icke-enhetlig minnesåtkomst (numa) är en delad minnesarkitektur som används i dagens multiprocessorsystem. Varje CPU tilldelas sitt eget lokala minne och kan komma åt minne från andra processorer i systemet. Lokal minnesåtkomst ger en låg latens – hög bandbredd prestanda. Medan åtkomst till minne som ägs av den andra CPU har högre latens och lägre bandbredd prestanda. Moderna applikationer och operativsystem som ESXi stöder NUMA som standard, men för att ge bästa prestanda, bör virtuell maskinkonfiguration göras med NUMA-arkitekturen i åtanke. Om felaktigt utformat, inkonsekvent beteende eller övergripande prestandaförsämring inträffar för den specifika virtuella maskinen eller i värsta fall för alla virtuella datorer som körs på den ESXi-värden.
denna serie syftar till att ge insikter i CPU-arkitekturen, minnesundersystemet och ESXi CPU och memory scheduler. Låter dig skapa en högpresterande plattform som lägger grunden för de högre tjänsterna och ökade konsolideringsförhållanden. Innan vi anländer till moderna beräkningsarkitekturer är det bra att granska historiken för multiprocessorarkitekturer med delat minne för att förstå varför vi använder NUMA-system idag.
- utvecklingen av multiprocessorarkitektur med delat minne under de senaste decennierna
- introduktion av caching snoop protokoll
- enhetlig Minnesåtkomstarkitektur
- icke-enhetlig Minnesåtkomstarkitektur
- 1: icke-enhetlig Minnesåtkomstorganisation
- 2: punkt-till-punkt-sammankoppling
- 3: skalbar Cache-koherens
- icke-Interfolierad aktiverad NUMA = SUMA
- Nehalem & Core microarchitecture översikt
utvecklingen av multiprocessorarkitektur med delat minne under de senaste decennierna
det verkar som om en arkitektur som kallas enhetlig minnesåtkomst skulle passa bättre när man utformar en konsekvent plattform med låg latens och hög bandbredd. Ändå kommer moderna systemarkitekturer att begränsa det från att vara riktigt enhetligt. För att förstå orsaken bakom detta måste vi gå tillbaka i historien för att identifiera de viktigaste drivkrafterna för parallell databehandling.
med introduktionen av relationsdatabaser i början av sjuttiotalet blev behovet av system som kunde betjäna flera samtidiga användaroperationer och överdriven datagenerering mainstream. Trots den imponerande hastigheten på uniprocessorprestanda var multiprocessorsystem bättre utrustade för att hantera denna arbetsbelastning. För att tillhandahålla ett kostnadseffektivt system blev delat minnesadressutrymme fokus för forskning. Tidigt förespråkades system med en tvärstångsbrytare, men med denna designkomplexitet skalad tillsammans med ökningen av processorer, vilket gjorde det bussbaserade systemet mer attraktivt. Processorer i ett bussystem får tillgång till hela minnesutrymmet genom att skicka förfrågningar på bussen, ett mycket kostnadseffektivt sätt att använda det tillgängliga minnet så optimalt som möjligt.
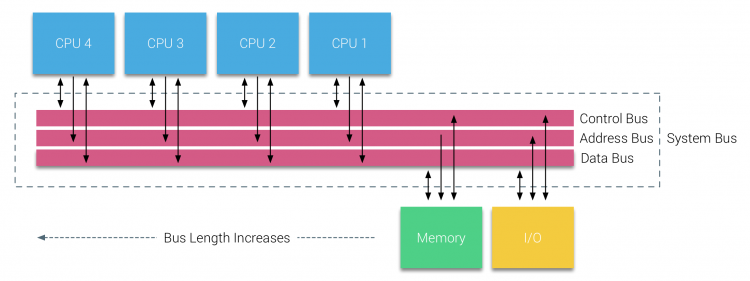
bussbaserade system har dock sina egna skalbarhetsproblem. Huvudproblemet är den begränsade mängden bandbredd, detta begränsar antalet processorer som bussen kan rymma. Att lägga till processorer i systemet introducerar två stora problemområden:
- den tillgängliga bandbredden per nod minskar när varje CPU läggs till.
- busslängden ökar när man lägger till fler processorer, vilket ökar latensen.
