i denna handledning kommer vi att förklara, en av de framväxande och framträdande ord inbäddning teknik som kallas Word2Vec föreslagits av Mikolov et al. under 2013. Vi har samlat in innehållet från olika tutorials och källor för att underlätta läsare på en enda plats. Jag hoppas att det hjälper.
Word2vec är en kombination av modeller som används för att representera distribuerade representationer av ord i en corpus C. Word2Vec (W2V) är en algoritm som accepterar textkorpus som en ingång och matar ut en vektorrepresentation för varje ord, som visas i diagrammet nedan:

det finns två smaker av denna algoritm, nämligen: CBOW och Skip-Gram. Med tanke på en uppsättning meningar (även kallad corpus) slingrar modellen på orden i varje mening och försöker antingen använda det aktuella ordet w för att förutsäga sina grannar (dvs. dess sammanhang) kallas detta tillvägagångssätt ”Skip-Gram”, eller det använder vart och ett av dessa sammanhang för att förutsäga det aktuella ordet w, i så fall kallas metoden ”kontinuerlig säck med ord” (CBOW). För att begränsa antalet ord i varje sammanhang används en parameter som heter ”fönsterstorlek”.

vektorerna vi använder för att representera ord kallas neurala ordinbäddningar, och representationer är konstiga. En sak beskriver en annan, även om dessa två saker är radikalt olika. Som Elvis Costello sa: ”att skriva om musik är som att dansa om arkitektur.”Word2vec” vektoriserar ” om ord, och genom att göra det gör det naturligt språk datorläsbart-vi kan börja utföra kraftfulla matematiska operationer på ord för att upptäcka deras likheter.
så, ett neuralt ordinbäddning representerar ett ord med siffror. Det är en enkel men ändå osannolik översättning. Word2vec liknar en autoencoder som kodar varje ord i en vektor, men snarare än att träna mot ingångsorden genom rekonstruktion, som en begränsad Boltzmann-maskin gör, tränar word2vec ord mot andra ord som grannen dem i ingångskorpus.
det gör det på ett av två sätt, antingen med hjälp av kontext för att förutsäga ett målord (en metod som kallas kontinuerlig säck med ord eller CBOW), eller med hjälp av ett ord för att förutsäga ett målkontext, som kallas skip-gram. Vi använder den senare metoden eftersom den ger mer exakta resultat på stora datamängder.

när funktionsvektorn som tilldelats ett ord inte kan användas för att exakt förutsäga ordets sammanhang justeras vektorns komponenter. Varje ords sammanhang i corpus är läraren som skickar felsignaler tillbaka för att justera funktionsvektorn. Vektorerna av ord som bedöms liknande av deras sammanhang knuffas närmare varandra genom att justera siffrorna i vektorn. I den här handledningen kommer vi att fokusera på Skip-Gram-modellen som i motsats till CBOW betraktar mittord som inmatning som avbildat i figuren ovan och förutsäger kontextord.
modellöversikt
vi förstod att vi måste mata något konstigt neuralt nätverk med några par ord men vi kan inte bara göra det med hjälp av de faktiska tecknen som ingångar, vi måste hitta något sätt att representera dessa ord matematiskt så att nätverket kan bearbeta dem. Ett sätt att göra detta är att skapa ett ordförråd av alla ord i vår text och sedan koda vårt ord som en vektor av samma dimensioner av vårt ordförråd. Varje dimension kan ses som ett ord i vårt ordförråd. Så vi kommer att ha en vektor med alla nollor och en 1 som representerar motsvarande ord i ordförrådet. Denna kodningsteknik kallas en-het kodning. Med tanke på vårt exempel, om vi har en vokabulär gjord av orden ”Den”, ”snabb”, ”brun”, ”räv”, ”hoppar”, ”över”, ”den” ”Lat”, ”hund”, ordet ”brun” representeras av denna vektor: .

