Hidden Markov Model (HMM) je statistický Markov model, ve kterém systému, který je modelován předpokládá, že se markovský proces s nepozorovaně (tj. skrytý) státy.
Skryté Markovovy modely jsou zvláště známé pro jejich aplikaci v učení zesílení a časové rozpoznávání, jako je řeč, písmo, gesto uznání, part-of-speech tagging, hudební skóre po částečné výboje a bioinformatika.
terminologie v HMM
termín skrytý odkazuje na Markovův proces prvního řádu za pozorováním. Pozorování se týká údajů, které známe a můžeme pozorovat. Markov procesu je zobrazena interakce mezi „Prší“ a „Sunny“ v níže uvedeném diagramu a každý z nich jsou SKRYTÉ STÁTY.

POZOROVÁNÍ jsou známá data a odkazuje na „Procházku“, „Obchod“, a „Čistý“ ve výše uvedeném diagramu. Ve smyslu strojového učení je pozorování naše tréninková data a počet skrytých stavů je náš hyper parametr pro náš model. Vyhodnocení modelu bude diskutováno později.

T = nemám žádné pozorování ještě, N = 2, M = 3, Q = {„Deštivý“, „Sunny“}, V = {„Chůze“, „Obchod“, „Čisté“,}
Státní pravděpodobnosti přechodu jsou šipky směřující k sobě skryté státu. Matice pravděpodobnosti pozorování jsou modré a červené šipky ukazující na každé pozorování z každého skrytého stavu. Matice jsou řádkové stochastické, což znamená, že řádky sčítají až 1.


matrix vysvětluje, co je pravděpodobnost, že se jde z jednoho státu do druhého, nebo jít z jednoho státu do pozorování.
počáteční rozdělení stavu způsobí, že model začne ve skrytém stavu.
Plné model se známým státu, pravděpodobnosti přechodu, pravděpodobnost pozorování matice a počáteční stav rozdělení je označen jako,
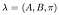
Jak můžeme stavět výše uvedený model v Pythonu?
ve výše uvedeném případě jsou emise diskrétní {„Walk“, „Shop“, „Clean“}. MultinomialHMM z knihovny hmmlearn se používá pro výše uvedený model. GaussianHMM a GMMHMM jsou další modely v knihovně.
nyní s HMM jaké jsou některé klíčové problémy k vyřešení?
- Problém 1, Vzhledem ke známému modelu jaká je pravděpodobnost děje sekvence O?
- Problém 2, vzhledem ke známému modelu a sekvenci O, jaká je optimální sekvence skrytého stavu? To bude užitečné, pokud chceme vědět, zda je počasí „deštivé“nebo“ slunečné “
- problém 3, Vzhledem k sekvenci O a počtu skrytých stavů, jaký je optimální model, který maximalizuje pravděpodobnost O?
Problém 1 v Pythonu
pravděpodobnost, Že první pozorování, že „Chůze“ se rovná vynásobení původního stavu distribuce a emise pravděpodobnostní matice. 0,6 x 0,1 + 0,4 x 0,6 = 0,30 (30%). Pravděpodobnost protokolu je poskytována z volání .skóre.
Problém v Pythonu 2

Vzhledem k tomu známé modelu a pozorování {„Obchod“, „Čistý“, „Chůze“}, počasí bylo nejvíce pravděpodobné, {„Prší“, „Prší“, „Sunny“,} s ~1.5% pravděpodobnost.
vzhledem ke známému modelu a pozorování {„Clean“,“ Clean“,“ Clean“} bylo počasí s největší pravděpodobností {„Rainy“, „Rainy“, „Rainy“} s ~3,6% pravděpodobností.
intuitivně, když dojde k „procházce“, počasí s největší pravděpodobností nebude „Deštivé“.
Problém 3 v Pythonu
rozpoznávání Řeči s Audio Soubor: Předvídat tyto slova

Amplituda může být použit jak pro POZOROVÁNÍ HMM, ale funkce inženýrství nám dá větší výkon.

Funkce stft a peakfind generuje funkce pro audio signál.
výše uvedený příklad byl převzat odtud. Kyle Kastner postavený HMM třídu, která bere v 3D pole, používám hmmlearn který umožňuje pouze 2d pole. To je důvod, proč jsem snížení funkce generované Kyle Kastner jako X_test.průměr (osa=2).
procházení tímto modelováním trvalo hodně času, než jsme to pochopili. Měl jsem dojem, že cílovou proměnnou musí být pozorování. To platí pro časové řady. Klasifikace se provádí sestavením HMM pro každou třídu a porovnáním výstupu výpočtem logprob pro váš vstup.
Matematické Řešení Problém 1: Vpřed Algoritmus

Alfa pass je pravděpodobnost POZOROVÁNÍ a STÁTNÍ sekvence daného modelu.
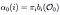
Alfa projít v čase (t) = 0, počáteční stav rozdělení na já a odtud k první pozorování O0.
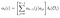
Alfa projít v čase (t) = t, součet poslední alfa projít, aby každý skrytý státní násobí emisí na Ot.
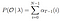
matematické řešení problému 2: Backward Algoritmus


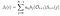

Daný model a pozorování, pravděpodobnost bytí ve stavu qi v čase t.
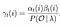
Matematické Řešení Problému 3: Forward-Backward Algoritmus


Pravděpodobnost, že ze stavu qi do qj v čase t s daného modelu a pozorování
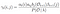
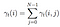
Součet všech pravděpodobnost přechodu z i do j.
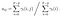
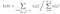
Přechod a emisí pravděpodobnostní matice se odhaduje, že s di-gama.
Iterujte, pokud se pravděpodobnost pro P(O|model) zvýší