkomputerach SGI, takich jak Cray Origin 2000. NUMA pomógł zidentyfikować lokalizację pamięci, w tym przypadku tych systemów, musieli się zastanawiać, w którym regionie pamięci, w którym chassis trzyma bity pamięci.
w pierwszej połowie tysiąclecia firma AMD wprowadziła NUMA na rynek korporacyjny, gdzie systemy UMA królowały. W 2003 roku wprowadzono rodzinę AMD Opteron, wyposażoną w zintegrowane kontrolery pamięci z każdym procesorem posiadającym wyznaczone banki pamięci. Każdy procesor ma teraz własną przestrzeń adresową pamięci. Zoptymalizowany system operacyjny NUMA, taki jak ESXi, umożliwia obciążenie pamięcią z obu przestrzeni adresów pamięci, jednocześnie optymalizując dostęp do pamięci lokalnej. Posłużmy się przykładem systemu z dwoma procesorami, aby wyjaśnić różnicę między lokalnym i zdalnym dostępem do pamięci w ramach jednego systemu.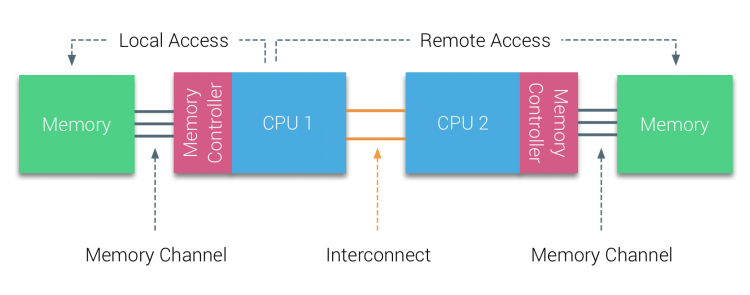
pamięć podłączona do kontrolera pamięci CPU1 jest uważana za pamięć lokalną. Pamięć podłączona do innego gniazda procesora (CPU2) jest uważana za zewnętrzną lub zdalną dla CPU1. Zdalny dostęp do pamięci ma dodatkowe opóźnienia w stosunku do lokalnego dostępu do pamięci, ponieważ musi przejść przez połączenie (połączenie punkt-punkt) i połączyć się ze zdalnym kontrolerem pamięci. W wyniku różnych lokalizacji pamięci system doświadcza „niejednorodnego” czasu dostępu do pamięci.
2: Point-to-Point interconnect
firma AMD wprowadziła HyperTransport połączenia point-to-point z mikroarchitekturą AMD Opteron. W 2007 roku Intel odszedł od architektury dual independent bus, wprowadzając architekturę QuickPath do rodziny procesorów Nehalem.
Architektura Nehalem była znaczącą zmianą konstrukcyjną w mikroarchitekturze Intela i jest uważana za pierwszą prawdziwą generację serii Intel Core. Obecna Architektura Broadwella to czwarta generacja marki Intel Core (Intel Xeon E5 v4), ostatni akapit zawiera więcej informacji na temat generacji mikroarchitektury. W architekturze QuickPath kontrolery pamięci przeniosły się do procesora i wprowadziły Quickpath point-to-point Interconnect (QPI) jako łącza danych między procesorami w systemie.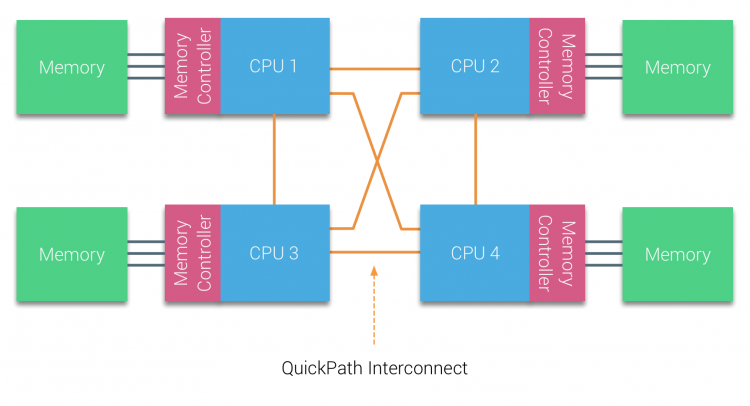
mikroarchitektura Nehalem nie tylko zastąpiła starszą magistralę przednią, ale zreorganizowała cały podsystem w modułową konstrukcję dla procesora serwerowego. Ta modułowa konstrukcja została wprowadzona jako „Uncore”i tworzy bibliotekę bloków konstrukcyjnych dla buforowania i prędkości połączeń. Usunięcie przedniej szyny poprawia problemy ze skalowalnością przepustowości, jednak komunikacja wewnątrz-i między procesorami musi zostać rozwiązana w przypadku ogromnej pojemności pamięci i przepustowości. Zarówno zintegrowany kontroler pamięci, jak i interkonekty QuickPath są częścią Uncore i są rejestrami specyficznymi dla modelu (MSR) ). Łączą się one z MSR, który zapewnia komunikację wewnątrz-i między procesorami. Modułowość Uncore pozwala również Intel oferować różne prędkości QPI, w momencie pisania Intel Broadwell-EP microarchitecture (2016) oferuje 6.4 Giga-transfery na sekundę (GT/S), 8.0 GT/S I 9.6 GT/s. odpowiednio zapewniając teoretyczną maksymalną przepustowość 25.6 GB/s, 32 Gb/s i 38.4 GB/S między procesorami. Aby to ująć w perspektywie, ostatnia używana Szyna przednia zapewniała przepustowość platformy 1,6 GT/s lub 12,8 GB/s. Podczas wprowadzania Sandy Bridge Intel zmienił nazwę Uncore na System Agent, jednak termin Uncore jest nadal używany w obecnej dokumentacji. Więcej o QuickPath i Uncore znajdziesz w części 2.
