w tym samouczku wyjaśnimy, jedną z pojawiających się i wybitnych technik osadzania słów o nazwie Word2vec zaproponowanych przez Mikolova et al. w 2013 roku. Zebraliśmy te treści z różnych samouczków i źródeł, aby ułatwić czytelnikom w jednym miejscu. Mam nadzieję, że to pomoże.
Word2vec jest kombinacją modeli używanych do reprezentowania rozproszonych reprezentacji słów w korpusie C. word2vec (W2V) jest algorytmem, który akceptuje korpus tekstu jako wejście i wyświetla reprezentację wektorową dla każdego słowa, Jak pokazano na poniższym diagramie:

istnieją dwa warianty tego algorytmu: CBOW i Skip-gram. Biorąc pod uwagę zbiór zdań (zwany także korpusem), model pętli na słowa każdego zdania i albo próbuje użyć bieżącego słowa w w celu przewidzenia swoich sąsiadów (tj. jego kontekstu), takie podejście nazywa się „Skip-Gram”, lub używa każdego z tych kontekstów do przewidzenia bieżącego słowa w, w tym przypadku metoda nazywa się „ciągłym workiem słów” (Cbow). Aby ograniczyć liczbę słów w każdym kontekście, używany jest parametr o nazwie „rozmiar okna”.

wektory, których używamy do reprezentowania słów, nazywane są neuronowymi osadzeniami słów, a reprezentacje są dziwne. Jedna rzecz opisuje drugą, chociaż te dwie rzeczy są diametralnie różne. Jak powiedział Elvis Costello: „pisanie o muzyce jest jak taniec o architekturze.”Word2vec” wektoryzuje ” słowa, a dzięki temu sprawia, że język naturalny jest czytelny komputerowo-możemy zacząć wykonywać potężne operacje matematyczne na słowach, aby wykryć ich podobieństwa.
tak więc osadzenie słowa neuronowego reprezentuje słowo z liczbami. To proste, ale mało prawdopodobne tłumaczenie. Word2vec jest podobny do autoencodera, koduje każde słowo w wektorze, ale zamiast trenować przeciwko słowom wejściowym poprzez rekonstrukcję, jak robi to ograniczona maszyna Boltzmanna, word2vec szkoli słowa przeciwko innym słowom, które sąsiadują z nimi w korpusie wejściowym.
robi to na jeden z dwóch sposobów, albo używając kontekstu do przewidzenia docelowego słowa (metoda znana jako ciągły worek słów lub CBOW), albo używając słowa do przewidzenia docelowego kontekstu, który nazywa się skip-gram. Używamy tej drugiej metody, ponieważ zapewnia dokładniejsze wyniki na dużych zbiorach danych.

gdy wektor funkcji przypisany do słowa nie może być użyty do dokładnego przewidzenia kontekstu tego słowa, składniki wektora są dostosowywane. Kontekst każdego słowa w korpusie polega na tym, że nauczyciel wysyła sygnały o błędach z powrotem, aby dostosować wektor funkcji. Wektory wyrazów ocenianych podobnie według ich kontekstu są zbliżone do siebie poprzez dopasowanie liczb w wektorze. W tym samouczku skupimy się na modelu Skip-Gram, który w przeciwieństwie do CBOW uważa słowo środkowe za dane wejściowe, jak przedstawiono na rysunku powyżej i przewiduje słowa kontekstowe.
przegląd modelu
zrozumieliśmy, że musimy karmić jakąś dziwną sieć neuronową kilkoma parami słów, ale nie możemy tego zrobić, używając jako danych wejściowych rzeczywistych znaków, musimy znaleźć sposób na Matematyczne przedstawienie tych słów, aby sieć mogła je przetworzyć. Jednym ze sposobów, aby to zrobić, jest stworzenie słownictwa wszystkich słów w naszym tekście, a następnie zakodowanie naszego słowa jako wektora o tych samych wymiarach naszego słownictwa. Każdy wymiar może być pomyślany jako słowo w naszym słownictwie. Więc będziemy mieli wektor ze wszystkimi zerami i 1, który reprezentuje odpowiednie słowo w słowniku. Ta technika kodowania nazywa się kodowaniem jedno-gorącym. Biorąc pod uwagę nasz przykład, jeśli mamy słownictwo złożone ze słów „the”, „quick”, „brown”, „fox”, „jumps”, „over”, „the” „lazy”, „dog”, słowo „brown” jest reprezentowane przez ten wektor: .

