bitvis regression är en speciell typ av linjär regression som uppstår när en enda rad inte är tillräcklig för att modellera en datamängd. Bitvis regression bryter domänen i potentiellt många” segment ” och passar en separat linje genom var och en. Till exempel, i graferna nedan, kan en enda rad inte modellera data såväl som en bitvis regression med tre linjer:
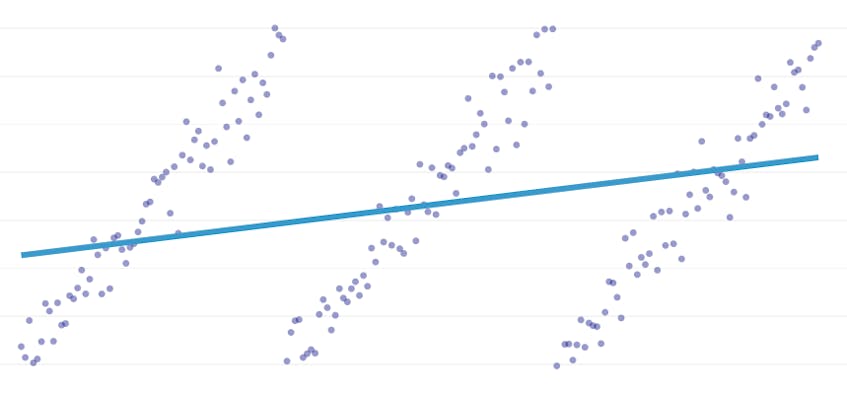
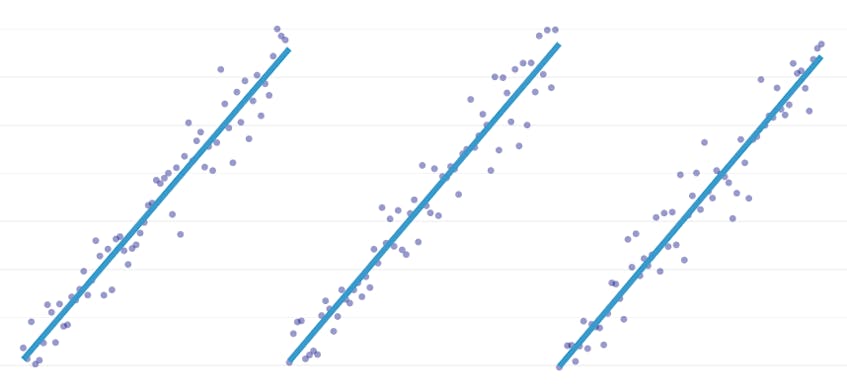
detta inlägg presenterar Datadogs tillvägagångssätt för att automatisera bitvis regression på tidsseriedata.
mål
bitvis regression kan betyda lite olika saker i olika sammanhang, så låt oss ta en minut för att klargöra vad vi exakt försöker uppnå med vår bitvis regressionsalgoritm.
automatiserad brytpunktsdetektering. I klassisk statistiklitteratur föreslås ofta bitvis regression under manuellt regressionsanalysarbete, där det är uppenbart för det blotta ögat där en linjär trend viker för en annan. I så fall kan en människa specificera brytpunkten mellan bitvis segment, dela datauppsättningen och utföra en linjär regression på varje segment oberoende. I våra användningsfall vill vi göra hundratals regressioner per sekund, och det är inte möjligt att få en människa att ange alla brytpunkter. Istället har vi kravet att vår bitvis regressionsalgoritm identifierar sina egna brytpunkter.
Automatisk segmenträkning upptäckt. Om vi skulle veta att en dataset har exakt två segment, kunde vi enkelt titta på var och en av de möjliga segmentparen. Men i praktiken, när det ges en godtycklig tidsserie, finns det ingen anledning att tro att det måste finnas mer än ett segment eller mindre än 3 eller 4 eller 5. Vår algoritm måste välja ett lämpligt antal segment utan att den är användarspecificerad.
inget kontinuitetskrav. Vissa metoder för bitvis regressioner genererar anslutna segment, där varje segments slutpunkt är nästa segments startpunkt. Vi ställer inget sådant krav på vår algoritm.
utmaningar
den mest uppenbara utmaningen att implementera en bitvis regression med automatiserad brytpunktsdetektering är den stora storleken på lösningssökutrymmet; en brute-force-sökning av alla möjliga segment är oöverkomligt dyrt. Antalet sätt en tidsserie kan delas in i segment är exponentiell i tidsseriens längd. Medan dynamisk programmering kan användas för att korsa detta sökutrymme mycket mer effektivt än en naiv brute-force-implementering, är det fortfarande för långsamt i praktiken. En girig heuristisk kommer att behövas för att snabbt kassera stora delar av sökutrymmet.
en mer subtil utmaning är att vi behöver något sätt att jämföra kvaliteten på en lösning till en annan. För vår version av problemet, med okända siffror och platser för segment, måste vi jämföra potentiella lösningar med olika antal segment och olika brytpunkter. Vi försöker balansera två konkurrerande mål:
- minimera felen. Det vill säga, gör varje segments regressionslinje nära de observerade datapunkterna.
