In this tutorial we are going to explain, one of the emerging and prominent word embedding technique called Word2Vec proposed by Mikolov et al. em 2013. Coletamos esses conteúdos de diferentes tutoriais e fontes para facilitar os leitores em um único lugar. Espero que ajude.
Word2vec é uma combinação dos modelos utilizados para representar distribuído representações de palavras em um corpus C. Word2Vec (W2V) é um algoritmo que aceita texto corpus como entrada e gera como saída uma representação vetorial para cada palavra, como mostrado no diagrama abaixo:

Existem duas variantes deste algoritmo a saber: CBOW e Ignorar-Grama. Dado um conjunto de frases (também chamado de corpus) o modelo de loops nas palavras de cada frase, e tenta usar a palavra w, a fim de prever os seus vizinhos (por exemplo, de seu contexto), essa abordagem é chamada de “Ignorar o-Gram”, ou ele usa cada um destes contextos para prever a palavra w, nesse caso, o método é chamado de “Contínuo” Saco De Palavras” (CBOW). Para limitar o número de Palavras em cada contexto, um parâmetro chamado “tamanho da janela” é usado.

Os vetores que usamos para representar palavras são chamadas neural palavra incorporações e representações são estranhas. Uma coisa descreve outra, embora essas duas coisas sejam radicalmente diferentes. Como Elvis Costello disse: “escrever sobre música é como dançar sobre arquitetura.”Word2vec” vetoriza ” sobre palavras, e ao fazê-lo torna a linguagem natural legível por computador — podemos começar a executar poderosas operações matemáticas em palavras para detectar suas semelhanças.
assim, uma incorporação de palavras neurais representa uma palavra com números. É uma tradução simples, mas improvável. Word2vec é semelhante a um autoencoder, codificando cada palavra em um vetor, mas em vez de treinar contra as palavras de entrada através da reconstrução, como uma máquina Boltzmann Restrito faz, word2vec treina palavras contra outras palavras que os vizinhos no corpo de entrada.
ele faz isso de uma de duas maneiras, ou usando o contexto para prever uma palavra-alvo (um método conhecido como Saco contínuo de palavras, ou CBOW), ou usando uma palavra para prever um contexto-alvo, que é chamado skip-gram. Usamos este último método porque produz resultados mais precisos em grandes conjuntos de dados.

Quando o vetor característico atribuído a uma palavra não pode ser usada para prever com precisão o que a palavra contexto, as componentes do vetor são ajustados. O contexto de cada palavra no corpo é o professor enviando sinais de erro de volta para ajustar o vetor de recursos. Os vetores de palavras julgadas similares por seu contexto são aproximadas ajustando os números no vetor. Neste tutorial, vamos focar no modelo Skip-Gram que, em contraste com CBOW, considera a palavra central como entrada como representada na figura acima e prevê palavras de contexto.
visão geral do Modelo
entendemos que temos para alimentar algum estranho rede neural com alguns pares de palavras, mas não podemos fazer isso utilizando como entradas de personagens reais, temos que encontrar alguma maneira de representar estas palavras, matematicamente, de modo que a rede possa processá-los. Uma maneira de fazer isso é criar um vocabulário de todas as palavras em nosso texto e então codificar nossa palavra como um vetor das mesmas dimensões de nosso vocabulário. Cada dimensão pode ser pensada como uma palavra no nosso vocabulário. Então teremos um vetor com todos os zeros e um 1 que representa a palavra correspondente no vocabulário. Esta técnica de codificação é chamada de codificação one-hot. Considerando o nosso exemplo, se tivermos um vocabulário feito das palavras “the”, “quick”,” brown”,” fox”,” jumps”,” over”,” the “lazy”, “dog”, a palavra “brown” é representada por este vetor: .