3: skalowalna spójność pamięci podręcznej
każdy rdzeń miał prywatną ścieżkę do pamięci podręcznej L3. Każda ścieżka składa się z tysiąca przewodów i możesz sobie wyobrazić, że nie skaluje się to dobrze, jeśli chcesz zmniejszyć proces wytwarzania nanometrów, jednocześnie zwiększając rdzenie, które chcą uzyskać dostęp do pamięci podręcznej. Aby móc skalować, Architektura Sandy Bridge przeniosła pamięć podręczną L3 z Uncore i wprowadziła skalowalny interkonekt ring on-die. Pozwoliło to Intelowi na dzielenie i dystrybucję pamięci podręcznej L3 w równych kawałkach. Zapewnia to większą przepustowość i asocjację. Każdy plasterek ma 2,5 MB i jeden plasterek jest powiązany z każdym rdzeniem. Pierścień umożliwia każdemu rdzeniowi dostęp do każdego innego plastra. Na zdjęciu poniżej znajduje się konfiguracja matrycy procesora Low Core Count (LCC) Xeon mikroarchitektury Broadwell (v4) (2016).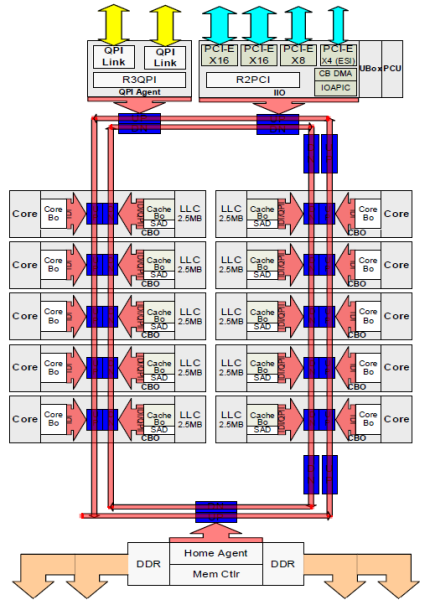
ta architektura buforowania wymaga protokołu snoopingowego, który zawiera zarówno rozproszoną lokalną pamięć podręczną, jak i inne procesory w systemie, aby zapewnić spójność pamięci podręcznej. Wraz z dodaniem większej liczby rdzeni w systemie, ilość ruchu snoop rośnie, ponieważ każdy rdzeń ma swój własny stały strumień pamięci podręcznej. Wpływa to na zużycie łączy QPI i pamięci podręcznych ostatniego poziomu, co wymaga ciągłego rozwoju protokołów koherencji snoop. Dogłębny widok Uncore, skalowalnego interkonektu ring on-Die I Znaczenie buforowania protokołów snoop dla wydajności NUMA zostaną uwzględnione w części 3.
nie przeplatane włączone NUMA = SUMA
pamięć fizyczna jest rozprowadzana na płycie głównej, jednak system może zapewnić pojedynczą przestrzeń adresową pamięci poprzez przeplot pamięci między dwoma węzłami NUMA. Nazywa się to przeplotem węzłów (ustawienie jest opisane w części 2). Gdy włączone jest przeplatanie węzłów, system staje się wystarczająco jednolitą architekturą pamięci (SUMA). Zamiast przekazywać informacje o topologii i naturze procesorów i pamięci w systemie do systemu operacyjnego, system rozkłada cały zakres pamięci na regiony adresowalne 4KB i mapuje je w sposób round robin z każdego węzła. Zapewnia to „przeplataną” strukturę pamięci, w której przestrzeń adresowa pamięci jest rozmieszczona między węzłami. Gdy ESXi przydziela pamięć do maszyny wirtualnej, to przydziela pamięć fizyczną znajdującą się z dwóch różnych węzłów gdy fizyczny procesor znajdujący się w węźle 0 musi pobrać pamięć z węzła 1, pamięć będzie przechodzić przez łącza QPI.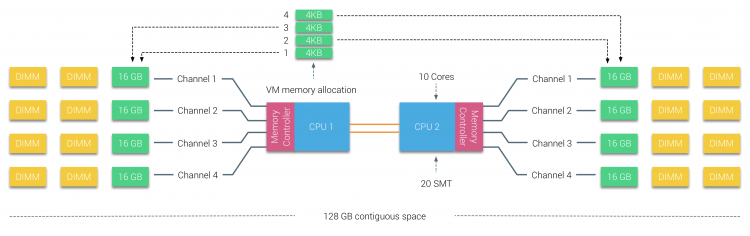
ciekawostką jest to, że system SUMA zapewnia jednolity czas dostępu do pamięci. Tylko nie najbardziej optymalny i w dużym stopniu zależy od poziomów sprzeczności w architekturze QPI. Intel Memory Latency Checker został użyty do zademonstrowania różnic między konfiguracją NUMA i sumy w tym samym systemie.