Model Skip-gram przyjmuje korpus tekstu i tworzy wektor gorący dla każdego słowa. Wektor gorący to wektorowa reprezentacja wyrazu, w której wektor jest wielkością słownictwa (total unique words). Wszystkie wymiary są ustawione na 0, z wyjątkiem wymiaru reprezentującego słowo, które jest używane jako dane wejściowe w tym momencie. Oto przykład wektora gorącego:

powyższe dane wejściowe są przekazywane do sieci neuronowej z pojedynczą warstwą ukrytą.
będziemy reprezentować słowo wejściowe, takie jak „mrówki”, jako wektor jednowymiarowy. Wektor ten będzie miał 10 000 elementów (po jednym dla każdego słowa w naszym słownictwie) i umieścimy „1” w pozycji odpowiadającej słowu „mrówki”, a 0s we wszystkich innych pozycjach. Wyjście sieci jest pojedynczym wektorem (również z 10 000 składowych) zawierającym, dla każdego słowa w naszym słowniku, prawdopodobieństwo, że losowo wybrane pobliskie słowo jest tym słownikiem.
w word2vec używana jest rozproszona reprezentacja słowa. Weźmy wektor o kilkuset wymiarach (powiedzmy 1000). Każde słowo jest reprezentowane przez rozkład wag między tymi elementami. Więc zamiast mapowania jeden do jednego między elementem w wektorze a słowem, reprezentacja słowa jest rozłożona na wszystkie elementy w wektorze, a każdy element w wektorze przyczynia się do definicji wielu słów.
jeśli oznaczę wymiary w hipotetycznym wektorze słowa (oczywiście nie ma takich przypisanych etykiet w algorytmie), może to wyglądać trochę tak:

taki wektor przedstawia w jakiś abstrakcyjny sposób 'Znaczenie’ słowa. I jak zobaczymy dalej, po prostu badając duże ciało, można nauczyć się wektorów słów, które są w stanie uchwycić relacje między słowami w zaskakująco ekspresyjny sposób. Możemy również użyć wektorów jako danych wejściowych do sieci neuronowej. Ponieważ nasze wektory wejściowe są jedno-gorące, pomnożenie wektora wejściowego przez macierz wagową W1 oznacza po prostu wybranie wiersza z W1.
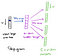

od warstwy ukrytej do warstwy wyjściowej, druga macierz wagowa W2 może być użyta do obliczenia wyniku dla każdego słowa w słownictwie, a softmax może być użyty do uzyskania tylnego rozkładu słów. Model skip-gram jest przeciwieństwem modelu CBOW. Jest on zbudowany ze słowa focus jako pojedynczego wektora wejściowego, a docelowe słowa kontekstowe znajdują się teraz na warstwie wyjściowej. Funkcja aktywacji warstwy ukrytej polega po prostu na skopiowaniu odpowiedniego wiersza z macierzy wag W1 (liniowej), jak widzieliśmy wcześniej. Na warstwie wyjściowej wyprowadzamy teraz C rozkładów wielomianowych, a nie tylko jeden. Celem szkolenia jest naśladowanie sumowanego błędu predykcji we wszystkich słowach kontekstowych w warstwie wyjściowej. W naszym przykładzie wejście byłoby „uczące się”i mamy nadzieję zobaczyć („an”,” efficient”,” method”,” for”,” high”,” quality”,” distributed”,” vector”) na warstwie wyjściowej.
oto Architektura naszej sieci neuronowej.

