Non-uniform memory access (NUMA), je sdílená paměť architektura používaná v dnešní multiprocessing systémy. Každému CPU je přiřazena vlastní lokální paměť a má přístup k paměti z jiných procesorů v systému. Přístup k místní paměti poskytuje nízkou latenci-vysoký výkon šířky pásma. Při přístupu k paměti vlastněné jiným CPU má vyšší latenci a nižší výkon šířky pásma. Moderní aplikace a operační systémy, jako je ESXi, podporují NUMA ve výchozím nastavení, přesto poskytují nejlepší výkon, konfigurace virtuálního stroje by měla být provedena s ohledem na architekturu NUMA. Pokud chyby přiřazení nesprávné přípony navržen tak, nedůslednou chování nebo celkový výkon dochází k rozkladu pro konkrétní virtuální stroj, nebo v nejhorším případě pro všechny VMs běží na ESXi.
cílem této řady je poskytnout přehled o architektuře CPU, paměťovém subsystému a plánovači CPU a paměti ESXi. Umožňuje vám vytvořit vysoce výkonnou platformu, která položí základy pro vyšší služby a zvýšené konsolidační poměry. Než se dostaneme k moderním výpočetním architekturám, je užitečné přezkoumat historii multiprocesorových architektur se sdílenou pamětí, abychom pochopili, proč dnes používáme systémy NUMA.
- vývoj sdílené paměti multiprocessors architektury v posledním desetiletí
- zavedení protokolů caching snoop
- Jednotné Přístup do Paměti Architektura
- nejednotná Architektura přístupu do paměti
- 1: Non-Uniform Memory Access organizace
- 2: Point-to-Point propojení
- 3: škálovatelná koherence mezipaměti
- Non-interleaved povoleno NUMA = SUMA
- Nehalem & Core mikroarchitektury přehled
vývoj sdílené paměti multiprocessors architektury v posledním desetiletí
zdá se, že architektura tzv. Jednotného Přístupu do Paměti by bylo lepší uchycení při navrhování konzistentní nízkou latencí, vysokou šířku pásma platformy. Moderní systémové architektury ji však omezí v tom, aby byla skutečně jednotná. Abychom pochopili důvod, proč se musíme vrátit do historie, abychom identifikovali klíčové ovladače paralelních výpočtů.
S zavedení relačních databází v počátku sedmdesátých let, potřeba systémů, které by mohly služby více souběžných uživatelských operací a nadměrné generování dat se stal hlavní proud. Přes impozantní rychlost jednoprocesorové výkon, víceprocesorové systémy jsou lépe vybaveni pro zpracování této práce. S cílem poskytnout nákladově efektivní systém, sdílená paměť adresní prostor se stal předmětem výzkumu. Brzy na, systémů pomocí břevna spínač obhajoval, nicméně s tímto designem složitosti zmenšen spolu s nárůstem procesory, což z autobusu-based systém více atraktivní. Procesory v systému sběrnice jsou povoleny pro přístup k celé paměti zasláním žádosti na autobus, velmi nákladově efektivní způsob, jak využít dostupné paměti, jak optimálně jak je to možné.
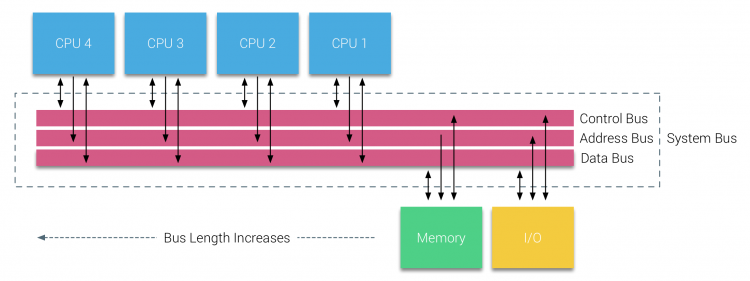
systémy založené na sběrnici však mají své vlastní problémy se škálovatelností. Hlavním problémem je omezené množství šířky pásma, což omezuje počet procesorů, které sběrnice pojme. Přidávání Procesorů do systému zavádí dvě hlavní oblasti zájmu:
- dostupné šířky pásma na uzel snižuje, jak každý PROCESOR dodal.