CPU: s prestandatillväxt och specifikt hastighetsgapet mellan processorn och minnesprestandan var och är faktiskt fortfarande förödande för multiprocessorer. Eftersom minnesgapet mellan processor och minne förväntades öka, gick mycket arbete på att utveckla effektiva strategier för att hantera minnessystemen. En av dessa strategier var att lägga till minnescache, vilket introducerade en mängd utmaningar. Att lösa dessa utmaningar är fortfarande dagens huvudfokus för CPU-designteam, mycket forskning görs på cachningsstrukturer och sofistikerade algoritmer för att undvika cache-missar.
introduktion av caching snoop protokoll
att fästa en cache till varje CPU ökar prestanda på många sätt. Att föra minnet närmare CPU minskar den genomsnittliga minnesåtkomsttiden och minskar samtidigt bandbreddsbelastningen på minnesbussen. Utmaningen med att lägga till cache till varje CPU i en delad minnesarkitektur är att det tillåter flera kopior av ett minnesblock att existera. Detta kallas cache-koherensproblemet. För att lösa detta uppfanns caching snoop-protokoll som försökte skapa en modell som gav rätt data medan de inte försökte äta upp all bandbredd på bussen. Det mest populära protokollet, write invalidate, raderar alla andra kopior av data innan du skriver den lokala cachen. Varje efterföljande läsning av dessa data av andra processorer kommer att upptäcka en cache-miss i deras lokala cache och kommer att servas från cachen på en annan CPU som innehåller de senast modifierade data. Denna modell sparade mycket bussbandbredd och möjliggjorde enhetliga Minnesåtkomstsystem att dyka upp i början av 1990-talet. moderna cache-koherensprotokoll behandlas mer detaljerat av del 3.
enhetlig Minnesåtkomstarkitektur
processorer av Bussbaserade multiprocessorer som upplever samma enhetliga åtkomsttid till vilken minnesmodul som helst i systemet kallas ofta enhetliga Minnesåtkomstsystem (UMA) eller symmetriska Multiprocessorer (SMPS).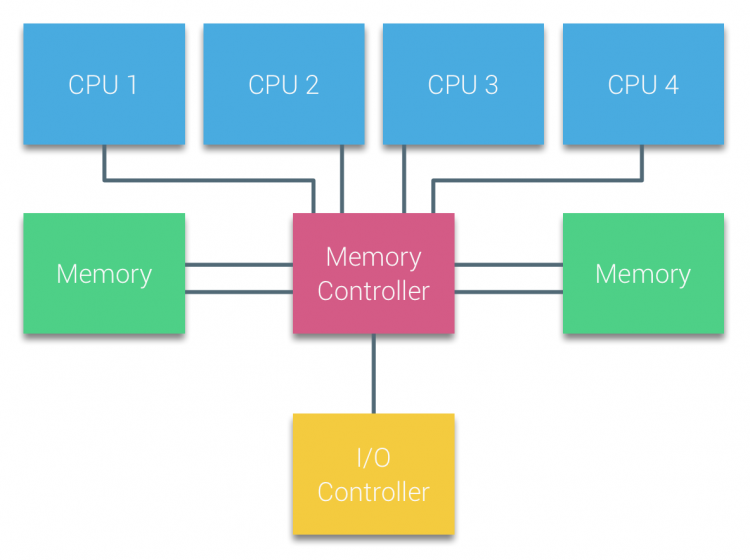
med UMA-system är CPU: erna anslutna via en systembuss (Front-Side Bus) till Northbridge. Northbridge innehåller minneskontrollern och all kommunikation till och från minnet måste passera genom Northbridge. I / O-styrenheten, som ansvarar för att hantera i/O till alla enheter, är ansluten till Northbridge. Därför måste varje I / O gå igenom Northbridge för att nå CPU.
flera bussar och minneskanaler används för att fördubbla den tillgängliga bandbredden och minska flaskhalsen i Northbridge. För att öka minnesbandbredden ytterligare kopplade vissa system externa minneskontroller till Northbridge, vilket förbättrade bandbredd och stöd för mer Minne. Men på grund av den interna bandbredden i Northbridge och sändningskaraktären för tidiga snoopy-cacheprotokoll ansågs UMA ha en begränsad skalbarhet. Med dagens användning av höghastighets flash-enheter, som drev hundratusentals iOS per sekund, hade de helt rätt att denna arkitektur inte skulle skala för framtida arbetsbelastningar.