Skip-gram-modellen tar in en korpus med text och skapar en hetvektor för varje ord. En het vektor är en vektorrepresentation av ett ord där vektorn är storleken på ordförrådet (totalt unika ord). Alla dimensioner är inställda på 0 utom dimensionen som representerar ordet som används som inmatning vid den tidpunkten. Här är ett exempel på en het vektor:

ovanstående ingång ges till ett neuralt nätverk med ett enda dolt lager.
vi kommer att representera ett inmatningsord som” myror ” som en en-het vektor. Denna vektor kommer att ha 10 000 komponenter (en för varje ord i vårt ordförråd) och vi placerar en ”1” i den position som motsvarar ordet ”myror” och 0s i alla andra positioner. Utsignalen från nätverket är en enda vektor (även med 10 000 komponenter) som för varje ord i vårt ordförråd innehåller sannolikheten för att ett slumpmässigt valt närliggande ord är det ordförrådsordet.
i word2vec används en distribuerad representation av ett ord. Ta en vektor med flera hundra dimensioner (säg 1000). Varje ord representeras av en fördelning av vikter över dessa element. Så istället för en en-till-en-kartläggning mellan ett element i vektorn och ett ord sprids representationen av ett ord över alla element i vektorn, och varje element i vektorn bidrar till definitionen av många ord.
om jag märker dimensionerna i en hypotetisk ordvektor (det finns inga sådana förutbestämda etiketter i algoritmen förstås), det kan se lite ut så här:

en sådan vektor kommer att representera på något abstrakt sätt betydelsen av ett ord. Och som vi kommer att se nästa, helt enkelt genom att undersöka en stor corpus är det möjligt att lära sig ordvektorer som kan fånga relationerna mellan ord på ett överraskande uttrycksfullt sätt. Vi kan också använda vektorerna som ingångar till ett neuralt nätverk. Eftersom våra ingångsvektorer är en-heta, multiplicerar en ingångsvektor med viktmatrisen W1 att helt enkelt välja en rad från W1.
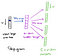

från det dolda lagret till utgångsskiktet kan den andra viktmatrisen W2 användas för att beräkna en poäng för varje ord i ordförrådet, och softmax kan användas för att erhålla den bakre fördelningen av ord. Skip-gram-modellen är motsatsen till CBOW-modellen. Det är konstruerat med fokusordet som den enda ingångsvektorn, och målkontextorden finns nu i utgångsskiktet. Aktiveringsfunktionen för det dolda lagret motsvarar helt enkelt att kopiera motsvarande rad från viktmatrisen W1 (linjär) som vi såg tidigare. Vid utgångsskiktet matar vi nu ut C multinomialfördelningar istället för bara en. Utbildningsmålet är att efterlikna det summerade förutsägelsefelet över alla kontextord i utgångsskiktet. I vårt exempel skulle ingången vara” lärande”, och vi hoppas att se (”an”,” effektiv”,” metod”,” för”,” hög”,” kvalitet”,” distribuerad”,” vektor”) vid utgångsskiktet.
här är arkitekturen i vårt neurala nätverk.

för vårt exempel kommer vi att säga att vi lär oss ordvektorer med 300 funktioner. Så det dolda lagret kommer att representeras av en viktmatris med 10 000 rader (en för varje ord i vårt ordförråd) och 300 kolumner (en för varje dold neuron). 300 funktioner är vad Google använde i sin publicerade modell utbildad på Google news dataset (du kan ladda ner det härifrån). Antalet funktioner är en” hyper parameter ” som du bara skulle behöva ställa in din applikation (det vill säga prova olika värden och se vad som ger de bästa resultaten).
om du tittar på raderna i denna viktmatris är det vad som kommer att bli våra ordvektorer!

så slutmålet med allt detta är egentligen bara att lära sig denna dolda lagerviktmatris – utgångsskiktet vi bara kastar när vi är klara! 1 x 300 ordvektorn för ”myror” matas sedan till utgångsskiktet. Utgångsskiktet är en softmax regressionsklassificerare. Specifikt har varje utgångsneuron en viktvektor som den multiplicerar mot ordvektorn från det dolda lagret, sedan tillämpar den funktionen exp(x) på resultatet. Slutligen, för att få utgångarna att summera upp till 1, delar vi detta resultat med summan av resultaten från alla 10 000 utgångsnoder. Här är en illustration av att beräkna utgången från utgångsneuronen för ordet ”bil”.