- délka sběrnice se zvyšuje při přidávání více procesorů, čímž se zvyšuje latence.
růst výkonu procesoru a konkrétně rychlostní mezera mezi procesorem a výkonem paměti byla a ve skutečnosti stále je devastující pro multiprocesory. Vzhledem k tomu, že se očekával nárůst mezery v paměti mezi procesorem a pamětí, vynaložilo se velké úsilí na vývoj účinných strategií pro správu paměťových systémů. Jednou z těchto strategií bylo přidání mezipaměti paměti, což představovalo řadu výzev. Řešení těchto výzev je stále hlavním zaměřením dnešních týmů pro návrh CPU, hodně výzkumu se provádí na strukturách ukládání do mezipaměti a sofistikovaných algoritmech, aby se zabránilo chybám mezipaměti.
zavedení protokolů caching snoop
připojení mezipaměti ke každému CPU zvyšuje výkon mnoha způsoby. Přiblížení paměti k CPU snižuje průměrnou dobu přístupu k paměti a současně snižuje zatížení šířky pásma na paměťové sběrnici. Výzva s přidáním mezipaměti do každého CPU v architektuře sdílené paměti spočívá v tom, že umožňuje existovat více kopií paměťového bloku. Tomu se říká problém s koherencí mezipaměti. K vyřešení tohoto, cache snoop protokoly byly vynalezeny snaží vytvořit model, který poskytuje správné údaje, zatímco se snaží sníst všechny pásma na sběrnici. Nejoblíbenější protokol, write invalidate, vymaže všechny ostatní kopie dat před zápisem místní mezipaměti. Jakékoli následné čtení dat jiných zpracovatelů bude detekovat cache ve své místní vyrovnávací paměti a budou obsluhovány z mezipaměti jiného PROCESORU, obsahující naposledy změněná data. Tento model zachránil spoustu šířka pásma sběrnice a umožňuje Jednotné Memory Access systémy objevují v časných 1990. Moderní koherence cache protokoly jsou zahrnuty podrobněji v části 3.
Jednotné Přístup do Paměti Architektura
Procesory Sběrnice založené na multiprocessors, že zkušenost stejná – jednotná – přístupová doba do paměti modulu, v systému jsou často označovány jako Uniform Memory Access (UMA) systémy nebo Symetrický Multi-Procesorů (Smp).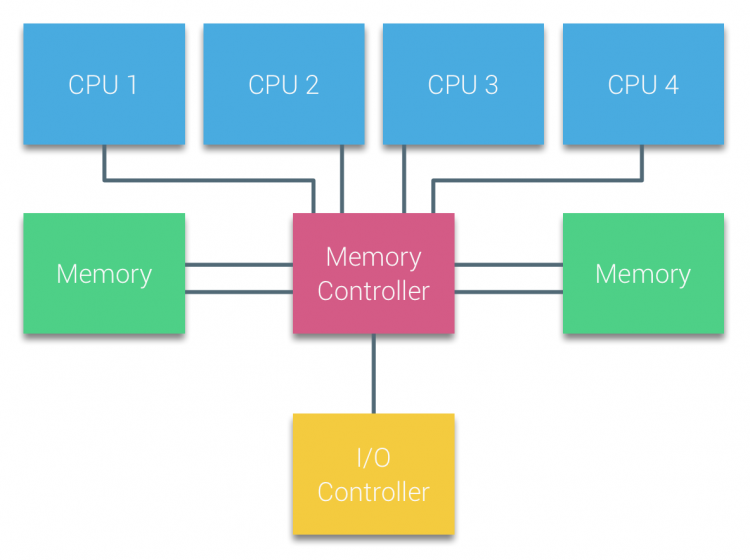
u systémů UMA jsou procesory připojeny přes systémovou sběrnici (Front-Side Bus) k Northbridge. Northbridge obsahuje paměťový řadič a veškerá komunikace Do a z paměti musí projít Northbridge. Řídicí jednotka I / O, odpovědná za správu vstupů/výstupů do všech zařízení, je připojena k Northbridge. Proto musí každý vstup / výstup projít Northbridge, aby dosáhl CPU.
více sběrnic a paměťových kanálů se používá ke zdvojnásobení dostupné šířky pásma a snížení úzkého hrdla Northbridge. Pro zvýšení šířky pásma paměti i některé další systémy připojené externí paměti řadiče Northbridge, zlepšení šířky pásma a podporu více paměti. Nicméně kvůli vnitřní šířce pásma Northbridge a vysílací povaze raných protokolů snoopy cache, UMA byla považována za omezenou škálovatelnost. Při dnešním použití vysokorychlostních flash zařízení, které tlačí stovky tisíc IO za sekundu, měli naprostou pravdu, že tato architektura nebude škálovat pro budoucí pracovní zatížení.