icke-enhetlig Minnesåtkomstarkitektur
för att förbättra skalbarhet och prestanda görs tre kritiska ändringar i multiprocessorarkitekturen med delat minne;
- icke-enhetlig Minnesåtkomstorganisation
- punkt-till-punkt-sammankopplingstopologi
- skalbara cache-koherenslösningar
1: icke-enhetlig Minnesåtkomstorganisation
NUMA rör sig bort från en centraliserad pool av minne och introducerar topologiska egenskaper. Genom att klassificera minnesplatsbaser på signalbanans längd från processorn till minnet kan latens och bandbreddsflaskhalsar undvikas. Detta görs genom att omforma hela systemet med processor och chipset. Numa-arkitekturer blev populära i slutet av 90-talet när den användes på SGI-superdatorer som Cray Origin 2000. NUMA hjälpte till att identifiera platsen för minnet, i det här fallet med dessa system var de tvungna att undra vilken minnesregion i vilket chassi som höll minnesbitarna.
under första hälften av årtusendet tog AMD NUMA till företagslandskapet där UMA systems regerade högsta. 2003 introducerades AMD Opteron-familjen med integrerade minneskontroller där varje CPU äger utsedda minnesbanker. Varje CPU har nu sitt eget minnesadressutrymme. Ett NUMA-optimerat operativsystem som ESXi tillåter arbetsbelastning att konsumera minne från båda minnesadresserna samtidigt som man optimerar för lokal minnesåtkomst. Låt oss använda ett exempel på ett två CPU-system för att klargöra skillnaden mellan lokal och fjärrminneåtkomst inom ett enda system.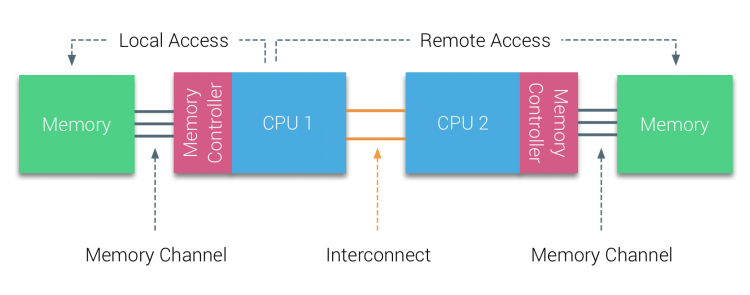
minnet som är anslutet till minneskontrollern för CPU1 anses vara lokalt minne. Minne anslutet till ett annat CPU-uttag (CPU2)anses vara främmande eller fjärrkontroll för CPU1. Fjärrminneåtkomst har ytterligare latens över huvudet till lokal minnesåtkomst, eftersom den måste korsa en sammankoppling (punkt-till-punkt-länk) och ansluta till fjärrminneskontrollern. Som ett resultat av de olika minnesplatserna upplever detta system ”ojämn” minnesåtkomsttid.
2: punkt-till-punkt-sammankoppling
AMD introducerade sin punkt-till-punkt-anslutning HyperTransport med AMD Opteron-mikroarkitekturen. Intel flyttade bort från sin dubbla oberoende bussarkitektur 2007 genom att introducera QuickPath-arkitekturen i deras Nehalem-Processorfamiljdesign.
Nehalem-arkitekturen var en betydande designförändring inom Intel-mikroarkitekturen och anses vara den första riktiga generationen av Intel Core-serien. Den nuvarande Broadwell-arkitekturen är den 4: e generationen av Intel Core-märket (Intel Xeon E5 v4), det sista stycket innehåller mer information om mikroarkitekturgenerationerna. Inom QuickPath-arkitekturen flyttade minneskontrollerna till CPU och introducerade QuickPath point-to-point Interconnect (QPI) som datalänkar mellan processorer i systemet.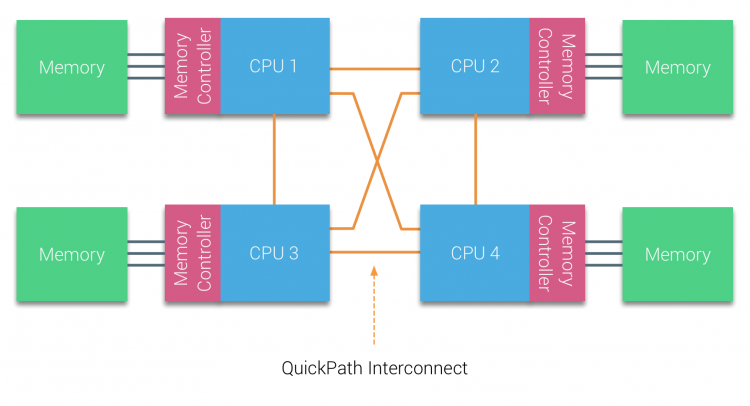