- Använd minst antal segment som modellerar databrunnen. Vi kan alltid få nollfel genom att skapa ett enda segment för varje punkt (eller till och med ett segment för varannan punkt). Ändå skulle det besegra hela punkten att göra en regression; vi skulle inte lära oss något om det allmänna förhållandet mellan en tidsstämpel och dess tillhörande metriska värde, och vi kunde inte enkelt använda resultatet för interpolering eller extrapolering.
vår lösning
vi använder följande giriga algoritm för det bitvis regressionsproblemet:
- gör en bitvis regression med N/2-segment, där n är antalet observationer i tidsserien. Regressionslinjen i varje segment passar med vanlig minst kvadrater (OLS) regression. Denna initiala bitvis regression kommer knappast att ha något fel, men det kommer allvarligt att övermontera datamängden.
- iterativt, tills det bara finns ett segment:
- för alla par av angränsande segment, utvärdera ökningen av det totala felet som skulle uppstå om de två segmenten kombinerades, deras två regressionslinjer ersätts av en enda regressionslinje.
- sammanfoga paret av segment som skulle resultera i den minsta ökningen av felet.
- om den här sammanslagningen uppfyller våra stoppkriterier (definierade nedan), kan vi ha gått för långt och sammanfogat två segment som borde förbli separata. Om så är fallet, kom ihåg tillståndet för segmenten från före denna Iterations sammanslagning.
- om ingen sammanslagning resulterade i att komma ihåg tillståndet för segment i (2c) ovan, är den bästa lösningen ett stort segment. Annars är det sista segmenttillståndet att komma ihåg i (2c) den bästa lösningen.
Stoppkriterier
vi anser att en sammanslagning är en potentiell stopppunkt om den ökar den totala summan av kvadratfel med mer än någon tidigare sammanslagning. För att förhindra att stoppa för tidigt i fall där det bara borde finnas ett segment, anser vi inte att en sammanslagning är en potentiell stopppunkt om det inte resulterar i en ökning av det totala felet som är mindre än 3% av det totala felet i en regression med ett segment. (3% är en godtycklig tröskel, men vi har funnit att det fungerar bra i praktiken.) Nedan följer ett par exempel för att visa varför detta stoppkriterium fungerar.
Låt oss först titta på en datamängd som genererades genom att lägga till normalt distribuerat brus till punkter längs en enda rad. Algoritmen passar korrekt bara ett enda segment genom denna datamängd.
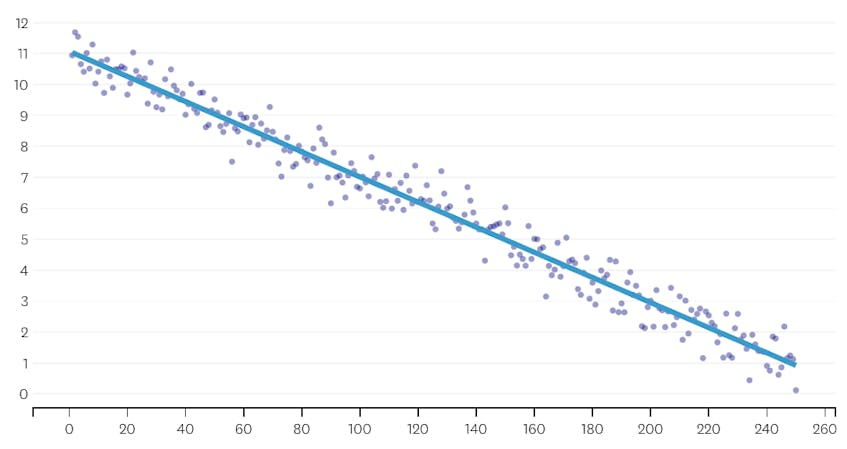
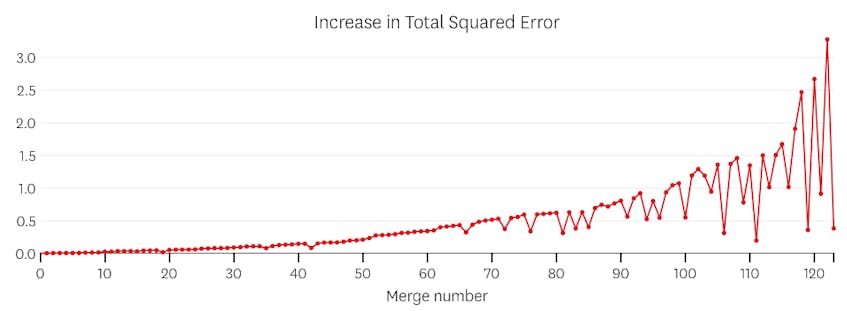
i det här fallet ökar ingen sammanslagning någonsin den totala summan av kvadratfel med mer än 3%. Därför anses ingen sammanslagning vara en lämplig stopppunkt, och vi använder det slutliga tillståndet efter att alla sammanslagningar har utförts. I diagrammet nedan ser vi att senare sammanslagningar tenderar att införa mer fel än tidigare (vilket är meningsfullt eftersom de varje påverkar fler poäng), men ökningen av fel ökar bara gradvis när fler segment slås samman.