dla naszego przykładu powiemy, że uczymy się wektorów słowa z 300 funkcjami. Więc ukryta warstwa będzie reprezentowana przez macierz wagową z 10 000 wierszy (po jednym dla każdego słowa w naszym słownictwie) i 300 kolumn (po jednym dla każdego ukrytego neuronu). 300 funkcji jest to, co Google wykorzystał w swoim opublikowanym modelu szkolenia w Google news dataset (można go pobrać stąd). Liczba funkcji jest „hyper parametrem”, który trzeba by tylko dostroić do aplikacji (czyli wypróbować różne wartości i zobaczyć, co daje najlepsze wyniki).
jeśli spojrzysz na rzędy tej macierzy wagowej, to będą to nasze wektory słowne!

tak więc ostatecznym celem tego wszystkiego jest nauczenie się tej ukrytej macierzy wagowej warstwy – warstwy wyjściowej, którą po prostu rzucimy, kiedy skończymy! 1 x 300 słowo wektor dla „mrówki” następnie dostaje się do warstwy wyjściowej. Warstwa wyjściowa jest klasyfikatorem regresji softmax. W szczególności, każdy neuron wyjściowy ma wektor wagi, który mnoży względem słowa wektor z ukrytej Warstwy, a następnie stosuje funkcję exp (x) do wyniku. Na koniec, aby uzyskać wynik sumujący się do 1, dzielimy ten wynik przez sumę wyników ze wszystkich 10 000 węzłów wyjściowych. Oto ilustracja obliczania wyjścia neuronu wyjściowego dla słowa „samochód”.

jeśli dwa różne słowa mają bardzo podobne „konteksty” (to znaczy, jakie słowa mogą pojawić się wokół nich), to nasz model musi uzyskać bardzo podobne wyniki dla tych dwóch słów. I jednym ze sposobów, aby sieć wyprowadzała podobne predykcje kontekstowe dla tych dwóch słów, jest to, że słowo wektory jest podobne. Tak więc, jeśli dwa słowa mają podobne konteksty, to nasza sieć jest zmotywowana do uczenia się podobnych wektorów słów dla tych dwóch słów! Ta da!
każdy wymiar wejścia przechodzi przez każdy węzeł warstwy ukrytej. Wymiar jest mnożony przez ciężar prowadzący go do ukrytej warstwy. Ponieważ wejście jest wektorem gorącym, tylko jeden z węzłów wejściowych będzie miał wartość niezerową (czyli wartość 1). Oznacza to, że dla słowa zostanie aktywowana tylko waga powiązana z węzłem wejściowym o wartości 1, Jak pokazano na powyższym obrazku.
ponieważ wejście w tym przypadku jest wektorem gorącym, tylko jeden z węzłów wejściowych będzie miał wartość niezerową. Oznacza to, że tylko wagi podłączone do tego węzła wejściowego będą aktywowane w ukrytych węzłach. Przykład wag, które będą brane pod uwagę, jest przedstawiony poniżej dla drugiego słowa w słownictwie:
reprezentacja wektorowa drugiego słowa w słownictwie (pokazana w sieci neuronowej powyżej) będzie wyglądać następująco, po aktywacji w ukrytej warstwie:
te wagi zaczynają się jako wartości losowe. Sieć jest następnie szkolona w celu dostosowania wag do reprezentowania słów wejściowych. W tym miejscu warstwa wyjściowa staje się ważna. Teraz, gdy jesteśmy w ukrytej warstwie z wektorową reprezentacją słowa, potrzebujemy sposobu, aby określić, jak dobrze przewidzieliśmy, że słowo będzie pasować do określonego kontekstu. Kontekst słowa Jest zbiorem słów w oknie wokół niego, jak pokazano poniżej:

powyższy obrazek pokazuje, że kontekst na piątek zawiera słowa takie jak” kot „i”jest”. Celem sieci neuronowej jest przewidywanie, że „piątek” mieści się w tym kontekście.
aktywujemy warstwę wyjściową, mnożąc wektor, który przeszliśmy przez warstwę ukrytą (która była wejściowym wektorem gorącym * wag wchodzących do węzła ukrytego) z wektorową reprezentacją słowa kontekstowego (która jest wektorem gorącym dla słowa kontekstowego * wag wchodzących do węzła wyjściowego). Stan warstwy wyjściowej dla pierwszego słowa kontekstowego można zwizualizować poniżej:

powyższe mnożenie odbywa się dla każdej pary wyrazów kontekstowych. Następnie obliczamy prawdopodobieństwo, że słowo należy do zestawu słów kontekstowych, używając wartości wynikających z warstwy ukrytej i wyjściowej. Na koniec, stosujemy stochastyczne obniżenie gradientu, aby zmienić wartości wag, aby uzyskać bardziej pożądaną wartość dla obliczonego prawdopodobieństwa.
w spadku gradientu musimy obliczyć gradient funkcji optymalizowanej w punkcie reprezentującym wagę, którą zmieniamy. Gradient jest następnie używany do wyboru kierunku, w którym należy wykonać krok w kierunku lokalnego optimum, jak pokazano w poniższym przykładzie minimalizacji.
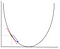
waga zostanie zmieniona, wykonując krok w kierunku punktu optymalnego (w powyższym przykładzie najniższy punkt na wykresie). Nowa wartość jest obliczana przez odjęcie od bieżącej wartości wagi pochodnej funkcji w punkcie wagi skalowanej przez szybkość uczenia się. Następnym krokiem jest użycie Backpropagacji, aby dostosować ciężary między wieloma warstwami. Błąd obliczany na końcu warstwy wyjściowej jest przekazywany z powrotem z warstwy wyjściowej do warstwy ukrytej poprzez zastosowanie reguły łańcucha. Gradientowe zejście służy do aktualizacji ciężarów między tymi dwiema warstwami. Błąd jest następnie dostosowywany na każdej warstwie i odsyłany dalej. Oto diagram przedstawiający backpropagację:

zrozumienie za pomocą przykładu
Word2vec wykorzystuje pojedynczą ukrytą warstwę, w pełni połączoną sieć neuronową, jak pokazano poniżej. Neurony w ukrytej warstwie są neuronami liniowymi. Warstwa wejściowa jest ustawiona tak, aby miała tyle neuronów, ile słów w słownictwie do treningu. Rozmiar ukrytej warstwy jest ustawiony na wymiarowość wynikowego słowa wektory. Rozmiar warstwy wyjściowej jest taki sam jak warstwy wejściowej. Tak więc, jeśli słownictwo do nauki wektorów wyrazów składa się ze słów V, A N jest wymiarem wektorów wyrazów, wejście do połączeń warstw ukrytych może być reprezentowane przez macierz WI o rozmiarze VxN z każdym wierszem reprezentującym słowo słownikowe. W ten sam sposób połączenia od warstwy ukrytej do warstwy wyjściowej można opisać za pomocą macierzy WO o rozmiarze NxV. W tym przypadku każda kolumna macierzy WO reprezentuje słowo z danego słownictwa.

wejście do sieci jest kodowane za pomocą reprezentacji „1-out of-V”, co oznacza, że tylko jedna linia wejściowa jest ustawiona na jedną, a reszta linii wejściowych na zero.
Załóżmy, że mamy korpus szkoleniowy zawierający następujące zdania:
„pies zobaczył kota”, „pies gonił kota”, „kot wspiął się na drzewo”
słownictwo korpusu składa się z ośmiu słów. Po uporządkowaniu alfabetycznym każde słowo może być odwołane przez jego indeks. W tym przykładzie nasza sieć neuronowa będzie miała osiem neuronów wejściowych i osiem neuronów wyjściowych. Załóżmy, że decydujemy się na użycie trzech neuronów w ukrytej warstwie. Oznacza to, że WI i WO będą odpowiednio macierzami 8×3 i 3×8. Przed rozpoczęciem treningu, macierze te są inicjowane do małych losowych wartości, jak to zwykle w treningu sieci neuronowych. Dla ilustracji Załóżmy, że WI i WO zostaną zainicjalizowane na następujące wartości:

Załóżmy, że chcemy, aby sieć nauczyła się relacji między słowami ” kot ” i „wspiął się”. Oznacza to, że sieć powinna wykazywać wysokie prawdopodobieństwo „wspiął się”, gdy „cat” jest wprowadzony do sieci. W terminologii osadzania słów słowo ” kot „jest określane jako słowo kontekstowe, a słowo „wspiął się” jest określane jako słowo docelowe. W tym przypadku wektor wejściowy X będzie t. zauważ, że tylko drugi składnik wektora jest 1. Dzieje się tak, ponieważ słowo wejściowe to „cat”, które zajmuje pozycję numer dwa w posortowanej liście słów korpusu. Biorąc pod uwagę, że słowo docelowe to „climbed”, docelowy wektor będzie wyglądał jak t. z wektorem wejściowym reprezentującym „cat”, wyjście na neurony warstwy ukrytej można obliczyć jako:
Ht = XtWI =
nie powinno nas dziwić, że wektor H ukrytych wyjść neuronów naśladuje wagi drugiego rzędu macierzy WI z powodu 1-out-of-Vrepresentation. Tak więc funkcją wejścia do połączeń warstwy ukrytej jest w zasadzie skopiowanie wektora słowa wejściowego do warstwy ukrytej. Przeprowadzając podobne manipulacje dla ukrytej warstwy wyjściowej, wektor aktywacyjny dla neuronów warstwy wyjściowej można zapisać jako
HtWO =
ponieważ celem jest wytworzenie prawdopodobieństwa dla słów w warstwie wyjściowej, Pr(Wordk|wordcontext) dla k = 1, V, aby odzwierciedlić ich związek z następnym słowem w słowie kontekstowym na wejściu, potrzebujemy sumy wyjść neuronów w warstwie wyjściowej, aby dodać do jednego. Word2vec osiąga to poprzez konwersję wartości aktywacji neuronów warstwy wyjściowej do prawdopodobieństwa za pomocą funkcji softmax. W ten sposób wynik K-tego neuronu jest obliczany za pomocą następującego wyrażenia, w którym aktywacja(N) reprezentuje wartość aktywacji n-tego neuronu warstwy wyjściowej:
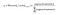
tak więc prawdopodobieństwo dla ośmiu słów w korpusie wynosi:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
prawdopodobieństwo pogrubioną czcionką jest dla wybranego słowa docelowego „wspiął się”. Biorąc pod uwagę wektor docelowy t, wektor błędu dla warstwy wyjściowej można łatwo obliczyć, odejmując wektor prawdopodobieństwa od wektora docelowego. Gdy błąd jest znany, wagi w matrycach wo i WI mogą być aktualizowane za pomocą funkcji backpropagation. W ten sposób trening może przebiegać poprzez prezentację innej pary słów kontekstowo-docelowych z korpusu. W ten sposób Word2vec uczy się relacji między słowami i w procesie rozwija reprezentacje wektorowe dla słów w korpusie.
ideą word2vec jest reprezentowanie słów przez wektor liczb rzeczywistych o wymiarze d. Zatem druga macierz jest reprezentacją tych słów. I-ta linia tej macierzy jest wektorową reprezentacją i-tego słowa. Powiedzmy, że w twoim przykładzie masz 5 słów :, wtedy pierwszy wektor oznacza, że rozważasz słowo ” Koń ” i tak reprezentacja „koń” jest . Podobnie jest reprezentacja słowa „Lew”.

