V tomto tutoriálu se budeme vysvětlovat, jeden z nových a významných slovo vkládání techniku zvanou Word2Vec navržené Mikolov et al. v roce 2013. Shromáždili jsme tento obsah z různých výukových programů a zdrojů, abychom usnadnili čtenářům na jednom místě. Doufám, že to pomůže.
Word2vec je kombinací modelů se používá k reprezentaci distribuované reprezentace slov v korpusu. C. Word2Vec (W2V) je algoritmus, který přijímá text corpus jako vstupní a výstupní vektorová reprezentace pro každé slovo, jak je znázorněno na obrázku níže:

Existují dvě varianty tohoto algoritmu, a to: CBOW a Skip-Gram. Vzhledem k tomu, sadu vět (také volal corpus) model smyčky na slova, každé věty, a to buď zkusí použít aktuální slovo w za účelem odhadu jeho sousedy (tj. kontext), tento přístup se nazývá „Přeskočit-Gram“, nebo používá každý z těchto kontextů, předvídat aktuální slovo w, tak v tom případě metoda se nazývá „Kontinuální Pytel Slova“ (CBOW). Pro omezení počtu slov v každém kontextu se používá parametr nazvaný „velikost okna“.

vektory budeme používat k reprezentaci slov, se nazývají neurální slovo embeddings, a prohlášení, jsou podivné. Jedna věc popisuje druhou, i když tyto dvě věci jsou radikálně odlišné. Jak řekl Elvis Costello: „psaní o hudbě je jako tanec o architektuře.“Word2vec“ vektorizuje “ o slovech, a tím dělá přirozený jazyk počítačově čitelný-můžeme začít provádět výkonné matematické operace na slovech, abychom zjistili jejich podobnosti.
takže vložení neurálního slova představuje slovo s čísly. Je to jednoduchý, ale nepravděpodobný překlad. Word2vec je podobný autoencoder, kódování každé slovo v je vektor, ale spíše než trénink proti vstupní slova prostřednictvím rekonstrukce, jako omezený Boltzmannův stroj, word2vec vlaky slova proti jiným slovy, že soused je do vstupního korpusu.
činí tak jedním ze dvou způsobů, buď pomocí kontextu předpovědět cílové slovo (metoda známá jako spojitý pytel slov, nebo CBOW), nebo pomocí slova předpovědět cílový kontext, který se nazývá skip-gram. Používáme druhou metodu, protože vytváří přesnější výsledky na velkých datových sadách.

Když je funkce vektoru přiřazeny slovo nemůže být použit, aby přesně předpovědět, že slovo je kontext, složky vektoru jsou upraveny. Kontext každého slova v korpusu je učitel, který posílá chybové signály zpět, aby upravil vektor vlastností. Vektory slov posuzovaných podobně podle jejich kontextu jsou posunuty blíže k sobě úpravou čísel ve vektoru. V tomto tutoriálu se budeme soustředit na Skip-Gram modelu, který na rozdíl od CBOW zvážit center slovo jako vstup, jak je znázorněno na obrázku výše a předvídat kontextu slova.
Model přehled
pochopili Jsme, že budeme muset krmit některé podivné neuronové sítě s nějakou dvojici slov, ale nemůžeme dělat, že použití jako vstupy, skutečné postavy, musíme najít nějaký způsob, jak reprezentovat tato slova matematicky tak, že síť může je zpracovávat. Jedním ze způsobů, jak toho dosáhnout, je vytvořit slovní zásobu všech slov v našem textu a poté zakódovat naše slovo jako vektor stejných rozměrů naší slovní zásoby. Každá dimenze může být myšlena jako slovo v naší slovní zásobě. Takže budeme mít vektor se všemi nulami a 1, což představuje odpovídající slovo ve slovní zásobě. Tato technika kódování se nazývá One-hot kódování. Vzhledem k našemu příkladu, pokud budeme mít slovní zásobu vyrobený z slova,““, „rychlý“, „hnědá“, „liška“, „skoky“, „nad“,““, „líný“, „pes“, slovo „hnědé“ je reprezentován vektorem: .