om två olika ord har mycket liknande ”sammanhang” (det vill säga vilka ord som sannolikt kommer att visas runt dem), måste vår modell ge mycket liknande resultat för dessa två ord. Och ett sätt för nätverket att mata ut liknande kontextprognoser för dessa två ord är om ordvektorerna är likartade. Så, om två ord har liknande sammanhang, är vårt nätverk motiverat att lära sig liknande ordvektorer för dessa två ord! Ta da!
varje dimension av ingången passerar genom varje nod i det dolda lagret. Dimensionen multipliceras med vikten som leder den till det dolda lagret. Eftersom ingången är en het vektor kommer endast en av ingångsnoderna att ha ett icke-nollvärde (nämligen värdet 1). Det betyder att för ett ord endast vikterna som är associerade med inmatningsnoden med värde 1 kommer att aktiveras, som visas i bilden ovan.
eftersom ingången i detta fall är en het vektor, kommer endast en av ingångsnoderna att ha ett icke-nollvärde. Detta innebär att endast vikterna som är anslutna till den ingångsnoden aktiveras i de dolda noderna. Ett exempel på vikterna som kommer att övervägas visas nedan för det andra ordet i ordförrådet:
vektorrepresentationen av det andra ordet i ordförrådet (visas i det neurala nätverket ovan) kommer att se ut som följer, en gång aktiverad i det dolda lagret:
dessa vikter börjar som slumpmässiga värden. Nätverket tränas sedan för att justera vikterna för att representera inmatningsorden. Det är här utgångsskiktet blir viktigt. Nu när vi befinner oss i det dolda lagret med en vektorrepresentation av ordet behöver vi ett sätt att bestämma hur väl vi har förutsagt att ett ord kommer att passa i ett visst sammanhang. Ordets sammanhang är en uppsättning ord i ett fönster runt det, som visas nedan:

ovanstående bild visar att sammanhanget för fredag innehåller ord som ”katt” och ”är”. Syftet med det neurala nätverket är att förutsäga att ”Fredag” faller inom detta sammanhang.
vi aktiverar utgångsskiktet genom att multiplicera vektorn som vi passerade genom det dolda lagret (vilket var den inmatade heta vektorn * vikter in i dold nod) med en vektorrepresentation av kontextordet (vilket är den heta vektorn för kontextordet * vikter in i utmatningsnoden). Tillståndet för utdatalagret för det första kontextordet kan visualiseras nedan:

ovanstående multiplikation görs för varje ord till kontextordpar. Vi beräknar sedan sannolikheten för att ett ord tillhör en uppsättning kontextord med hjälp av värdena som härrör från de dolda och utmatningslagren. Slutligen tillämpar vi stokastisk gradient nedstigning för att ändra värdena på vikterna för att få ett mer önskvärt värde för den beräknade sannolikheten.
i gradient descent måste vi beräkna gradienten för funktionen som optimeras vid den punkt som representerar vikten som vi ändrar. Lutningen används sedan för att välja i vilken riktning ett steg ska gå mot det lokala optimumet, som visas i minimeringsexemplet nedan.
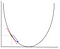
vikten kommer att ändras genom att göra ett steg i riktning mot den optimala punkten (i exemplet ovan, den lägsta punkten i diagrammet). Det nya värdet beräknas genom att subtrahera från det aktuella viktvärdet den härledda funktionen vid punkten för vikten som skalas av inlärningshastigheten. Nästa steg är att använda Backpropagation, för att justera vikterna mellan flera lager. Felet som beräknas i slutet av utgångsskiktet skickas tillbaka från utgångsskiktet till det dolda lagret genom att tillämpa Kedjeregeln. Gradient descent används för att uppdatera vikterna mellan dessa två lager. Felet justeras sedan vid varje lager och skickas tillbaka vidare. Här är ett diagram för att representera backpropagation:

förstå med exempel
Word2vec använder ett enda dolt lager, helt anslutet neuralt nätverk som visas nedan. Neuronerna i det dolda skiktet är alla linjära neuroner. Ingångsskiktet är inställt på att ha så många neuroner som det finns ord i ordförrådet för träning. Den dolda lagerstorleken är inställd på dimensionen för de resulterande ordvektorerna. Storleken på utgångsskiktet är samma som ingångsskiktet. Således, om ordförrådet för att lära sig ordvektorer består av V-ord och N för att vara dimensionen av ordvektorer, kan ingången till dolda lageranslutningar representeras av matris WI av storlek VxN med varje rad som representerar ett ordförrådsord. På samma sätt kan anslutningarna från dolt lager till utgångslager beskrivas med matris WO av storlek NxV. I det här fallet representerar varje kolumn i wo-matrisen ett ord från det givna ordförrådet.

ingången till nätverket kodas med” 1-out of-V ” – representation vilket innebär att endast en ingångslinje är inställd på en och resten av ingångslinjerna är inställda på noll.
låt anta att vi har en träningskorpus med följande meningar:
”hunden såg en katt”, ”hunden jagade katten”, ”katten klättrade ett träd”
korpusordförrådet har åtta ord. En gång ordnat alfabetiskt kan varje ord refereras av dess index. För detta exempel kommer vårt neurala nätverk att ha åtta ingångsneuroner och åtta utgångsneuroner. Låt oss anta att vi bestämmer oss för att använda tre neuroner i det dolda lagret. Detta innebär att WI och WO kommer att vara 8 3 respektive 3 8 8 xnumx xnumx xnumx xnumx xnumx xnumx matriser. Innan träningen börjar initieras dessa matriser till små slumpmässiga värden som vanligt i neuralt nätverksträning. Bara för illustrationens skull, låt oss anta att WI och WO initieras till följande värden:

Antag att vi vill att nätverket ska lära sig förhållandet mellan orden ”katt” och ”klättrade”. Det vill säga nätverket ska visa en stor sannolikhet för ”klättrat” när ”katt” matas in i nätverket. I word inbäddning terminologi, ordet” katt ”kallas sammanhanget ordet och ordet” klättrade ” kallas målet ordet. I detta fall kommer ingångsvektorn X att vara t. Observera att endast den andra komponenten i vektorn är 1. Detta beror på att inmatningsordet är ”katt” som håller nummer två position i sorterad lista över korpusord. Med tanke på att målordet är ”klättrat” kommer målvektorn att se ut som t. med ingångsvektorn som representerar ”katt” kan utgången vid de dolda lagerneuronerna beräknas som:
Ht = XtWI =
det borde inte överraska oss att vektorn H för dolda neuronutgångar efterliknar vikterna i den andra raden av WI-matris på grund av 1-out-of-Vrepresentation. Så funktionen för ingången till dolda lageranslutningar är i grunden att kopiera inmatningsordvektorn till dolt lager. Genom att utföra liknande manipuleringar för dold till utgångslager kan aktiveringsvektorn för utgångslagerneuroner skrivas som
HtWO =
eftersom målet är att producera sannolikheter för ord i utgångsskiktet, Pr(wordk|wordcontext) för k = 1, V, för att återspegla deras nästa ordförhållande med kontextordet vid inmatning behöver vi summan av neuronutgångar i utgångsskiktet för att lägga till en. Word2vec uppnår detta genom att konvertera aktiveringsvärden för utgångslagerneuroner till sannolikheter med softmax-funktionen. Således beräknas utgången från k-TH-neuronen med följande uttryck där aktivering (n) representerar aktiveringsvärdet för n-th-utgångsskiktet neuron:
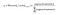
således är sannolikheten för åtta ord i corpus:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
sannolikheten i fetstil är för det valda målordet”klättrat”. Med tanke på målvektorn t beräknas felvektorn för utgångsskiktet enkelt genom att subtrahera sannolikhetsvektorn från målvektorn. När felet är känt kan vikterna i matriserna WO och WI uppdateras med backpropagation. Således kan träningen fortsätta genom att presentera olika kontextmålordpar från corpus. Så här lär Word2vec relationer mellan ord och utvecklar i processen vektorrepresentationer för ord i corpus.
tanken bakom word2vec är att representera ord med en vektor av reella tal av dimension d. Därför är den andra matrisen representationen av dessa ord. Den i: e raden i denna matris är vektorrepresentationen av det i: e ordet. Låt oss säga att i ditt exempel har du 5 ord : , då betyder den första vektorn att du överväger ordet ”häst” och så är representationen av ”häst”. På samma sätt är representationen av ordet ”lejon”.