nejednotná Architektura přístupu do paměti
pro zlepšení škálovatelnosti a výkonu jsou v architektuře multiprocesorů sdílené paměti provedeny tři zásadní změny;
- Non-Uniform Memory Access organizace
- Point-to-Point propojení topologie
- Škálovatelná vyrovnávací soudržnost řešení
1: Non-Uniform Memory Access organizace
NUMA se pohybuje od centralizovaného bazén paměti a zavádí topologické vlastnosti. Klasifikací základen umístění paměti podle délky signální cesty od procesoru k paměti lze zabránit úzkým místům latence a šířky pásma. To se provádí přepracováním celého systému procesoru a čipové sady. Architektury NUMA získaly popularitu na konci 90. let, kdy byly použity na superpočítačích SGI, jako je Cray Origin 2000. NUMA pomohl identifikovat umístění paměti, v tomto případě těchto systémů se museli ptát, která oblast paměti, ve které podvozek držel paměťové bity.
v první polovině desetiletí tisíciletí přinesla AMD NUMA do podnikového prostředí, kde vládly systémy UMA. V roce 2003 byla představena rodina AMD Opteron s integrovanými řadiči paměti, přičemž každý procesor vlastní určené paměťové banky. Každý procesor má nyní svůj vlastní paměťový adresový prostor. NUMA optimalizovaný operační systém, jako je ESXi, umožňuje pracovní zátěž spotřebovávat paměť z obou adres paměti a zároveň optimalizovat přístup k místní paměti. Použijme příklad systému se dvěma CPU k objasnění rozdílu mezi místním a vzdáleným přístupem do paměti v rámci jednoho systému.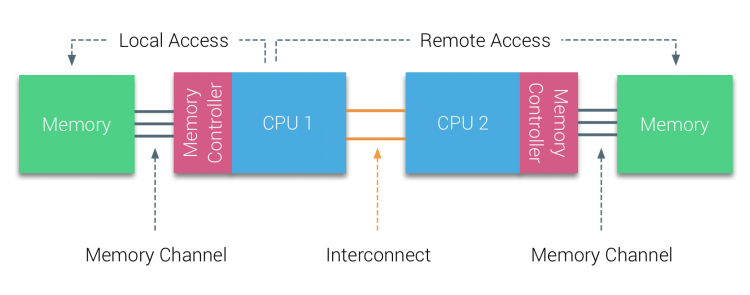
paměť připojená k paměťovému řadiči CPU1 je považována za lokální paměť. Paměť připojená k jiné zásuvce CPU (CPU2) je považována za cizí nebo vzdálenou pro CPU1. Vzdálený přístup do paměti má dodatečnou latenci nad místní přístup do paměti, protože musí procházet propojením (point-to-point link) a připojit se ke vzdálenému paměťovému řadiči. V důsledku různých umístění paměti tento systém zažívá“ nerovnoměrný “ čas přístupu k paměti.
2: Point-to-Point propojení
AMD představila jejich point-to-point spojení HyperTransport u AMD Opteron mikroarchitektury. Společnost Intel se v roce 2007 vzdálila od své duální nezávislé architektury sběrnice zavedením architektury QuickPath do svého návrhu rodiny procesorů Nehalem.