Skip-gram model bere v korpusu z textu a vytvoří sexy-vektor pro každé slovo. Horký vektor je vektorová reprezentace slova, kde vektor je velikost slovní zásoby (celkem jedinečná slova). Všechny dimenze jsou nastaveny na 0 kromě dimenze představující slovo, které se v daném okamžiku používá jako vstup. Zde je příklad, horké vektor:

výše uvedené zadání je dané neuronové sítě s jednou skrytou vrstvou.
budeme reprezentovat vstupní slovo jako „mravenci“ jako jeden horký vektor. Tento vektor bude mít 10 000 komponent (jeden pro každé slovo v naší slovní zásobě) a umístíme „1“ do polohy odpovídající slovu „mravenci“ a 0s do všech ostatních pozic. Výstupem sítě je jediný vektor (také s 10 000 komponentami) obsahující pro každé slovo v naší slovní zásobě pravděpodobnost, že náhodně vybrané blízké slovo je slovo slovní zásoby.
v aplikaci word2vec se používá distribuovaná reprezentace slova. Vezměte vektor s několika stovkami rozměrů (řekněme 1000). Každé slovo je reprezentováno rozdělením závaží mezi tyto prvky. Takže místo toho, one-to-one mapování mezi prvek ve vektoru a slovo,, zastoupení slova se šíří přes všechny prvky ve vektoru, a každý prvek ve vektoru přispívá k definici mnoha slovy.
Pokud jsem označení rozměry v hypotetické slovo vektor (nejsou tam žádné takové předem přiřazeny štítky v algoritmu, samozřejmě), to by mohlo vypadat trochu jako toto:

Takový vektor je dodáván se představují v abstraktním způsobem, její „význam“ slova. A jak uvidíme dále, pouhým zkoumáním velkého korpusu je možné se naučit slovní vektory, které jsou schopny zachytit vztahy mezi slovy překvapivě expresivním způsobem. Vektory můžeme také použít jako vstupy do neuronové sítě. Protože naše vstupní vektory jsou jedno-horké, vynásobením vstupního vektoru hmotnostní maticí W1 se rovná jednoduchému výběru řádku z W1.
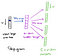

Ze skryté vrstvy do výstupní vrstvy, druhý hmotnosti matice W2 může být použita pro výpočet skóre pro každé slovo ve slovníku, a softmax mohou být použity k získání posteriorního rozdělení slova. Skip-gram model je opakem modelu CBOW. Je konstruován s fokusním slovem jako jediným vstupním vektorem a cílová kontextová slova jsou nyní na výstupní vrstvě. Aktivační funkce pro skrytou vrstvu se jednoduše rovná kopírování odpovídajícího řádku z matice závaží W1 (lineární), jak jsme viděli dříve. Na výstupní vrstvě nyní vydáváme multinomiální distribuce C místo pouze jedné. Cílem školení je napodobit sčítanou chybu predikce napříč všemi kontextovými slovy ve výstupní vrstvě. V našem příkladu by vstup byl „učení“ a doufáme, že na výstupní vrstvě uvidíme („an“, „efektivní“, „metoda“, „pro“, „Vysoká“, „kvalita“, „distribuovaná“, „vektor“).
zde je architektura naší neuronové sítě.

Pro náš příklad, budeme říkat, že jsme učení slovo vektorů s 300 funkcemi. Takže skrytá vrstva bude reprezentována hmotnostní maticí s 10 000 řádky (jeden pro každé slovo v naší slovní zásobě) a 300 sloupci(jeden pro každý skrytý neuron). 300 funkcí je to, co Google použil ve svém publikovaném modelu vyškoleném v datovém souboru Google news (Můžete si jej stáhnout zde). Počet funkcí je „hyper parametr“, který byste prostě museli naladit na svou aplikaci(to znamená vyzkoušet různé hodnoty a zjistit, co přináší nejlepší výsledky).
pokud se podíváte na řádky této hmotnostní matice, budou to naše slovní vektory!

Takže konečný cíl všech je to opravdu jen naučit se této skryté vrstvy hmotnost matrix — výstupní vrstva budeme jen přehazovat, když jsme skončili! Vektor 1 x 300 slov pro „mravence“ se pak přivádí do výstupní vrstvy. Výstupní vrstva je softmax regresní klasifikátor. Konkrétně každý výstupní neuron má váhový vektor, který násobí proti slovnímu vektoru ze skryté vrstvy, pak na výsledek aplikuje funkci exp(x). Nakonec, aby výstupy byly sečteny až na 1, vydělíme tento výsledek součtem výsledků ze všech 10 000 výstupních uzlů. Zde je ukázka výpočtu výstupu výstupního neuronu pro slovo „Auto“.