o modelo Skip-gram toma um corpo de texto e cria um vetor-quente para cada palavra. Um vetor quente é uma representação vetorial de uma palavra onde o vetor é o tamanho do vocabulário (palavras únicas totais). Todas as dimensões são ajustadas para 0, exceto a dimensão que representa a palavra que é usada como uma entrada nesse ponto no tempo. Aqui está um exemplo de um vetor quente:

acima de entrada é dada para uma rede neural com uma única camada oculta.
nós vamos representar uma palavra de entrada como” formigas ” como um vetor Um-quente. Este vetor terá 10.000 Componentes (um para cada palavra em nosso vocabulário) e colocaremos um “1” na posição correspondente à palavra “formigas”, e 0s em todas as outras posições. A saída da rede é um único vetor (também com 10 mil componentes) contendo, para cada palavra em nosso vocabulário, a probabilidade de que uma palavra próxima selecionada aleatoriamente é essa palavra de vocabulário.
em word2vec, uma representação distribuída de uma palavra é usada. Tome um vetor com várias centenas de dimensões (digamos 1000). Cada palavra é representada por uma distribuição de pesos através desses elementos. Assim, em vez de um-para-um mapeamento entre um elemento no vetor e uma palavra, a representação de uma palavra é transmitida através de todos os elementos no vetor, e cada elemento no vetor contribui para a definição de muitas palavras.
Se eu rótulo as dimensões de uma hipotética palavra de vetor (não há nenhum pré-atribuídos rótulos no algoritmo de curso), pode parecer um pouco como este:

Tal vetor vem para representar de alguma forma abstrata o ‘significado’ de uma palavra. E como veremos a seguir, simplesmente examinando um corpo grande é possível aprender vetores de palavras que são capazes de capturar as relações entre palavras de uma forma surpreendentemente expressiva. Também podemos usar os vetores como entradas para uma rede neural. Uma vez que nossos vetores de entrada são um-quente, multiplicar um vetor de entrada pela matriz de peso W1 equivale a simplesmente selecionar uma linha de W1.
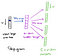

a Partir da camada oculta para a camada de saída, o segundo peso matriz W2 pode ser usado para computar uma pontuação para cada palavra no vocabulário, e softmax pode ser usado para obter a distribuição a posteriori de palavras. O modelo skip-gram é o oposto do modelo CBOW. Ele é construído com a palavra foco como o vetor de entrada única, e as palavras de contexto alvo estão agora na camada de saída. A função de ativação para a camada oculta simplesmente equivale a copiar a linha correspondente da matriz de pesos W1 (linear) como vimos antes. Na camada de saída, nós agora output C distribuições multinomiais em vez de apenas uma. O objetivo do treinamento é imitar o erro de predição somado em todas as palavras de contexto na camada de saída. No nosso exemplo, a entrada seria “aprendizagem”, e esperamos ver (“um”, “eficiente”, “método”, “para”, “alto”, “qualidade”, “distribuído”, “vetor”) na camada de saída.Aqui está a arquitetura da nossa rede neural.

por exemplo, vamos dizer que estamos aprendendo vetores de palavras com 300 características. Assim, a camada oculta será representada por uma matriz de peso com 10.000 linhas (uma para cada palavra em nosso vocabulário) e 300 colunas (uma para cada neurônio escondido). 300 recursos é o que o Google usou em seu modelo publicado treinado no Google news dataset (você pode baixá-lo a partir daqui). O número de recursos é um “parâmetro hyper” que você teria que sintonizar para a sua aplicação (ou seja, experimentar valores diferentes e ver o que produz os melhores resultados).
se você olhar para as linhas desta matriz de peso, estes são os nossos vetores de palavra!

Assim o objetivo final de tudo isso é realmente só para aprender esta camada oculta peso matriz — a camada de saída vamos lançar quando estiver pronto! O vetor de 1 x 300 palavras para” formigas ” então é alimentado para a camada de saída. A camada de saída é um classificador de regressão softmax. Especificamente, cada neurônio de saída tem um vetor de peso que se multiplica contra o vetor de palavra a partir da camada oculta, então ele aplica a função exp(x) ao resultado. Finalmente, a fim de obter as saídas para somar até 1, Nós dividimos este resultado pela soma dos resultados de todos os 10.000 nós de saída. Aqui está uma ilustração de calcular a saída do neurônio de saída para a palavra “carro”.