Nehalem-mikroarkitekturen ersatte inte bara den äldre frontbussen utan omorganiserade hela delsystemet till en modulär design för server-CPU. Denna modulära design introducerades som” Uncore ” och skapar ett byggblockbibliotek för cachning och sammankopplingshastigheter. Att ta bort frontbussen förbättrar problem med bandbredd skalbarhet, men intra-och interprocessorkommunikation måste lösas när man hanterar enorma mängder minneskapacitet och bandbredd. Både den integrerade minneskontrollern och QuickPath-sammankopplingarna är en del av Uncore och är modellspecifika register (MSR) ). De ansluter till en MSR som tillhandahåller intra – och interprocessorkommunikation. Modulariteten hos Uncore gör det också möjligt för Intel att erbjuda olika QPI-hastigheter, vid skrivandet av Intel Broadwell-EP-mikroarkitekturen (2016) erbjuder 6, 4 Giga-överföringar per sekund (GT/s), 8, 0 GT/s och 9, 6 GT/s. respektive ger en teoretisk maximal bandbredd på 25, 6 GB/s, 32 GB/s och 38, 4 GB/s mellan CPU: erna. För att sätta detta i perspektiv gav den senast använda frontbussen 1,6 GT/s eller 12,8 GB/s plattformsbandbredd. Vid införandet Sandy Bridge Intel skyltas Uncore i System Agent, men termen Uncore används fortfarande i aktuell dokumentation. Du kan hitta mer om QuickPath och Uncore i del 2.
3: skalbar Cache-koherens
varje kärna hade en privat sökväg till L3-cachen. Varje väg bestod av tusen ledningar och du kan föreställa dig att detta inte skalar bra om du vill minska nanometertillverkningsprocessen samtidigt som du ökar kärnorna som vill komma åt cachen. För att kunna skala flyttade Sandy Bridge-arkitekturen L3-cachen ur Uncore och introducerade den skalbara ring on-die Interconnect. Detta gjorde det möjligt för Intel att partitionera och distribuera L3-cachen i lika skivor. Detta ger högre bandbredd och associativitet. Varje skiva är 2,5 MB och en skiva är associerad med varje kärna. Ringen tillåter varje kärna att komma åt alla andra skivor också. Bilden nedan är formkonfigurationen för en låg kärnantal (LCC) Xeon CPU av Broadwell Microarchitecture (v4) (2016).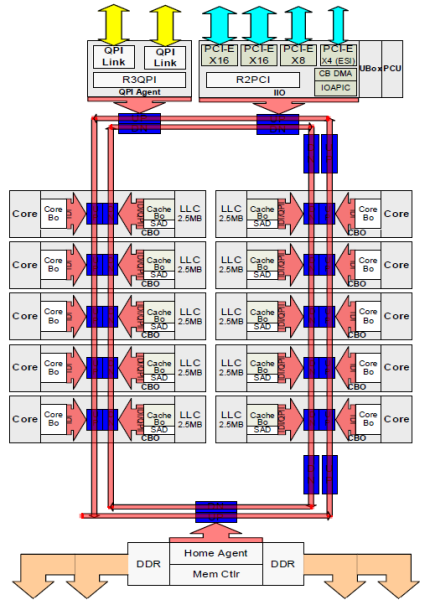
denna cachningsarkitektur kräver ett snooping-protokoll som innehåller både distribuerad lokal cache och de andra processorerna i systemet för att säkerställa cachekoherens. Med tillägg av fler kärnor i systemet växer mängden snoop-trafik, eftersom varje kärna har sin egen stadiga ström av cache-missar. Detta påverkar konsumtionen av QPI länkar och sista nivån cachar, kräver pågående utveckling i snoop koherens protokoll. En fördjupad bild av Uncore, skalbar ring on-Die Interconnect och vikten av caching snoop protokoll på NUMA prestanda kommer att ingå i del 3.