Pokud dvě různá slova mají velmi podobný „kontextech“ (to je, co slova jsou pravděpodobné, že se objeví kolem nich), pak náš model potřebuje k výkonu velmi podobné výsledky pro tyto dvě slova. Jedním ze způsobů, jak může síť vypsat podobné předpovědi kontextu pro tato dvě slova, je, pokud jsou vektory slova podobné. Pokud tedy dvě slova mají podobné kontexty, pak je naše síť motivována naučit se podobné slovní vektory pro tato dvě slova! Ta dá!
každá dimenze vstupu prochází každým uzlem skryté vrstvy. Rozměr se vynásobí hmotností, která ji vede ke skryté vrstvě. Protože vstup je horký vektor, pouze jeden ze vstupních uzlů bude mít nenulovou hodnotu (jmenovitě hodnotu 1). To znamená, že pro slovo budou aktivovány pouze váhy spojené se vstupním uzlem s hodnotou 1, Jak je znázorněno na obrázku výše.
protože vstup je v tomto případě horký vektor, pouze jeden ze vstupních uzlů bude mít nenulovou hodnotu. To znamená, že ve skrytých uzlech budou aktivovány pouze váhy připojené k tomuto vstupnímu uzlu. Příklad závaží, které bude považovat je znázorněno níže pro druhé slovo ve slovníku:
vektorové reprezentace druhé slovo ve slovníku (znázorněno na neuronové sítě výše) bude vypadat takto, jakmile je aktivován ve skryté vrstvě:
Tyto váhy začít jako náhodné hodnoty. Síť je poté vyškolena, aby upravila závaží tak, aby reprezentovala vstupní slova. Zde se stává důležitá výstupní vrstva. Nyní, když jsme ve skryté vrstvě s vektorovou reprezentací slova, potřebujeme způsob, jak určit, jak dobře jsme předpověděli, že slovo se vejde do konkrétního kontextu. Souvislosti slovo je soubor slov, v okně se kolem něj, jak je uvedeno níže:

výše uvedený obrázek ukazuje, že kontext, v pátek zahrnuje slova jako „kočka“ a „je“. Cílem neuronové sítě je předpovědět ,že „pátek“ spadá do tohoto kontextu.
aktivovat výstupní vrstvu vynásobením vektoru, který jsme prošli skryté vrstvy (což byl vstup horké vektor * závaží zadání skrytý uzel) s vektorovou reprezentaci kontextu slovo (což je horké vektor pro kontext slovo * závaží vstupu na výstup uzlu). Stav výstupní vrstva pro první kontext slova mohou být zobrazeny níže:

výše násobení je prováděno pro každé slovo do kontextu slovo dvojice. Potom vypočítáme pravděpodobnost, že slovo patří se sadou kontextových slov pomocí hodnot vyplývajících ze skrytých a výstupních vrstev. Nakonec použijeme stochastický gradientní sestup ke změně hodnot závaží, abychom získali více žádoucí hodnotu pro vypočtenou pravděpodobnost.
v gradientním sestupu musíme vypočítat gradient optimalizované funkce v bodě představujícím váhu, kterou měníme. Gradient se pak používá k volbě směru, kterým se má krok posunout směrem k lokálnímu optimu, jak ukazuje příklad minimalizace níže.
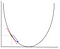
hmotnost se bude měnit tím, že krok ve směru optimální bod (ve výše uvedeném příkladu, nejnižší bod v grafu). Nová hodnota se vypočítá odečtením od aktuální hodnoty hmotnosti odvozené funkce v bodě hmotnosti zmenšené rychlostí učení. Dalším krokem je použití Backpropagation, upravit závaží mezi více vrstvami. Chyba, která je vypočtena na konci výstupní vrstvy, je předána zpět z výstupní vrstvy do skryté vrstvy použitím pravidla řetězce. Gradient descent se používá k aktualizaci závaží mezi těmito dvěma vrstvami. Chyba je pak upravena v každé vrstvě a odeslána zpět dále. Zde je diagram, který představuje backpropagaci:

Pochopení Příklad použití
Word2vec používá s jednou skrytou vrstvou, plně propojené neuronové sítě, jak je uvedeno níže. Neurony ve skryté vrstvě jsou všechny lineární neurony. Vstupní vrstva je nastavena tak, aby měla tolik neuronů, kolik je ve slovní zásobě pro trénink slov. Velikost skryté vrstvy je nastavena na rozměrnost výsledných vektorů slova. Velikost výstupní vrstvy je stejná jako vstupní vrstva. Pokud tedy slovní zásobu pro učení slovo vektorů se skládá ze slova V a N rozměr slovo vektorů, vstup do skryté vrstvy spojení může být reprezentován maticí WI velikosti VxN s každý řádek představuje slovní zásobu slovo. Stejným způsobem lze popsat spojení ze skryté vrstvy na výstupní vrstvu maticí WO velikosti NxV. V tomto případě každý sloupec matice WO představuje slovo z dané slovní zásoby.