Se duas palavras muito semelhantes “contextos” (isto é, que as palavras são susceptíveis de aparecer em torno deles), então o nosso modelo precisa de saída de resultados muito semelhantes para estas duas palavras. E uma maneira para a rede produzir previsões de contexto semelhantes para estas duas palavras é se os vetores de palavra são semelhantes. Então, se duas palavras têm contextos semelhantes, então nossa rede é motivada a aprender vetores de palavras semelhantes para estas duas palavras! Ta da!
cada dimensão da entrada passa por cada nó da camada oculta. A dimensão é multiplicada pelo peso que a leva à camada oculta. Como a entrada é um vetor quente, apenas um dos nós de entrada terá um valor não-zero (ou seja, o valor de 1). Isto significa que, para uma palavra, apenas os pesos associados com o nó de entrada com o valor 1 serão ativados, como mostrado na imagem acima.
como a entrada neste caso é um vetor quente, apenas um dos nós de entrada terá um valor não-zero. Isto significa que apenas os pesos ligados a esse nó de entrada serão ativados nos nós ocultos. Um exemplo dos pesos que serão considerados é descrito a seguir para a segunda palavra no vocabulário:
A representação vetorial da segunda palavra no vocabulário (mostrado na rede neural acima) vai olhar como segue, uma vez ativado na camada oculta:
Os pesos começar como valores aleatórios. A rede é então treinada a fim de ajustar os pesos para representar as palavras de entrada. É aqui que a camada de saída se torna importante. Agora que estamos na camada oculta com uma representação vetorial da palavra, precisamos de uma maneira de determinar o quão bem temos previsto que uma palavra se encaixará em um contexto particular. O contexto da palavra, é um conjunto de palavras dentro de uma janela em torno, como mostrado abaixo:

A imagem acima mostra que o contexto para a sexta-feira inclui palavras como “gato” e “é”. O objetivo da rede neural é prever que “sexta-feira” cai dentro deste contexto.
nós ativamos a camada de saída multiplicando o vetor que passamos através da camada oculta (que era o vetor de entrada quente * pesos entrando no nó oculto) com uma representação vetorial da palavra de contexto (que é o vetor quente para a palavra de contexto * pesos entrando no nó de saída). O estado da camada de saída para a primeira contexto do word pode ser visualizada abaixo:

acima de multiplicação é feita para cada palavra em contexto par de palavras. Nós então calculamos a probabilidade de que uma palavra pertence com um conjunto de palavras de contexto usando os valores resultantes das camadas ocultas e de saída. Por último, aplicamos descida de gradiente estocástico para alterar os valores dos pesos, a fim de obter um valor mais desejável para a probabilidade calculada.
em Descida gradiente precisamos calcular o gradiente da função que está sendo otimizada no ponto que representa o peso que estamos mudando. O gradiente é então usado para escolher a direcção em que dar um passo para avançar para o ideal local, como mostrado no exemplo de minimização abaixo.
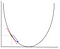
O peso vai ser alterado, tornando um passo na direção do ponto ótimo (no exemplo acima, o ponto mais baixo no gráfico). O novo valor é calculado subtraindo do valor do peso atual a função derivada no ponto do peso escalado pela taxa de aprendizagem. O próximo passo é usar Backpropagation, para ajustar os pesos entre várias camadas. O erro que é calculado no final da camada de saída é passado de volta da camada de saída para a camada oculta, aplicando a regra da cadeia. Descida gradiente é usado para atualizar os pesos entre estas duas camadas. O erro é então ajustado em cada camada e enviado de volta mais. Aqui está um diagrama para representar a contrapropagação:

Entendimento, usando o Exemplo
Word2vec usa uma única camada oculta, totalmente conectada rede neural, como mostrado abaixo. Os neurônios na camada oculta são todos neurônios lineares. A camada de entrada é definida para ter tantos neurônios quanto existem palavras no vocabulário para treinamento. O tamanho escondido da camada é definido para a dimensionalidade dos vetores palavra resultantes. O tamanho da camada de saída é o mesmo que a camada de entrada. Assim, se o vocabulário para a aprendizagem de vetores de palavras consiste de palavras V E N para ser a dimensão de vetores de palavras, a entrada para conexões de camadas ocultas pode ser representada pela matriz WI de tamanho VxN com cada linha representando uma palavra de vocabulário. Da mesma forma, as conexões de camada oculta para camada de saída podem ser descritas pela matriz WO de tamanho NxV. Neste caso, cada coluna da matriz WO representa uma palavra do vocabulário dado.

a entrada para A rede é codificado usando “1-out-of-V” representação significa que apenas uma linha de entrada é definida para um e o resto das linhas de entrada são definidos para zero.Suponhamos que temos um corpo de treino com as seguintes frases:”o cão viu um gato”, “o cão perseguiu o gato”, “o gato escalou uma árvore”
o vocabulário do corpo tem oito palavras. Uma vez ordenada alfabeticamente, cada palavra pode ser referenciada pelo seu índice. Para este exemplo, nossa rede neural terá oito neurônios de entrada e oito neurônios de saída. Vamos assumir que decidimos usar três neurônios na camada oculta. Isto significa que WI e WO serão 8×3 e 3×8 matrizes, respectivamente. Antes do início do treinamento, estas matrizes são inicializadas a pequenos valores aleatórios, como é habitual no treinamento de rede neural. Apenas para a ilustração, vamos assumir WI e WO para ser inicializado para os seguintes valores:

Suponha que a rede deve aprender a relação entre as palavras “gato” e “subiu”. Ou seja, a rede deve mostrar uma alta probabilidade para “escalado” quando “gato” é colocado para a rede. Na terminologia de incorporação de palavras, a palavra “gato” é referida como a palavra de contexto e a palavra “escalado” é referida como a palavra alvo. Neste caso, o vetor de entrada X será T. observe que apenas a segunda componente do vetor é 1. Isto é porque a palavra de entrada é “cat” que está mantendo a posição número dois na lista ordenada de palavras corpus. Dado que a palavra-alvo é “subiu”, o destino do vetor será parecido com t. Com o vetor de entrada que representam “o gato”, a saída da neurônios das camadas ocultas pode ser calculada como:
Ht = XtWI =
não deve nos surpreender que o vetor H do neurônio oculto saídas imita os pesos da segunda linha de WI matriz por causa de 1-fora-de-Vrepresentation. Então a função da entrada para conexões de camada oculta é basicamente copiar o vetor de palavra entrada para camada oculta. A realização de semelhante manipulações para oculta para a camada de saída, a ativação do vetor para a camada de saída de neurônios pode ser escrito como
HtWO =
Desde então, o objetivo é produzir probabilidades de palavras na camada de saída, Pr(wordk|wordcontext) para k = 1, V, de modo a refletir o seu próximo palavra de relacionamento com o contexto do word na entrada, temos a soma do neurônio saídas na camada de saída, para adicionar um. Word2vec consegue isso convertendo os valores de ativação dos neurônios da camada de saída para probabilidades usando a função softmax. Assim, a saída do k-ésimo neurônio é calculada pela expressão a seguir, onde a ativação(n) representa a ativação do valor do n-ésimo neurônio da camada de saída:
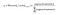
Assim, as probabilidades de oito palavras no corpus são:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
A probabilidade em negrito para o destino escolhido palavra “subiu”. Dado o vetor-alvo t, o vetor de erro para a camada de saída é facilmente computado subtraindo o vetor de probabilidade do vetor-alvo. Uma vez que o erro é conhecido, os pesos nas matrizes WO e WI podem ser atualizados usando backpropagation. Assim, o treinamento pode prosseguir apresentando diferentes palavras de contexto-alvo do corpus. É assim que Word2vec aprende relações entre palavras e no processo desenvolve representações vetoriais para palavras no corpus.
a ideia por trás do word2vec é representar palavras por um vetor de números reais de dimensão D. Portanto, a segunda matriz é a representação dessas palavras. A linha i-ésima desta matriz é a representação vetorial da palavra i-ésima. Digamos que em seu exemplo você tem 5 palavras:, então o primeiro vetor significa que você está considerando a palavra “cavalo” e assim a representação de “cavalo” é . Similarmente, é a representação da palavra “Leão”.

