dataklassificering är en viktig del av alla informationssäkerhets-och efterlevnadsprogram, särskilt om din organisation lagrar stora datamängder. Det ger en solid grund för din datasäkerhetsstrategi genom att hjälpa dig att förstå var du lagrar känslig och reglerad data, både lokalt och i molnet. Dessutom förbättrar dataklassificering användarnas produktivitet och beslutsfattande och minskar lagrings-och underhållskostnaderna genom att du kan eliminera onödiga data.
i den här artikeln kommer du att lära dig vilka fördelar dataklassificering erbjuder, Hur man implementerar det och hur man väljer rätt mjukvarulösning.
- Nyckeldataklassificering termer och definitioner
- syfte med Dataklassificering
- fördelar med Dataklassificering
- typer av Dataklassificering
- exempel på Dataklassificeringskategorier
- Dataklassificeringsprocess
- hur man väljer en Dataklassificeringslösning
- FAQ
- viktiga Dataklassificeringstermer och definitioner
- syftet med Dataklassificering
- fördelar med Dataklassificering
- datasäkerhet
- regelefterlevnad
- typer av Dataklassificering
- exempel på Dataklassificeringskategorier
- exempel på ett grundläggande klassificeringsschema
- exempel på ett Regeringsklassificeringsschema
- exempel på kommersiell klassificering
- Data Classification Process
- effektiv informationsklassificering i fem steg
- bygga en effektiv Dataklassificeringspolicy
- hur man väljer en dataklassificeringslösning
- FAQ
viktiga Dataklassificeringstermer och definitioner
Dataklassificering är processen att organisera strukturerade och ostrukturerade data i definierade kategorier som representerar olika typer av data. Standardklassificeringar som används i datakategorisering inkluderar:
- Offentlig
- konfidentiell
- känslig
- personlig
känslig data är en allmän term som representerar data som är begränsade till användning av specifika personer eller grupper. Känsliga och konfidentiella uppgifter används ofta omväxlande. Exempel på känsliga uppgifter är immateriella rättigheter och affärshemligheter.
Data omklassificering är omklassificering av data för att tillämpa lämpliga uppdateringar, till exempel baserat på ändringar av juridiska eller avtalsenliga skyldigheter, dataanvändning eller värde eller nya eller reviderade regleringsmandat.
Datamärkning eller märkning lägger till metadata i filer som anger klassificeringsresultaten.
syftet med Dataklassificering
dataklassificering hjälper dig att förstå vilka typer av data du lagrar och var dessa data finns. Denna intelligens:
- informerar riskhantering, juridisk upptäckt och regelefterlevnadsprocesser
- hjälper till att prioritera säkerhetsåtgärder
- förbättrar användarnas produktivitet och beslutsfattande genom att effektivisera sökning och e-upptäckt
- minskar underhålls-och lagringskostnaderna för data genom att identifiera dubbla och inaktuella data
- hjälper IT-team att motivera förfrågningar om investeringar i datasäkerhet.
fördelar med Dataklassificering
mer allmänt hjälper dataklassificering organisationer att förbättra datasäkerheten och säkerställa regelefterlevnad.
datasäkerhet
klassificering är ett effektivt sätt att skydda dina värdefulla data. Genom att identifiera vilka typer av data du lagrar och identifiera var känsliga data finns, är du väl positionerad för att:
- prioritera dina säkerhetsåtgärder, justera dina säkerhetskontroller baserat på datakänslighet
- förstå vem som kan komma åt, ändra eller ta bort data
- bedöma risker, till exempel affärseffekten av ett brott, ransomware-attack eller annat hot
regelefterlevnad
Regelefterlevnadsregler kräver att organisationer skyddar specifika data, till exempel kortinnehavarinformation (PCI DSS) eller personuppgifter för EU-invånare (GDPR). Med dataklassificering kan du identifiera de registrerade som omfattas av särskilda bestämmelser så att du kan tillämpa de nödvändiga kontrollerna och godkänna revisioner.
så här kan dataklassificering hjälpa dig att uppfylla vanliga efterlevnadsstandarder:
- GDPR-dataklassificering hjälper dig att upprätthålla de registrerades rättigheter, inklusive att uppfylla begäran om åtkomst till den registrerade genom att hämta uppsättningen dokument med data om en viss individ.