vstup do sítě je kódován pomocí „1-z -V“ zastoupení, což znamená, že pouze jeden vstupní řádek je nastaven na jednu a zbytek vstupní řádky jsou nastaveny na nulu.
Nechte předpokládejme, že máme školení korpus s následující věty:
„pes viděl kočka“, „pes honil kočku“, „kočka vylezla na strom“
korpusu slovní zásobu má osm slova. Po abecedním pořadí může být každé slovo odkazováno podle jeho indexu. Pro tento příklad bude mít naše neuronová síť osm vstupních neuronů a osm výstupních neuronů. Předpokládejme, že se rozhodneme použít tři neurony ve skryté vrstvě. To znamená, že WI a WO budou matice 8×3 a 3×8. Před zahájením tréninku jsou tyto matice inicializovány na malé náhodné hodnoty, jak je obvyklé v tréninku neuronových sítí. Jen pro ilustraci předpokládejme, že WI a WO budou inicializovány na následující hodnoty:

Předpokládejme, že chceme, aby síť naučit vztah mezi slova „kočka“ a „vylezl“. To znamená, že síť by měla vykazovat vysokou pravděpodobnost „vylezeného“, když je do sítě vložena“ kočka“. V terminologii vkládání slov je slovo „kočka“ označováno jako kontextové slovo a slovo „vylezl“ je označováno jako cílové slovo. V tomto případě bude vstupní vektor X T. Všimněte si, že pouze druhá složka vektoru je 1. Je to proto, že vstupní slovo je „kočka“, která drží pozici číslo dvě v seřazeném seznamu korpusových slov. Vzhledem k tomu, že cílové slovo je „vylezl“, cílový vektor bude vypadat jako t. S vstupní vektor představující „kočka“, výstup na skryté vrstvy neuronů může být vypočítána jako:
Ht = XtWI =
To by nás nemělo překvapovat, že vektor H skrytý neuron výstupy napodobuje závaží druhé řady WI matrix, protože 1-out-of-Vrepresentation. Takže funkce vstupu do skryté vrstvy připojení je v podstatě kopírovat vektor vstupního slova do skryté vrstvy. Provádět podobné manipulace pro skryté do výstupní vrstvy, aktivace vektor pro výstupní vrstvu neuronů může být zapsáno jako
HtWO =
Vzhledem k tomu, že cílem je vyrábět pravděpodobnosti pro slov ve výstupní vrstvě, Pr(wordk|wordcontext) pro k = 1, V, aby odrážely jejich další slovo vztah s kontextu slovo v zadání, potřebujeme součet výstupy neuronu ve výstupní vrstvě přidat do jednoho. Word2vec toho dosahuje převodem aktivačních hodnot neuronů výstupní vrstvy na pravděpodobnosti pomocí funkce softmax. Tak, výstup k-tého neuronu je vypočítán podle následujícího vzorce, kde aktivace(n) představuje aktivační hodnota n-tý výstupní neuron vrstvy:
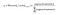
to Znamená, že pravděpodobnost pro osm slov v korpusu jsou:
0.143073 0.094925 0.114441 0.111166 0.149289 0.122874 0.119431 0.144800
pravděpodobnost, tučně je pro zvolené cílové slovo „vylezl“. Vzhledem k cílovému vektoru t se vektor chyb pro výstupní vrstvu snadno vypočítá odečtením vektoru pravděpodobnosti od cílového vektoru. Jakmile je chyba známa, mohou být váhy v maticích WO a WI aktualizovány pomocí backpropagation. Trénink tak může pokračovat prezentací různých kontextově-cílových slov z korpusu. Takto se Word2vec učí vztahy mezi slovy a v procesu vyvíjí vektorové reprezentace slov v korpusu.
myšlenka word2vec je reprezentovat slova vektorem reálných čísel dimenze d. Druhá matice je tedy reprezentací těchto slov. I-tý řádek této matice je vektorová reprezentace i-tý slova. Řekněme, že ve vašem příkladu máte 5 slova:, pak první vektor znamená, že zvažujete slovo „kůň“, a tak je reprezentace „koně“. Podobně je reprezentace slova „Lev“.