så vitt jag vet finns det ingen” mänsklig mening ” specifikt för vart och ett av siffrorna i dessa representationer. Ett nummer representerar inte om ordet är ett verb eller inte, ett adjektiv eller inte… det är bara vikterna som du ändrar för att lösa ditt optimeringsproblem för att lära dig representationen av dina ord.
ett visuellt diagram som bäst utarbetar word2vec – matrismultiplikationsprocessen visas i följande figur:

den första matrisen representerar ingångsvektorn i ett hett format. Den andra matrisen representerar de synaptiska vikterna från ingångsskiktets neuroner till de dolda skiktets neuroner. Lägg särskilt märke till det vänstra övre hörnet där Ingångsskiktmatrisen multipliceras med Viktmatrisen. Titta nu längst upp till höger. Denna matrix multiplikation InputLayer dot-producted med vikter transponera är bara ett praktiskt sätt att representera det neurala nätverket längst upp till höger.
den första delen representerar inmatningsordet som en het vektor och den andra matrisen representerar vikten för anslutningen av var och en av ingångsskiktets neuroner till de dolda lagerneuronerna. Som Word2Vec tåg, det backpropagates (med hjälp av gradient nedstigning) i dessa vikter och ändrar dem för att ge bättre representationer av ord som vektorer. När träningen är klar använder du bara denna viktmatris, tar för att säga ’hund’ och multiplicerar den med den förbättrade viktmatrisen för att få vektorrepresentationen av ’hund’ i en dimension = nej av dolda lagerneuroner. I diagrammet är antalet dolda lagerneuroner 3.
i ett nötskal vänder Skip-gram-modellen användningen av mål-och kontextord. I det här fallet matas målordet vid ingången, det dolda lagret förblir detsamma och utgångsskiktet i det neurala nätverket replikeras flera gånger för att rymma det valda antalet kontextord. Med exemplet ”katt” och ”träd” som kontextord och ”klättrade” som målord, skulle ingångsvektorn i skim-gram-modellen vara t, medan de två utgångsskikten skulle ha t respektive t som målvektorer. I stället för att producera en vektor av sannolikheter skulle två sådana vektorer produceras för det aktuella exemplet. Felvektorn för varje utgångsskikt produceras på det sätt som diskuterats ovan. Felvektorerna från alla utgångslager summeras dock för att justera vikterna via backpropagation. Detta säkerställer att viktmatrisen WO för varje utgångslager förblir identisk under hela träningen.
vi behöver några ytterligare ändringar av den grundläggande skip-gram-modellen som är viktiga för att göra det möjligt att träna. Running gradient nedstigning på ett neuralt nätverk som stora kommer att vara långsam. Och för att göra saken värre behöver du en stor mängd träningsdata för att ställa in så många vikter och undvika övermontering. miljoner vikter gånger miljarder träningsprover innebär att träning av denna modell kommer att bli ett djur. För det har författare föreslagit två tekniker som kallas subsampling och negativ provtagning där obetydliga ord tas bort och endast ett specifikt urval av vikter uppdateras.
Mikolov et al. använd också ett enkelt subsampling-tillvägagångssätt för att motverka obalansen mellan sällsynta och frekventa ord i träningsuppsättningen (till exempel ”in”, ”the” Och ”a” ger mindre informationsvärde än sällsynta ord). Varje ord i träningsuppsättningen kasseras med Sannolikhet P (wi) där