- HIPAA-att veta var alla patientjournaler lagras hjälper dig att genomföra säkerhetskontroller för korrekt dataskydd.
- ISO 27001 — klassificering av information enligt värde och känslighet hjälper dig att uppfylla kraven för att förhindra obehörigt avslöjande eller modifiering.
- NIST SP 800-53 — kategorisera data hjälper federala myndigheter korrekt arkitekt och hantera sina IT-system.
- PCI DSS-dataklassificering gör att du kan identifiera och säkra konsumenternas finansiella information som används i betalkort

typer av Dataklassificering
- innehållsbaserad klassificering inspekterar och tolkar filer för att identifiera känslig information.
- kontextbaserad klassificering ser på applikation, plats, skapartaggar och andra variabler som indirekta indikatorer på känslig information.
- användarbaserad klassificering beror på Manuellt val av varje dokument av en person.
exempel på Dataklassificeringskategorier
exempel på ett grundläggande klassificeringsschema
det enklaste systemet är Klassificering på tre nivåer:
- offentliga uppgifter-uppgifter som fritt kan lämnas ut till allmänheten. Exempel är ditt företags kontaktinformation och webbläsarens cookiepolicy.
- interna data-Data som har låga säkerhetskrav men inte är avsedda för offentliggörande, som marknadsundersökningar.
- begränsade data — mycket känsliga interna data. Upplysningar kan påverka verksamheten negativt och sätta organisationen på ekonomisk eller juridisk risk. Begränsade data kräver högsta säkerhetsnivå.
exempel på ett Regeringsklassificeringsschema
myndigheter använder ofta tre nivåer av känslighet men ger dem olika etiketter än de som anges ovan: topphemlig, hemlig och offentlig. För mer komplexa datastrukturer kan fler nivåer läggas till. Här är en strategi på fem nivåer med exempel:
- Top secret — Cryptologic and communications intelligence
- Secret — Välj militära planer
- konfidentiell — Data som indikerar styrkan i markstyrkorna
- känslig oklassificerad — Data taggade ”endast för officiellt bruk”
- oklassificerad — Data som får offentliggöras med tillstånd
exempel på kommersiell klassificering
vanligtvis använder organisationer som lagrar och bearbetar kommersiell data fyra nivåer för att klassificera data: tre konfidentiella nivåer och en offentlig nivå. Vissa utökar det till ett system med fem nivåer med följande nivåer:
- Sensitive — Intellectual property, PHI
- Confidential — Vendor contracts, employee reviews
- Private — Customer namn eller bilder
- Proprietary — organisatoriska processer
- Public — Information som kan lämnas ut till någon
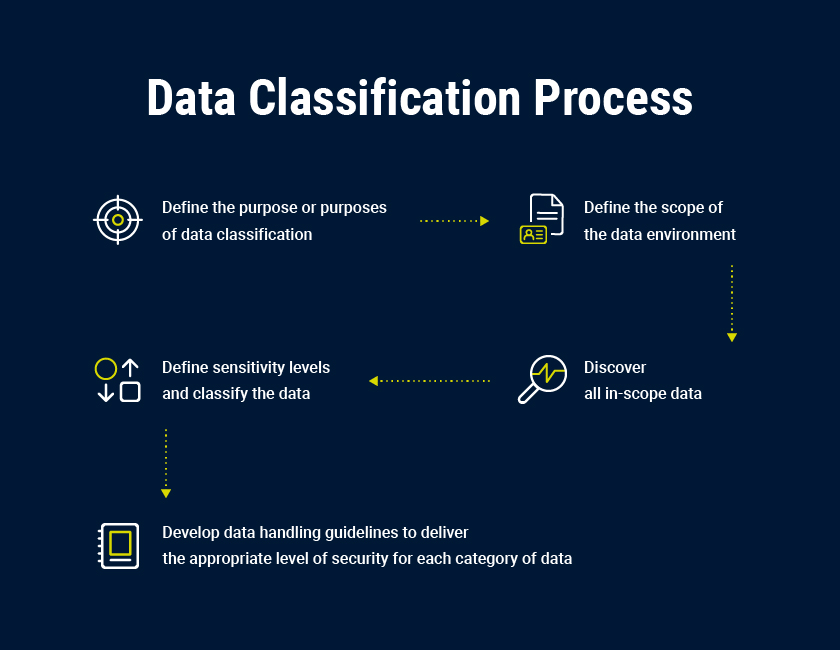
Data Classification Process
effektiv informationsklassificering i fem steg
- upprätta en dataklassificeringspolicy, inklusive mål, arbetsflöden, Dataklassificeringsschema, dataägare och hantering
- identifiera känsliga data du lagrar.
