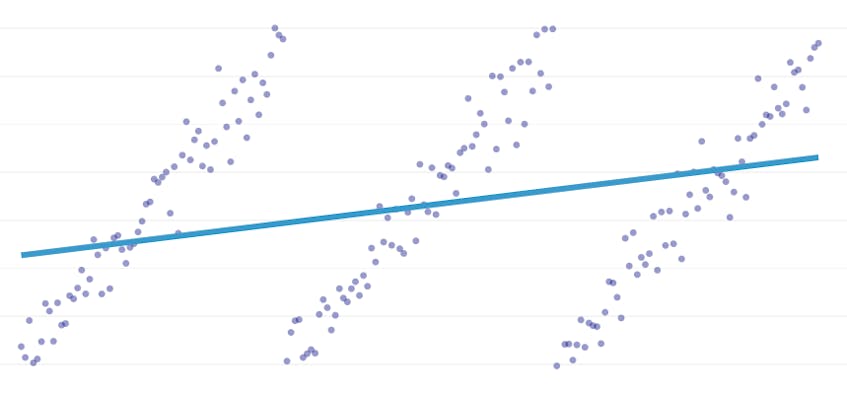
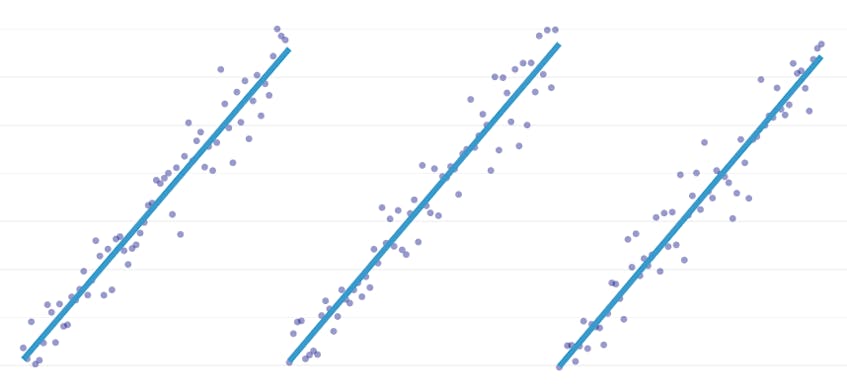
regresja fragmentaryczna jest specjalnym rodzajem regresji liniowej, która powstaje, gdy pojedyncza linia nie jest wystarczająca do modelowania zestawu danych. Regresja fragmentaryczna rozbija domenę na potencjalnie wiele „segmentów” i dopasowuje oddzielną linię do każdego z nich. Na przykład na poniższych wykresach pojedyncza linia nie jest w stanie modelować danych, a także regresji fragmentarycznej z trzema liniami:
ten post przedstawia podejście Datadog do automatyzacji regresji fragmentarycznej na danych szeregów czasowych.
cele
regresja Piecewise może oznaczać nieco inne rzeczy w różnych kontekstach, więc poświęćmy chwilę, aby wyjaśnić, co dokładnie staramy się osiągnąć za pomocą naszego algorytmu regresji piecewise.
Automatyczne wykrywanie punktów przerwania. W klasycznej literaturze statystycznej regresja fragmentaryczna jest często sugerowana podczas ręcznej analizy regresji, gdzie jest oczywiste gołym okiem, gdzie jeden trend liniowy ustępuje miejsca drugiemu. W takim przypadku człowiek może określić punkt przerwania między segmentami w kawałkach, podzielić zbiór danych i wykonać regresję liniową na każdym segmencie niezależnie. W naszych przypadkach użycia chcemy wykonywać setki regresji na sekundę, a nie jest możliwe, aby człowiek określił wszystkie punkty przerwania. Zamiast tego mamy wymóg, aby nasz algorytm regresji fragmentarycznej identyfikował własne punkty przerwania.
