Ukryty Model Markowa (ang. Hidden Markov Model, HMM) – statystyczny model Markowa, w którym zakłada się, że modelowany system jest procesem Markowa z nieobserwowanymi (tj. ukrytymi) Stanami.
Ukryte modele Markowa są szczególnie znane ze swojego zastosowania w uczeniu wzmacniającym i rozpoznawaniu wzorców czasowych, takich jak mowa, pismo ręczne, rozpoznawanie gestów, oznaczanie części mowy, śledzenie partytur muzycznych, wyładowania częściowe i bioinformatyka.
termin „Ukryty” odnosi się do procesu Markowa pierwszego rzędu stojącego za obserwacją. Obserwacja odnosi się do danych, które znamy i możemy obserwować. Proces Markowa jest pokazany przez interakcję między ” deszczowym „i” słonecznym ” na poniższym diagramie, a każdy z nich jest stanem ukrytym.

obserwacje są znane Dane i odnosi się do „Spacer”,” sklep”, i” czyste ” w powyższym diagramie. W sensie uczenia maszynowego obserwacja jest naszymi danymi treningowymi, a liczba ukrytych Stanów jest naszym hiper parametrem dla naszego modelu. Ocena modelu zostanie omówiona później.

T = nie ma jeszcze żadnych obserwacji, N = 2, M = 3, Q = {„deszczowy”, „słoneczny”}, V = {„spacer”, „Sklep”, „czysty”}
prawdopodobieństwo przejścia stanu to strzałki wskazujące na każdy ukryty stan. Macierz prawdopodobieństwa obserwacji to niebieska i czerwona strzałka wskazująca każdą obserwację z każdego ukrytego stanu. Macierze są wierszami stochastycznymi, co oznacza, że wiersze sumują się do 1.


macierz wyjaśnia, jakie jest prawdopodobieństwo przechodzenia z jednego stanu do drugiego lub przechodzenia z jednego stanu do obserwacji.
Dystrybucja stanu początkowego powoduje, że model zaczyna się od stanu ukrytego.
pełny model ze znanymi prawdopodobieństwami przejścia stanu, macierzą prawdopodobieństwa obserwacji i początkowym rozkładem stanu jest oznaczony jako,
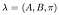
jak możemy zbudować powyższy model w Pythonie?
w powyższym przypadku emisje są dyskretne {„Walk”, „Shop”,”Clean”}. MultinomialHMM z biblioteki hmmlearn jest używany dla powyższego modelu. GaussianHMM i GMMHMM to inne modele w bibliotece.
teraz z HMM jakie są kluczowe problemy do rozwiązania?
- Problem 1, biorąc pod uwagę znany model, jakie jest prawdopodobieństwo wystąpienia sekwencji O?
- Problem 2, biorąc pod uwagę znany model i sekwencję O, jaka jest optymalna Sekwencja stanu ukrytego? Będzie to przydatne, jeśli chcemy wiedzieć, czy pogoda jest „deszczowa”, czy „słoneczna”
- Problem 3, biorąc pod uwagę sekwencję O i liczbę ukrytych Stanów, jaki jest optymalny model, który maksymalizuje prawdopodobieństwo O?
Problem 1 w Pythonie
prawdopodobieństwo, że pierwsza obserwacja będzie „chodzić” jest równe mnożeniu rozkładu stanu początkowego i macierzy prawdopodobieństwa emisji. 0, 6 x 0, 1 + 0, 4 x 0, 6 = 0, 30 (30%). Prawdopodobieństwo logowania jest dostarczane z wywołania .punkt.
Problem 2 w Pythonie

biorąc pod uwagę znany model i obserwację {„Sklep”, „czyste”, „spacer”}, pogoda była najprawdopodobniej {„deszczowa”, „deszczowa”, „Słoneczna”} z prawdopodobieństwem ~1,5%.
biorąc pod uwagę znany model i obserwację {„czysty”, „czysty”, „czysty”}, pogoda była najprawdopodobniej {„deszczowy”, „deszczowy”, „deszczowy”} z prawdopodobieństwem ~3,6%.
intuicyjnie, gdy wystąpi „spacer”, pogoda najprawdopodobniej nie będzie „deszczowa”.
Problem 3 w Pythonie
rozpoznawanie mowy z plikiem Audio: przewiduj te słowa

amplituda może być używana jako obserwacja dla HMM, ale Inżynieria funkcji da nam więcej wydajności.

funkcja stft i peakfind generuje funkcję dla sygnału audio.
powyższy przykład został wzięty stąd. Kyle Kastner zbudował klasę HMM, która zajmuje się tablicami 3D, używam hmmlearn, która pozwala tylko na tablice 2D. Dlatego redukuję funkcje generowane przez Kyle ’ a Kastnera jako X_test.średnia(oś=2).
przejście przez to modelowanie zajęło dużo czasu, aby zrozumieć. Miałem wrażenie, że zmienną docelową musi być obserwacja. Dotyczy to szeregów czasowych. Klasyfikacja odbywa się poprzez budowanie HMM dla każdej klasy i porównywanie wyników poprzez obliczanie logprob dla danych wejściowych.
Matematyczne rozwiązanie problemu 1: algorytm Forward

Przejście Alfa jest prawdopodobieństwem obserwacji i sekwencji Stanów danego modelu.
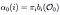
Alfa przechodzi w czasie (t) = 0, początkowy rozkład stanu do i, a stamtąd do pierwszej obserwacji O0.
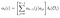
Przejście Alfa w czasie (t) = T, suma ostatniego przejścia alfa do każdego ukrytego stanu pomnożona przez emisję do Ot.
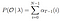
Matematyczne rozwiązanie problemu 2: Algorytm wsteczny


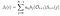

biorąc pod uwagę model i obserwację, prawdopodobieństwo bycia w stanie qi w czasie t.
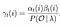
Matematyczne rozwiązanie problemu 3: Algorytm Forward-Backward


prawdopodobieństwo od stanu qi do qj w czasie t z danym modelem i obserwacją
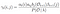
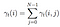
suma wszystkich prawdopodobieństw przejścia od i do j.
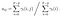
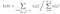
macierz prawdopodobieństwa przejścia i emisji jest szacowana za pomocą di-gamma.
Iteruj, jeśli prawdopodobieństwo P(O|model) wzrośnie