Para meu conhecimento, não há nenhum “humano” significado ” especificamente para cada um dos números nessas representações. Um número não representa se a palavra é um verbo ou não, um adjetivo ou não… são apenas os pesos que você muda para resolver o seu problema de otimização para aprender a representação de suas palavras.
Um diagrama visual melhor elaboração word2vec multiplicação de matrizes processo é ilustrado na figura a seguir:

A primeira matriz representa o vetor de entrada em um quente formato. A segunda matriz representa os pesos sinápticos dos neurônios de camada de entrada para os neurônios de camada oculta. Observe especialmente o canto superior esquerdo onde a matriz da camada de entrada é multiplicada pela matriz de peso. Agora olha para a parte superior direita. Esta multiplicação de matrizes dot-producted com pesos Transpose é apenas uma maneira útil de representar a rede neural no canto superior direito.
a primeira parte, representa a palavra de entrada como um vetor quente e a outra matriz representa o peso para a conexão de cada um dos neurônios da camada de entrada com os neurônios da camada oculta. Como os trens Word2Vec, ele backpropagates (usando descida gradiente) para estes pesos e muda-os para dar melhores representações de palavras como vetores. Uma vez que o treinamento é realizado, você usa apenas esta matriz de peso, tomar por dizer ‘ cão ‘ e multiplicá-lo com a matriz de peso melhorada para obter a representação vetorial de ‘cão’ em uma dimensão = não de neurônios de camada oculta. No diagrama, o número de neurônios de camada oculta é 3.
In a nutshell, Skip-gram model reverses the use of target and context words. Neste caso, a palavra-alvo é alimentada na entrada, a camada escondida permanece a mesma, e a camada de saída da rede neural é replicada várias vezes para acomodar o número escolhido de palavras de contexto. Tomando o exemplo de ” cat ” e ” tree “como palavras de contexto e” escalado “como a palavra-alvo, o vetor de entrada no modelo de” skim-gram ” seria t, enquanto as duas camadas de saída teriam t E t como vetores-alvo, respectivamente. No lugar de produzir um vetor de probabilidades, dois desses vetores seriam produzidos para o exemplo atual. O vetor de erro para cada camada de saída é produzido da maneira como discutido acima. No entanto, os vetores de erro de todas as camadas de saída são somados para ajustar os pesos via backpropagation. Isto garante que a matriz de peso WO para cada camada de saída permanece idêntica durante todo o treinamento.
precisamos de algumas modificações adicionais ao modelo básico de Pula-grama que são importantes para tornar possível treinar. A descer gradiente numa rede neural tão grande vai ser lenta. E para piorar as coisas, você precisa de uma enorme quantidade de dados de treinamento para afinar que muitos pesos e evitar excesso de ajuste. milhões de pesos vezes biliões de amostras de treino significa que treinar este modelo vai ser uma besta. Para isso, os autores propuseram duas técnicas chamadas amostragem subamostrada e negativa em que palavras insignificantes são removidas e apenas uma amostra específica de pesos são atualizados.Mikolov et al. também use uma abordagem simples de subamostragem para combater o desequilíbrio entre palavras raras e frequentes no conjunto de treinamento (por exemplo, “in”, “the”, e “a” fornecem menos valor de Informação do que palavras raras). Cada palavra no conjunto de treinamento é descartado com probabilidade P(wi), onde