pokud je mi známo, neexistují žádné „lidský význam“, konkrétně pro každé z čísel v těchto reprezentací. Jedno číslo není představující pokud slovo je sloveso, nebo ne, přídavné jméno, nebo ne… To je jen činky, které můžete změnit, aby vyřešit váš problém optimalizace naučit zastoupení tvá slova.
vizuální diagram nejlepší zpracování word2vec násobení matic proces je znázorněn v následujícím obrázku:

první matrice představuje vstupní vektor v jeden horký formátu. Druhá matice představuje synaptické váhy od neuronů vstupní vrstvy po neurony skryté vrstvy. Zvláště si všimněte levého horního rohu, kde je matice vstupní vrstvy vynásobena hmotnostní maticí. Nyní se podívejte vpravo nahoře. Tato matice násobení InputLayer dot-produkoval s hmotností transponovat je jen šikovný způsob, jak reprezentovat neuronové sítě v pravém horním rohu.
první část, představuje vstupní slovo jako jeden hot vektor a druhá matice představuje hmotnost pro připojení každého ze vstupní vrstvy, neurony do skryté vrstvy neuronů. Jako Word2Vec trénuje, backpropaguje (pomocí gradientního sestupu) do těchto hmotností a mění je tak, aby poskytovaly lepší reprezentace slov jako vektorů. Jakmile školení je provést, můžete použít pouze tuto hmotnost matrix, si pro ‚pes‘ a vynásobíme s lepší hmotnosti matice získat vektorové reprezentace “ pes “ v dimenzi = žádné skryté vrstvy neuronů. V diagramu je počet neuronů skryté vrstvy 3.
Stručně řečeno, Skip-gram model zvrátí použití cílových a kontextových slov. V tomto případě je cílové slovo je přiváděn na vstupní, skryté vrstvě zůstává stejný, a výstupní vrstvu neuronové sítě se opakuje několikrát, aby se přizpůsobila vybrané číslo z kontextu slova. Vezmeme-li jako příklad „kočka“ a „strom“ jako kontext slov a „vylezl“ jako cílové slovo, vstupní vektor v skim-gram modelu by t, zatímco dva výstupní vrstvy by t a t jako target vektory, resp. Namísto vytvoření jednoho vektoru pravděpodobností by byly pro současný příklad vytvořeny dva takové vektory. Chybový vektor pro každou výstupní vrstvu je vytvořen způsobem, jak je popsáno výše. Chybové vektory ze všech výstupních vrstev se však sčítají, aby se váhy upravily pomocí backpropagace. Tím je zajištěno, že hmotnostní matice WO pro každou výstupní vrstvu zůstává identická po celou dobu tréninku.
potřebujeme několik dalších úprav základního skip-gramového modelu, které jsou důležité pro to, aby bylo možné trénovat. Spuštění gradientního sestupu na tak velké neuronové síti bude pomalé. A aby toho nebylo málo, potřebujete obrovské množství tréninkových dat, abyste vyladili tolik závaží a vyhnuli se nadměrné montáži. miliony závaží krát miliardy tréninkových vzorků znamená, že trénink tohoto modelu bude zvíře. Za to, že autoři navrhli dvě techniky tzv. podvzorkování a negativních vzorků, v nichž bezvýznamné slova jsou odstraněny a jen specifický vzorek váhy jsou aktualizovány.
Mikolov et al. také použít jednoduchý subsampling přístup k counter nerovnováha mezi vzácné a nejčastější slova v tréninku (například, „v“, „na“ a „a“ poskytnout menší informační hodnotu než vzácných slov). Každé slovo v tréninku je zlikvidovat s pravděpodobností P(wi), kde