Automatyczne wykrywanie liczby segmentów. Gdybyśmy mieli wiedzieć, że zbiór danych ma dokładnie dwa segmenty, moglibyśmy łatwo przyjrzeć się każdej z możliwych par segmentów. Jednak w praktyce, gdy dany jest dowolny szereg czasowy, nie ma powodu, aby sądzić, że musi być więcej niż jeden segment lub mniej niż 3 lub 4 lub 5. Nasz algorytm musi wybrać odpowiednią liczbę segmentów bez konieczności określania jej przez użytkownika.
Brak wymogu ciągłości. Niektóre metody regresji fragmentarycznych generują połączone segmenty, gdzie punkt końcowy każdego segmentu jest punktem początkowym następnego segmentu. Nie nakładamy takiego wymogu na nasz algorytm.
wyzwania
najbardziej oczywistym wyzwaniem dla wdrożenia regresji fragmentarycznej z automatycznym wykrywaniem punktów przerwania jest duży rozmiar przestrzeni wyszukiwania rozwiązania; wyszukiwanie przy użyciu brutalnej siły wszystkich możliwych segmentów jest zbyt drogie. Liczba sposobów, w jaki szeregi czasowe można podzielić na segmenty, jest wykładnicza w długości szeregów czasowych. Podczas gdy programowanie dynamiczne może być używane do przeszukiwania tej przestrzeni wyszukiwania znacznie wydajniej niż naiwna implementacja brutalnej siły, w praktyce jest to nadal zbyt wolne. Potrzebny będzie chciwy heurysta, aby szybko odrzucić duże obszary przestrzeni wyszukiwania.
bardziej subtelnym wyzwaniem jest to, że potrzebujemy pewnego sposobu porównywania jakości jednego rozwiązania do drugiego. W przypadku naszej wersji problemu, z nieznaną liczbą i lokalizacją segmentów, musimy porównać potencjalne rozwiązania z różną liczbą segmentów i różnymi punktami przerwania. Staramy się zrównoważyć dwa konkurujące ze sobą cele:
- zminimalizuj błędy. Oznacza to, że linia regresji każdego segmentu zbliża się do obserwowanych punktów danych.
- użyj najmniejszej liczby segmentów, które dobrze modelują dane. Zawsze możemy uzyskać zerowy błąd, tworząc pojedynczy segment dla każdego punktu(lub nawet jeden segment dla każdego punktu). Nie nauczylibyśmy się niczego o ogólnej zależności między znacznikiem czasu a powiązaną z nim wartością metryczną i nie moglibyśmy łatwo użyć wyniku do interpolacji lub ekstrapolacji.
nasze rozwiązanie
używamy następującego algorytmu zachłannego dla problemu regresji piecewise:
- wykonaj regresję fragmentaryczną z n/2 segmentami, gdzie n to liczba obserwacji w szeregu czasowym. Linia regresji w każdym segmencie jest dopasowana za pomocą zwykłej regresji najmniejszych kwadratów (OLS). Ta początkowa regresja fragmentaryczna nie będzie miała prawie żadnego błędu, ale poważnie nada zestaw danych.
- iteracyjnie, dopóki nie będzie tylko jednego segmentu:
- dla wszystkich par sąsiednich segmentów Oceń wzrost całkowitego błędu, który spowodowałby połączenie dwóch segmentów, a ich dwie linie regresji zostaną zastąpione pojedynczą linią regresji.
- połącz ze sobą parę segmentów, co spowoduje najmniejszy wzrost błędu.
- jeśli wykonanie tego połączenia spełnia nasze kryteria zatrzymania (zdefiniowane poniżej), to mogliśmy posunąć się za daleko, łącząc dwa segmenty, które powinny pozostać oddzielne. W takim przypadku należy pamiętać o stanie segmentów sprzed scalenia tej iteracji.