o ile mi wiadomo, nie ma „ludzkiego znaczenia” specjalnie dla każdej z liczb w tych reprezentacjach. Jedna liczba nie reprezentuje, czy słowo jest czasownikiem, czy nie, przymiotnikiem, czy nie … to tylko wagi, które zmieniasz, aby rozwiązać problem optymalizacji, aby nauczyć się reprezentacji twoich słów.
schemat wizualny najlepiej rozwijający proces mnożenia macierzy word2vec przedstawiono na poniższym rysunku:

pierwsza macierz reprezentuje wektor wejściowy w jednym gorącym formacie. Druga matryca reprezentuje masy synaptyczne od neuronów warstwy wejściowej do neuronów warstwy ukrytej. Szczególnie zwróć uwagę na lewy górny róg, w którym macierz warstwy wejściowej jest mnożona przez macierz wagi. Spójrz na prawy górny róg. To mnożenie macierzy InputLayer Dot-producted z wagami Transpose jest tylko poręcznym sposobem reprezentowania sieci neuronowej w prawym górnym rogu.
pierwsza część reprezentuje słowo wejściowe jako jeden gorący wektor, a druga matryca reprezentuje wagę połączenia każdego z neuronów warstwy wejściowej z neuronami warstwy ukrytej. Jak word2vec trenuje, to backpropagates (za pomocą gradientowego zejścia) do tych wag i zmienia je, aby dać lepsze reprezentacje słów jako wektorów. Po zakończeniu treningu używasz tylko tej macierzy wagi, bierzesz na przykład ’ psa 'i mnożysz ją przez ulepszoną macierz wagi, aby uzyskać wektorową reprezentację’ psa ’ w wymiarze = liczba neuronów ukrytych warstw. Na diagramie liczba neuronów warstwy ukrytej wynosi 3.
w skrócie, Model Skip-gram odwraca użycie słów docelowych i kontekstowych. W takim przypadku słowo docelowe jest podawane na wejściu, warstwa ukryta pozostaje taka sama, a warstwa wyjściowa sieci neuronowej jest replikowana wielokrotnie, aby pomieścić wybraną liczbę słów kontekstowych. Na przykładzie „cat ” i” tree „jako słów kontekstowych i” climbed ” jako słowa docelowego, wektor wejściowy w modelu skim-gram będzie T, podczas gdy dwie warstwy wyjściowe będą miały odpowiednio T i t jako wektory docelowe. Zamiast wytworzenia jednego wektora prawdopodobieństwa, dla obecnego przykładu powstaną dwa takie wektory. Wektor błędu dla każdej warstwy wyjściowej jest wytwarzany w sposób opisany powyżej. Jednak wektory błędów ze wszystkich warstw wyjściowych są sumowane w celu dostosowania wag za pomocą backpropagacji. Gwarantuje to, że matryca wagowa WO dla każdej warstwy wyjściowej pozostaje identyczna przez cały trening.
potrzebujemy kilku dodatkowych modyfikacji podstawowego modelu skip-gram, które są ważne dla umożliwienia treningu. Zejście gradientowe na tak dużej sieci neuronowej będzie powolne. Co gorsza, potrzebujesz ogromnej ilości danych treningowych, aby dostroić tak wiele ciężarów i uniknąć nadmiernego dopasowania. miliony ciężarów razy miliardy próbek treningowych oznacza, że trening ten model będzie bestią. W tym celu autorzy zaproponowali dwie techniki zwane podpróbkowaniem i próbkowaniem negatywnym, w których znikome słowa są usuwane i aktualizowana jest tylko określona próbka wag.
Mikolov i in. użyj również prostego podejścia do podpróbkowania, aby przeciwdziałać nierównowadze między rzadkimi i częstymi słowami w zestawie treningowym (na przykład „in”, „the” I „A” zapewniają mniejszą wartość informacyjną niż rzadkie słowa). Każde słowo w zestawie treningowym jest odrzucane z prawdopodobieństwem P (wi), gdzie