icke-Interfolierad aktiverad NUMA = SUMA
fysiskt minne distribueras över moderkortet, men systemet kan tillhandahålla ett enda minnesadressutrymme genom att interfoliera minnet mellan de två NUMA-noderna. Detta kallas nod-interleaving (inställningen är täckt i del 2). När nodinterfoliering är aktiverad blir systemet en tillräckligt enhetlig minnesarkitektur (SUMA). Istället för att vidarebefordra topologiinformationen och naturen hos processorerna och minnet i systemet till operativsystemet, bryter systemet ner hela minnesområdet i 4KB adresserbara regioner och kartlägger dem på ett round robin-sätt från varje nod. Detta ger en’ Interfolierad ’ minnesstruktur där minnesadressutrymmet fördelas över noderna. När ESXi tilldelar minne till virtuell maskin allokerar det fysiskt minne som finns från två olika noder när den fysiska CPU som finns i Nod 0 behöver hämta minnet från nod 1, kommer minnet att korsa QPI-länkarna.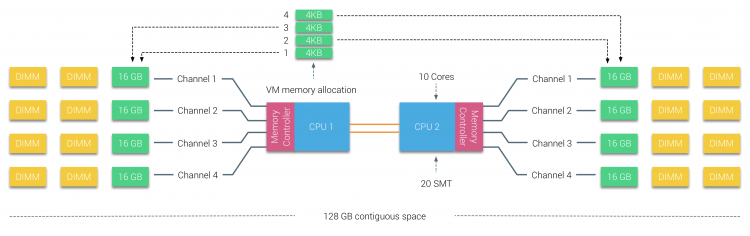
det intressanta är att SUMA-systemet ger en enhetlig minnesåtkomsttid. Bara inte den mest optimala och beror starkt på stridsnivåer i QPI-arkitekturen. Intel Memory Latency Checker användes för att visa skillnaderna mellan numa och SUMA konfiguration på samma system.
detta test mäter tomgångs latenserna (i nanosekunder) från varje uttag till det andra uttaget i systemet. Latensen som rapporteras av Minnesnod 0 av Socket 0 är lokal minnesåtkomst, minnesåtkomst från socket 0 av minnesnod 1 är fjärrminneåtkomst i systemet konfigurerat som NUMA.
| numa | Minnesnod 0 | Minnesnod 1 | – | SUMA | Minnesnod 0 | Minnesnod 1 |
| Socket 0 | 75.7 | 132.0 | – | uttag 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
som förväntat påverkas interfoliering av konstant genomkorsning av QPI-länkarna. Idle memory-testet är det bästa fallet, ett mer intressant test mäter laddade latenser. Det skulle ha varit en dålig investering om dina ESXi-servrar går på tomgång, därför kan du anta att ett ESXi-system behandlar data. Mätning av laddade latenser ger en bättre inblick i hur systemet kommer att fungera under normal belastning. Under testet ändras belastningsinjektionsfördröjningarna automatiskt var 2: e sekund och både bandbredd och motsvarande latens mäts på den nivån. Detta test använder 100% Läs trafik.NUMA testresultat till vänster, SUMA testresultat till höger.
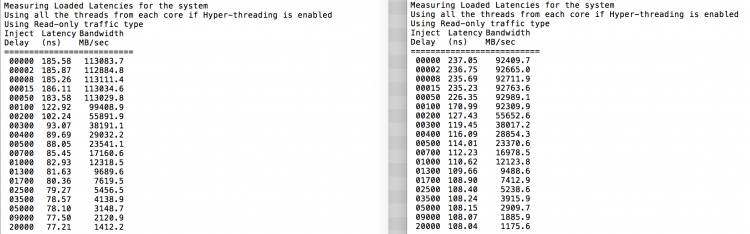
den rapporterade bandbredden för SUMA-systemet är lägre samtidigt som en högre latens bibehålls än systemet konfigurerat som NUMA. Därför bör fokus ligga på att optimera VM-storleken för att utnyttja systemets NUMA-egenskaper.
Nehalem & Core microarchitecture översikt
med introduktionen av Nehalem microarchitecture 2008 flyttade Intel bort från Netburst-arkitekturen. Nehalem-mikroarkitekturen introducerade Intel-kunder till NUMA. Under åren introducerade Intel nya mikroarkitekturer och optimeringar, enligt sin berömda Tick-Tock-modell. Med varje Tick sker optimering, krymper processtekniken och med varje Tock introduceras en ny mikroarkitektur. Även om Intel ger en konsekvent branding modell sedan 2012, människor tenderar att Intel arkitektur kodnamn för att diskutera CPU tick och tock generationer. Även EVC-baslinjerna listar dessa interna Intel-kodnamn, både varumärkesnamn och arkitekturkodnamn kommer att användas i hela serien:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22 nm |
| Broadwell | E5 – 26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xddr3-2400 | kryssa | 14 nm |
upp nästa, del 2: systemarkitektur
2016 numa Deep Dive Series:
Del 0: introduktion numa Deep Dive Series
Del 1: från UMA till NUMA
del 2: systemarkitektur
del 3: Cache Coherency
Del 4: lokal minnesoptimering
Del 5: ESXi VMkernel NUMA konstruerar