- jeśli brak połączenia skutkował zapamiętywaniem stanu segmentów w (2C) powyżej, to najlepszym rozwiązaniem jest jeden duży segment. W przeciwnym razie najlepszym rozwiązaniem jest ostatni stan segmentu, który należy zapamiętać w (2c).
kryteria zatrzymania
uważamy, że połączenie jest potencjalnym punktem zatrzymania, jeśli zwiększa całkowitą sumę błędów do kwadratu o więcej niż jakiekolwiek poprzednie połączenie. Aby zapobiec zbyt szybkiemu zatrzymywaniu się w przypadkach, w których powinien istnieć tylko jeden segment, nie uznamy połączenia za potencjalny punkt zatrzymania, chyba że spowoduje to wzrost całkowitego błędu, który jest mniejszy niż 3% całkowitego błędu regresji z jednym segmentem. (3% jest arbitralnym progiem, ale okazało się, że działa dobrze w praktyce.) Poniżej kilka przykładów pokazujących, dlaczego to kryterium zatrzymania działa.
najpierw spójrzmy na zestaw danych, który został wygenerowany przez dodanie normalnie rozproszonego szumu do punktów wzdłuż pojedynczej linii. Algorytm poprawnie dopasowuje tylko jeden segment do tego zbioru danych.
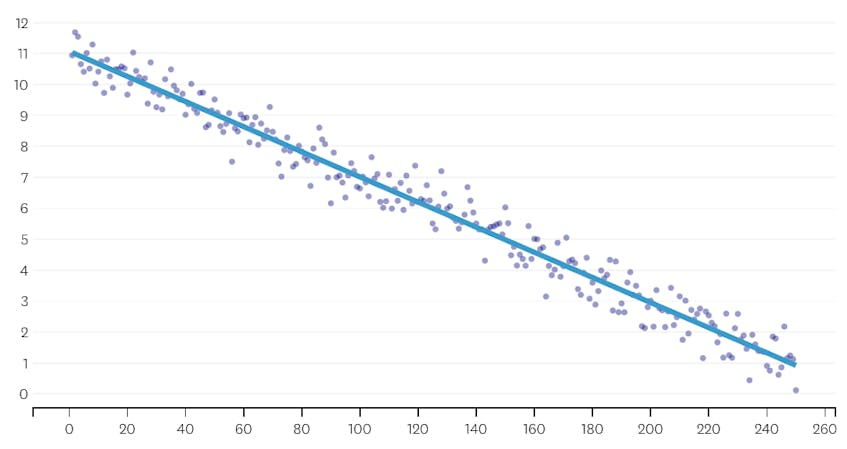
w tym przypadku żadne scalanie nigdy nie zwiększa całkowitej sumy błędów do kwadratu o więcej niż 3%. W związku z tym żadne scalanie nie jest uważane za odpowiedni punkt zatrzymania, a my używamy stanu końcowego po wykonaniu wszystkich scaleń. Na poniższym wykresie widzimy, że późniejsze połączenia mają tendencję do wprowadzania więcej błędów niż wcześniejsze (co ma sens, ponieważ każdy z nich wpływa na więcej punktów), ale wzrost błędu tylko stopniowo wzrasta, gdy więcej segmentów jest połączonych.
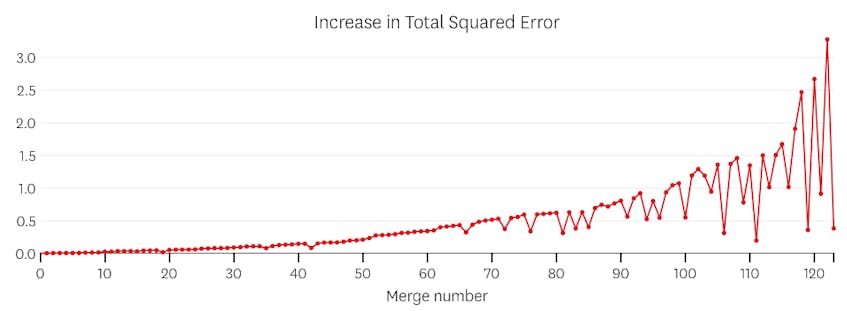
po drugie, spójrzmy na przykład, gdzie istnieje siedem odrębnych segmentów w zbiorze danych.