f(wi) é a freqüência da palavra wi e t é um limiar escolhido, geralmente em torno de 10-5.
detalhes de implementação
Word2vec tem sido implementado em várias línguas, mas aqui vamos focar especialmente em Java., DeepLearning4j, darks-learning e python . Vários algoritmos de rede neural foram implementados em DL4j, o código está disponível em GitHub.
para implementá-lo em DL4j, vamos passar por alguns passos dados da seguinte forma:
a) configuração Word2Vec
crie um novo projeto em Intelij usando Maven. Em seguida, especifique propriedades e dependências no POM.ficheiro xml no directório raiz do seu projecto.
B) carregar dados
agora criar e nomear uma nova classe em Java. Depois disso, vais ficar com as frases cruas.txt file, atravesse-os com o seu iterator, e sujeite-os a algum tipo de pré-processamento, como a conversão de todas as palavras para minúsculas.
String filePath = new ClassPathResource (“raw_sentences.txt”).getFile ().getAbsolutePath ();
log.info (“Load & Vectorize Sentences….”);
// remover o espaço em branco antes e depois de cada linha
iter do Sentenceiterador = novo Basiclineiterador (filePath);
se quiser carregar um ficheiro de texto para além das frases fornecidas no nosso exemplo, faria isto:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) Toquenizar os dados
Word2vec precisa ser alimentado com palavras em vez de frases inteiras, de modo que o próximo passo é para toquenizar os dados. Tokenize a text is to break it up into its atomic units, creating a new token each time you hit a white space, for example.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) treinar o modelo
agora que os dados estão prontos, você pode configurar a rede neural Word2vec e se alimentar nos tokens.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
esta configuração aceita vários hiperparametros. Alguns requerem alguma explicação.:
- batchSize é a quantidade de palavras que você processa de uma vez.
- a frequência mínima é o número mínimo de vezes que uma palavra deve aparecer no corpo. Aqui, se aparecer menos de 5 vezes, não é aprendido. As palavras devem aparecer em vários contextos para aprender características úteis sobre elas. Em corpora muito grande, é razoável aumentar o mínimo.
- useAdaGrad-Adagrad cria um gradiente diferente para cada característica. Aqui não estamos preocupados com isso.
- layerSize specifies the number of features in the word vector. Isto é igual ao número de dimensões no featurespace. Palavras representadas por 500 características tornam-se pontos num espaço de 500 dimensões.
- learningRate é o tamanho do passo para cada atualização dos coeficientes, como as palavras são reposicionadas no espaço de recursos.
- taxa de aprendizagem é a base da taxa de aprendizagem. A taxa de aprendizagem diminui à medida que o número de palavras que você treina diminui. Se a taxa de aprendizagem diminui demasiado, a aprendizagem da rede já não é eficiente. Isto mantém os coeficientes em movimento.Iterate diz à rede em que Lote do conjunto de dados está a treinar.
- tokenizer alimenta as palavras do lote atual.
- vec.fit () diz à rede configurada para começar a treinar.
e) avaliar o modelo, usando Word2vec
o próximo passo é avaliar a qualidade dos seus vetores de recurso.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
a linha vec.similarity("word1","word2") irá devolver a semelhança Cosina das duas palavras que você entra. Quanto mais perto está de 1, Mais Semelhante a rede percebe essas palavras para ser (Veja o exemplo Suécia-Noruega acima). Por exemplo:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
com vec.wordsNearest("word1", numWordsNearest), as palavras impressas no ecrã permitem-lhe ver se a rede reuniu palavras semanticamente semelhantes. Você pode definir o número de palavras mais próximas que você deseja com o segundo parâmetro de wordsNearest. Por exemplo:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec em Java, em http://deeplearning4j.org/word2vec.html
7) Word2Vec e Doc2Vec em Python no genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html