f (wi) to częstotliwość słowa wi, A T to wybrany próg, zwykle około 10-5.
szczegóły implementacji
Word2vec został zaimplementowany w różnych językach, ale tutaj skupimy się szczególnie na Javie, tj., DeepLearning4j, darks-learning i python . Różne algorytmy sieci neuronowych zostały zaimplementowane w DL4j, kod jest dostępny na Githubie.
aby zaimplementować go w DL4j, wykonamy kilka kroków podanych w następujący sposób:
a) konfiguracja Word2Vec
Utwórz nowy projekt w IntelliJ przy użyciu Mavena. Następnie określ właściwości i zależności w POM.plik xml w katalogu głównym projektu.
B) załaduj dane
teraz Utwórz i nazwij nową klasę w Javie. Po tym, weźmiesz surowe zdania w swoim .plik txt, przejrzyj je za pomocą iteratora i poddaj je obróbce wstępnej, takiej jak konwersja wszystkich słów na małe litery.
String filePath = new ClassPathResource(„raw_sentences.txt”).getFile().getAbsolutePath();
log.info („Load & Wektoryzuj zdania….”);
// Usuń białe spacje przed i po każdej linii
SentenceIterator iter = new BasicLineIterator (filePath);
jeśli chcesz załadować plik tekstowy oprócz zdań podanych w naszym przykładzie, zrobisz to:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenizowanie danych
Word2vec muszą być podawane słowa, a nie całe zdania, więc następnym krokiem jest tokenizacja danych. Tokenizacja tekstu polega na rozbiciu go na jednostki atomowe, tworząc nowy token za każdym razem, gdy na przykład trafisz w białą spację.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) Szkolenie modelu
teraz, gdy dane są gotowe, możesz skonfigurować sieć neuronową Word2vec i podawać tokeny.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
Ta konfiguracja akceptuje kilka hiperparametrów. Kilka z nich wymaga wyjaśnień:
- batchSize to ilość słów przetwarzanych naraz.
- minwordczęstotliwość to minimalna liczba razy, gdy słowo musi pojawić się w korpusie. Tutaj, jeśli pojawia się mniej niż 5 razy, nie jest uczony. Słowa muszą pojawiać się w wielu kontekstach, aby poznać przydatne funkcje. W bardzo dużych korpusach rozsądne jest podniesienie minimum.
- użycieadagrad-Adagrad tworzy inny gradient dla każdej funkcji. Tutaj nie zajmujemy się tym.
- rozmiar warstwy określa liczbę funkcji w wektorze słowa. Jest to równe liczbie wymiarów w funkcji. Słowa reprezentowane przez 500 cech stają się punktami w 500-wymiarowej przestrzeni.
- learningRate to rozmiar kroku dla każdej aktualizacji współczynników, ponieważ słowa są zmieniane w przestrzeni funkcji.
- minLearningRate to Podłoga na stopie uczenia się. Tempo uczenia się maleje wraz ze spadkiem liczby słów, na których trenujesz. Jeśli wskaźnik uczenia się zmniejsza się zbytnio, nauka w sieci nie jest już efektywna. To utrzymuje współczynniki w ruchu.
- iterat informuje sieć, na której partii danych jest szkolona.
- tokenizer podaje mu słowa z bieżącej partii.
- fit() informuje skonfigurowaną sieć o rozpoczęciu treningu.
e) ocena modelu za pomocą Word2vec
następnym krokiem jest ocena jakości wektorów funkcji.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
linia vec.similarity("word1","word2") zwróci podobieństwo cosinusowe dwóch wpisanych słów. Im bliżej jest do 1, tym bardziej sieć postrzega te słowa jako podobne (patrz przykład Szwecja-Norwegia powyżej). Na przykład:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
dzięki vec.wordsNearest("word1", numWordsNearest) słowa wydrukowane na ekranie pozwalają zorientować się, czy w sieci znajdują się semantycznie podobne słowa. Możesz ustawić liczbę najbliższych słów za pomocą drugiego parametru wordsNearest. Na przykład:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec w Javie w http://deeplearning4j.org/word2vec.html
7) Word2Vec i Doc2Vec w Pythonie w genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html