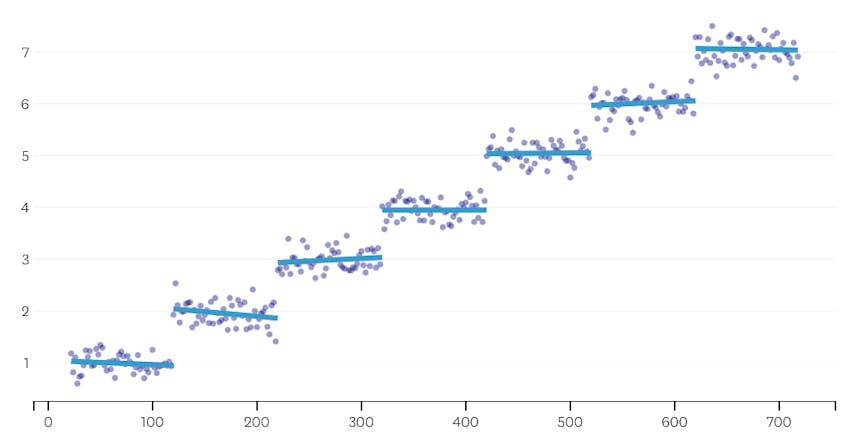
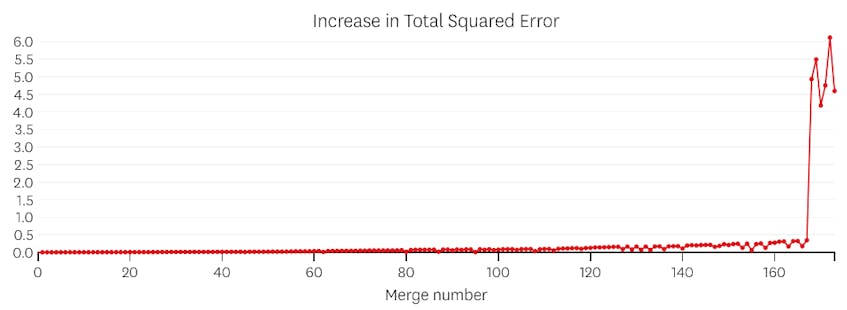
w tym przypadku, gdy spojrzymy na wykres błędów wprowadzanych przez każde połączenie, widzimy, że ostatnie sześć połączeń wprowadziło znacznie więcej błędów niż którykolwiek z poprzednich połączeń. Dlatego nasz algorytm zapamiętał stan segmentów sprzed połączenia od szóstego do ostatniego i użył go jako ostatecznego rozwiązania.
kod
w repo Datadog / piecewise Github znajdziesz naszą implementację algorytmu w Pythonie. Funkcja piecewise() jest miejscem, w którym odbywa się podnoszenie ciężarów; biorąc pod uwagę zestaw danych, zwróci współczynniki lokalizacji i regresji dla każdego z dopasowanych segmentów.
w gist znajduje się również plot_data_with_regression() — funkcja owijania do szybkiego i łatwego rysowania. Szybki przykład tego, jak można to wykorzystać:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)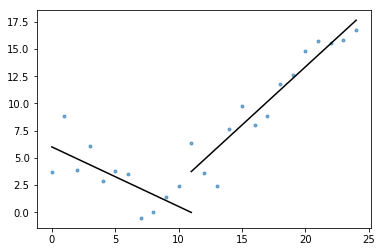
podczas gdy ta implementacja wykorzystuje regresję liniową OLS, te same ramy mogą być dostosowane do rozwiązywania powiązanych problemów. Zastępując błąd kwadratowy błędem absolutnym lub utratą Hubera, regresja może być solidna. Lub, funkcja Krokowa może być dopasowana przez przypisanie każdemu segmentowi stałej wartości równej średniej obserwacji w jego dziedzinie.