för det andra, låt oss titta på ett exempel där det finns sju distinkta segment i datamängden.
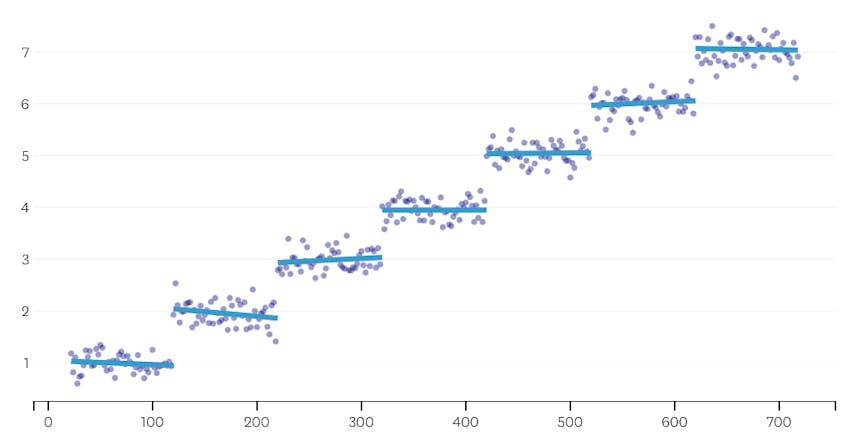
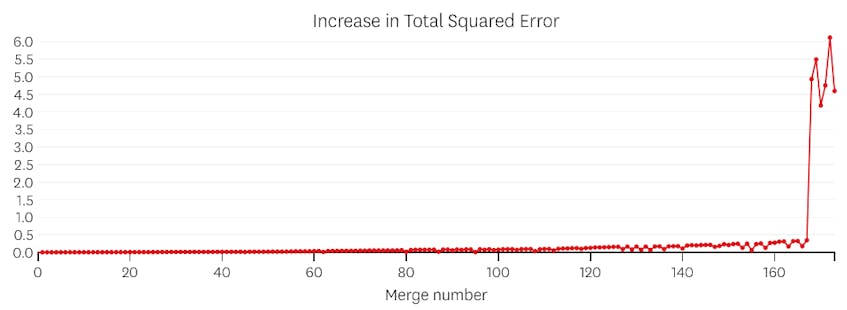
i det här fallet, när vi tittar på diagrammet av fel som införts av varje sammanslagning, ser vi att de senaste sex sammanslagningar infört mycket mer fel än någon av de tidigare sammanslagningar. Därför kom vår algoritm ihåg segmentens tillstånd från före den 6: e till sista sammanslagningen och använde det som den slutliga lösningen.
koden
i Datadog / piecewise Github repo hittar du vår Python-implementering av algoritmen. Funktionen piecewise() är där den tunga lyftningen händer; med tanke på en uppsättning data kommer den att returnera plats-och regressionskoefficienterna för vart och ett av de monterade segmenten.
dessutom ingår i Kontentan är
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)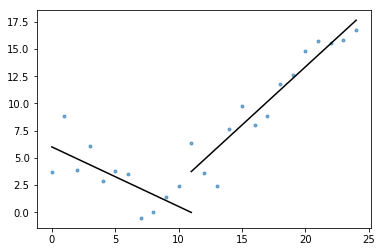
även om denna implementering använder OLS linjär regression, kan samma ramverk anpassas för att lösa relaterade problem. Genom att ersätta kvadratfel med absolut fel eller Huberförlust kan regressionen göras robust. Eller en stegfunktion kan passa genom att tilldela varje segment ett konstant värde lika med genomsnittet av observationerna i dess domän.