f(wi) je frekvence slovo wi a t je zvolená prahová hodnota, obvykle kolem 10-5.
detaily implementace
Word2vec byl implementován v různých jazycích, Ale zde se zaměříme zejména na Javu, tj., DeepLearning4j, darks-learning a python . V DL4j byly implementovány různé algoritmy neuronových sítí, kód je k dispozici na Githubu.
Chcete-li jej implementovat v DL4j, projdeme několik kroků uvedených následovně:
a) Word2Vec Setup
vytvořte nový projekt v IntelliJ pomocí Maven. Poté zadejte vlastnosti a závislosti v POM.xml soubor v kořenovém adresáři vašeho projektu.
b) načíst data
nyní vytvořte a pojmenujte novou třídu v Javě. Potom, budete mít syrové věty ve vašem .txt soubor, přejít je s iterator, a předmět je nějaká pre-zpracování, jako je například převod všech slov na malá písmena.
String filePath = new ClassPathResource(„raw_sentences.txt“).getFile().getAbsolutePath ();
log.info („Load & vektorizovat věty….“);
// Proužek bílý prostor před a po pro každou řádku
SentenceIterator iter = new BasicLineIterator(filePath);
Pokud chcete načíst textový soubor, kromě věty, za předpokladu, v našem příkladu, že to uděláš:
log.info("Load data....");SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));iter.setPreProcessor(new SentencePreProcessor() {@Overridepublic String preProcess(String sentence) {return sentence.toLowerCase();}});
c) tokenizace dat
Word2vec musí být krmena spíše slovy než celými větami, takže dalším krokem je tokenizace dat. Tokenizace textu znamená rozdělit jej na atomové jednotky a vytvořit nový token pokaždé, když narazíte na bílé místo.
// Split on white spaces in the line to get wordsTokenizerFactory t = new DefaultTokenizerFactory();t.setTokenPreProcessor(new CommonPreprocessor());
d) trénink modelu
Nyní, když jsou data připravena, můžete nakonfigurovat neuronovou síť Word2vec a podávat tokeny.
log.info("Building model....");Word2Vec vec = new Word2Vec.Builder().minWordFrequency(5).layerSize(100).seed(42).windowSize(5).iterate(iter).tokenizerFactory(t).build();log.info("Fitting Word2Vec model....");vec.fit();
tato konfigurace přijímá několik hyperparametrů. Několik vyžaduje nějaké vysvětlení:
- batchSize je množství slov, které zpracováváte najednou.
- minWordFrequency je minimální počet, kolikrát se musí slovo v korpusu objevit. Zde, pokud se objeví méně než 5krát, není to naučeno. Slova se musí objevit ve více kontextech, aby se o nich dozvěděli užitečné funkce. Ve velmi velkých korpusech je rozumné zvýšit minimum.
- useAdaGrad-Adagrad vytváří jiný gradient pro každou funkci. Tady se tím nezabýváme.
- layerSize určuje počet funkcí ve vektoru slova. To se rovná počtu rozměrů ve funkciprostor. Slova reprezentovaná 500 funkcemi se stávají body v 500rozměrném prostoru.
- learningRate je velikost kroku pro každou aktualizaci koeficientů, protože slova jsou přemístěna do prostoru funkce.
- minLearningRate je podlaha na rychlosti učení. Rychlost učení se rozpadá, protože počet slov, na kterých trénujete, klesá. Pokud se míra učení příliš zmenší, učení sítě již není efektivní. To udržuje koeficienty v pohybu.
- iterace řekne síti, na jaké dávce datové sady trénuje.
- tokenizer napájí slova z aktuální dávky.
- vec.fit() řekne nakonfigurované síti, aby začala trénovat.
e) vyhodnocení modelu pomocí Word2vec
dalším krokem je vyhodnocení kvality vektorů funkcí.
// Write word vectorsWordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");log.info("Closest Words:");Collection<String> lst = vec.wordsNearest("day", 10);System.out.println(lst);UiServer server = UiServer.getInstance();System.out.println("Started on port " + server.getPort());//output:
řádek vec.similarity("word1","word2") vrátí kosinusovou podobnost dvou zadaných slov. Čím blíže je k 1, tím podobnější síť vnímá tato slova (Viz výše uvedený příklad Švédsko-Norsko). Příklad:
double cosSim = vec.similarity("day", "night");System.out.println(cosSim);//output: 0.7704452276229858
S vec.wordsNearest("word1", numWordsNearest), slova vytištěné na obrazovce vám umožní bulvy, zda síť má seskupený sémanticky podobná slova. Můžete nastavit počet nejbližších slov, které chcete s druhým parametrem wordsNearest. Například:
Collection<String> lst3 = vec.wordsNearest("man", 10);System.out.println(lst3);//output:
1) http://mccormickml.com/2016/04/27/word2vec-resources/
2) https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
3) https://deeplearning4j.org/docs/latest/deeplearning4j-nlp-word2vec
4) https://intothedepthsofdataengineering.wordpress.com/2017/06/26/an-overview-of-word2vec/
5) https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
6) Word2vec v jazyce Java v http://deeplearning4j.org/word2vec.html
7) Word2Vec a Doc2Vec v Pythonu v genism http://radimrehurek.com/2013/09/deep-learning-with-word2vec-and-gensim/
8) http://rare-technologies.com/word2vec-tutorial/
9) https://www.tensorflow.org/versions/r0.8/tutorials/word2vec/index.html