f (wi) är frekvensen för ordet wi och t är en vald tröskel, vanligtvis runt 10-5.
implementeringsdetaljer
Word2vec har implementerats på olika språk men här kommer vi att fokusera särskilt på Java dvs., DeepLearning4j, darks-lärande och python . Olika neurala nätalgoritmer har implementerats i DL4j, kod finns tillgänglig på GitHub.
för att implementera det i DL4j kommer vi att gå igenom några steg som anges enligt följande:
a) Word2Vec Setup
skapa ett nytt projekt i IntelliJ med Maven. Ange sedan Egenskaper och beroenden i POM.xml-fil i projektets rotkatalog.
b) ladda data
skapa nu och namnge en ny klass i Java. Därefter tar du de råa meningarna i din .txt-fil, korsa dem med din iterator och utsätta dem för någon form av förbehandling, som att konvertera alla ord till små bokstäver.
String filePath = nya ClassPathResource (”raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info (”ladda & vektorisera meningar….”);
// Strip white space före och efter för varje rad
SentenceIterator iter = new BasicLineIterator (filePath);
om du vill ladda en textfil förutom meningarna i vårt exempel, skulle du göra det här:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Tokenizing Data
Word2vec måste matas ord snarare än hela meningar, så nästa steg är att tokenize data. Att tokenisera en text är att bryta upp den i sina atomenheter, skapa en ny token varje gång du träffar ett vitt utrymme, till exempel.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) träna modellen
nu när data är klara kan du konfigurera Word2vec neurala nät och mata in tokens.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
denna konfiguration accepterar flera hyperparametrar. Några kräver lite förklaring:
- batchSize är mängden ord du bearbetar åt gången.
- minWordFrequency är det minsta antalet gånger ett ord måste visas i corpus. Här, om det verkar mindre än 5 gånger, är det inte lärt sig. Ord måste visas i flera sammanhang för att lära sig användbara funktioner om dem. I mycket stora corpora är det rimligt att höja minimumet.
- useAdaGrad — Adagrad skapar en annan lutning för varje funktion. Här är vi inte bekymrade över det.
- layerSize anger antalet funktioner i ordvektorn. Detta är lika med antalet dimensioner i funktionernautrymme. Ord som representeras av 500 funktioner blir poäng i ett 500-dimensionellt utrymme.
- learningRate är stegstorleken för varje uppdatering av koefficienterna, eftersom ord omplaceras i funktionsutrymmet.
- minLearningRate är golvet på inlärningshastigheten. Inlärningshastigheten förfaller när antalet ord du tränar på minskar. Om inlärningsgraden krymper för mycket är nätets lärande inte längre effektivt. Detta håller koefficienterna rörliga.
- iterate berättar för nätet vilken sats av dataset det tränar på.
- tokenizer matar det orden från den aktuella batchen.
- vec.fit () talar om för det konfigurerade nätet att börja träna.
e) utvärdera modellen med Word2vec
nästa steg är att utvärdera kvaliteten på dina funktionsvektorer.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
linjen vec.similarity("word1","word2") returnerar cosinuslikheten för de två orden du anger. Ju närmare det är 1, desto mer likartat uppfattar nätet dessa ord att vara (Se Sverige-Norge-exemplet ovan). Exempelvis:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
med vec.wordsNearest("word1", numWordsNearest) låter orden som skrivs ut på skärmen dig ögongloben om nätet har klustrat semantiskt liknande ord. Du kan ställa in antalet närmaste ord du vill ha med den andra parametern i wordsNearest. Till exempel:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec i Java i http://deeplearning4j.org/word2vec.html
7) Word2Vec och Doc2Vec i Python i genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html