ten test mierzy opóźnienia w biegu jałowym (w nanosekundach) z każdego gniazda do drugiego gniazda w systemie. Opóźnienie zgłaszane węzła pamięci 0 przez gniazdo 0 to lokalny dostęp do pamięci, dostęp do pamięci z gniazda 0 węzła pamięci 1 to zdalny dostęp do pamięci w systemie skonfigurowanym jako NUMA.
| NUMA | węzeł pamięci 0 | węzeł pamięci 1 | – | SUMA | węzeł pamięci 0 | węzeł pamięci 1 |
| Gniazdo 0 | 75.7 | 132.0 | – | Socket 0 | 105.5 | 106.4 |
| Gniazdo 1 | 131.9 | 75.8 | – | Gniazdo 1 | 106.0 | 104.6 |
zgodnie z oczekiwaniami wpływ na przeplatanie ma ciągłe przechodzenie przez łącza QPI. Test pamięci bezczynności jest najlepszym scenariuszem, ciekawszym testem jest pomiar opóźnień w obciążeniu. To byłaby zła inwestycja, jeśli twoje serwery ESXi pracują na biegu jałowym, dlatego możesz założyć, że system ESXi przetwarza dane. Pomiar opóźnień w obciążeniu zapewnia lepszy wgląd w działanie systemu przy normalnym obciążeniu. Podczas testu opóźnienia wtrysku obciążenia są automatycznie zmieniane co 2 sekundy, a zarówno przepustowość, jak i odpowiadające jej opóźnienie są mierzone na tym poziomie. Ten test wykorzystuje 100% ruchu odczytu.Wyniki testu NUMA po lewej, wyniki testu SUMA po prawej.
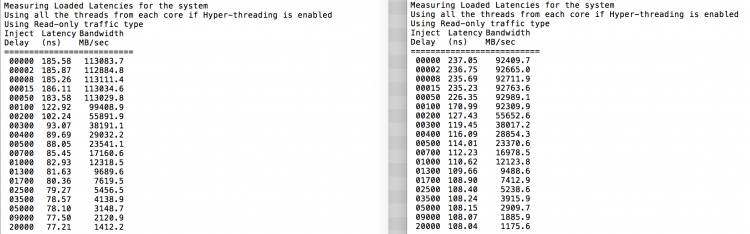
zgłoszona przepustowość dla systemu SUMA jest niższa, przy zachowaniu wyższego opóźnienia niż system skonfigurowany jako NUMA. Dlatego należy skupić się na optymalizacji rozmiaru maszyny Wirtualnej, aby wykorzystać charakterystykę NUMA systemu.
Nehalem &przegląd mikroarchitektury rdzenia
wraz z wprowadzeniem mikroarchitektury Nehalem w 2008 roku, Intel odszedł od architektury Netburst. Mikroarchitektura Nehalem wprowadziła klientów Intela do NUMA. Z biegiem lat Intel wprowadził nowe mikroarchitektury i optymalizacje, zgodnie ze swoim słynnym modelem Tick-Tock. Z każdym taktem następuje optymalizacja, kurczenie się technologii procesu i z każdym taktem wprowadzana jest nowa mikroarchitektura. Chociaż Intel zapewnia spójny model marki od 2012 roku, ludzie mają tendencję do nazw kodowych architektury Intel, aby omówić generacje procesora tick i tock. Nawet linie bazowe EVC wymieniają te wewnętrzne nazwy kodowe Intela, zarówno nazwy brandingowe, jak i nazwy kodowe architektury będą używane w tej serii:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26XX v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | kleszcz | 14 nm |
następnie część 2: Architektura systemu
seria głębokich nurkowań NUMA 2016:
część 0: wprowadzenie seria głębokich nurkowań NUMA
Część 1: od UMA do NUMA
część 2: Architektura systemu
Część 3: spójność pamięci podręcznej
Część 4: Optymalizacja pamięci lokalnej
Część 5: konstrukcje ESXi VMkernel NUMA