- applicera etiketter genom att märka data.
- använd resultat för att förbättra säkerheten och efterlevnaden.
- Data är dynamiska och klassificering är en pågående process.
bygga en effektiv Dataklassificeringspolicy
en dataklassificeringspolicy är ett dokument som innehåller en klassificeringsram, en lista över ansvarsområden för att identifiera känsliga data och beskrivningar av de olika dataklassificeringsnivåerna.
en bra klassificeringspolicy:
- använder kriterier som är enkla och undviker tvetydighet, men som är generiska nog att gälla för olika datamängder och omständigheter
- är tydlig och skriven på ett enkelt språk
- passar organisationens verksamhet
- är begränsad till 3 eller 4 klassificeringsnivåer
- innehåller en kontaktpunkt för förtydligande
- upprättar en översyn schema
hur man väljer en dataklassificeringslösning
leta efter dessa funktioner:
- sammansatt termsökning-förbättrar noggrannheten genom att minimera falska positiva och falska negativa.
- Index — gör att du kan identifiera känsliga termer utan att genomsöka data igen.
- Flexibel taxonomi manager-gör det enkelt att lägga till och ändra villkor och regler.
- arbetsflöden — tar automatiskt specifika åtgärder när ett dokument klassificeras på ett visst sätt. Ett arbetsflöde kan till exempel flytta känsliga data bort från en offentlig del.
- bredd av täckning — stöder både moln och lokala datakällor, inklusive både strukturerade och ostrukturerade data.
FAQ
vad är syftet med dataklassificering?
dataklassificering sorterar data i kategorier baserat på dess värde och känslighet.
Varför är dataklassificering viktig? Vilka fördelar erbjuder det?
dataklassificering hjälper dig att prioritera dina dataskyddsinsatser för att förbättra datasäkerheten och regelefterlevnaden. Det förbättrar också användarnas produktivitet och beslutsfattande och minskar kostnaderna genom att du kan eliminera onödiga data.
vad är vanliga dataklassificeringsnivåer?
Data klassificeras ofta som offentliga, konfidentiella, känsliga eller personliga.
vilka är dataklassificeringstyperna?
klassificering kan vara innehållsbaserad, kontextbaserad eller användarbaserad (Manuell).
vilken programvara ska jag använda för dataklassificering?
leta efter dataklassificeringsprogramvara, som erbjuds av Netwrix, som:
- använder sammansatt ordsökning för att säkerställa korrekt klassificering som minimerar falska positiva
- har ett index så att du kan hitta känsliga termer utan att genomsöka dina datalager
- innehåller en flexibel taxonomihanterare som ger Dig möjlighet att anpassa dina klassificeringsparametrar
- ger arbetsflöden för att automatisera processer som att migrera känsliga data från offentliga aktier
- stöder både lokala och molninnehållskällor, inklusive både strukturerade och ostrukturerade data
Vem ansvarar för dataklassificering i en organisation?
organisationer utser vanligtvis en säkerhets-och riskhanterare, en Dataskyddschef, Compliance Committee eller en liknande enhet.

VP för produkthantering på Netwrix. Ilia ansvarar för Netwrix produktvision och strategi. Han är en erkänd expert på informationssäkerhet och en officiell medlem av Forbes Technology Council. Ilia har över 15 års erfarenhet av IT-programvara marknaden. I NetWrix-bloggen fokuserar Ilia på cybersäkerhetstrender, strategier och riskbedömning.