Architektura Nehalem byla významnou změnou designu v mikroarchitektuře Intel a je považována za první skutečnou generaci řady Intel Core. Současná architektura Broadwell je 4. generací značky Intel Core (Intel Xeon E5 v4), poslední odstavec obsahuje více informací o generacích mikroarchitektury. V rámci architektury QuickPath se řadiče paměti přesunuly do CPU a zavedly QuickPath point-to-point Interconnect (QPI) jako datové vazby mezi procesory v systému.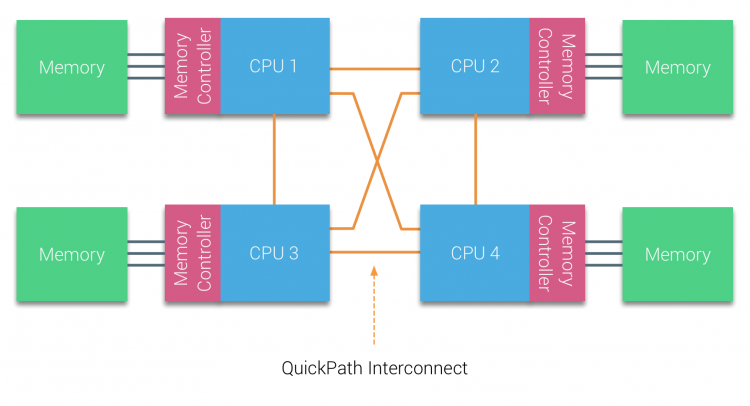
mikroarchitektura Nehalem nejen nahradila starší přední sběrnici, ale reorganizovala celý podsystém do modulárního designu pro serverové CPU. Tento modulární design byl představen jako „Uncore“ a vytváří knihovnu stavebních bloků pro ukládání do mezipaměti a rychlosti propojení. Odstranění sběrnice na přední straně zlepšuje problémy s škálovatelností šířky pásma, přesto je třeba vyřešit komunikaci uvnitř a mezi procesory při řešení obrovského množství kapacity paměti a šířky pásma. Integrovaný řadič paměti i propojení QuickPath jsou součástí Uncore a jsou to Registry specifické pro Model (MSR) ). Připojují se k MSR, která zajišťuje komunikaci uvnitř a mezi procesory. Modularita Uncore také umožňuje Intel nabízet různé QPI rychlost, v době psaní Intel Broadwell-EP mikroarchitektury (2016) nabízí 6.4 Giga-převody za sekundu (GT/s), 8.0 GT/s, 9.6 GT/s. Respektive poskytuje teoretické maximální šířku pásma 25.6 GIGABAJT/s, 32 GB/s a 38.4 GB/s mezi Cpu. Abychom to uvedli v perspektivě, poslední použitá přední sběrnice poskytla šířku pásma platformy 1.6 GT/s nebo 12.8 GB/s. Při zavádění Sandy Bridge Intel rebranded Uncore do systémového agenta, ale termín Uncore je stále používán v aktuální dokumentaci. Více o QuickPath a Uncore najdete v části 2.
3: škálovatelná koherence mezipaměti
každé jádro mělo soukromou cestu k mezipaměti L3. Každá cesta se skládala z tisíce dráty, a můžete si představit, to není měřítko dobře, pokud chcete snížit nanometrů výrobní proces, zatímco také zvýšení jader, které chcete pro přístup do vyrovnávací paměti. Aby bylo možné škálovat, Architektura Sandy Bridge přesunula mezipaměť L3 z Uncore a zavedla škálovatelné propojení ring on-die. To umožnilo společnosti Intel rozdělit a distribuovat mezipaměť L3 ve stejných řezech. To poskytuje vyšší šířku pásma a asociativitu. Každý řez je 2,5 MB a jeden řez je spojen s každým jádrem. Prsten umožňuje každému jádru přístup ke všem dalším řezům. Na obrázku níže je konfigurace matrice s nízkým počtem jader (LCC) Xeon CPU mikroarchitektury Broadwell (v4) (2016).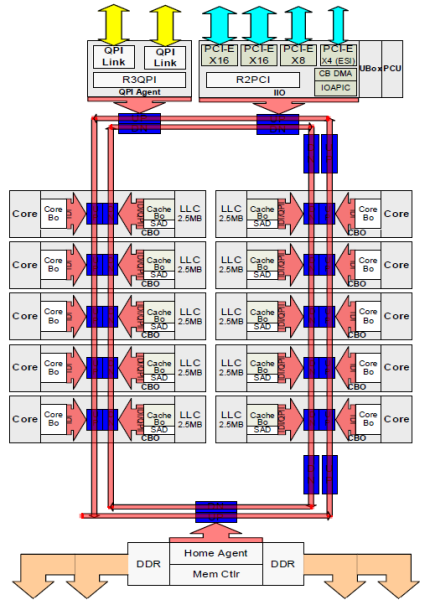
ukládání do mezipaměti architektura vyžaduje snooping protokolu, který zahrnuje jak distribuované místní mezipaměti, stejně jako ostatní procesory v systému k zajištění koherence cache. S přidáním více jader v systému, množství snoop provoz roste, protože každé jádro má svůj vlastní stálý proud cache. To ovlivňuje spotřebu vazeb QPI a mezipaměti poslední úrovně, což vyžaduje neustálý vývoj protokolů Snoop coherency. Hloubkový pohled na Uncore, škálovatelné propojení ring on-Die a důležitost protokolů Snoop pro ukládání do mezipaměti na výkon NUMA budou zahrnuty v části 3.
Non-interleaved povoleno NUMA = SUMA
Fyzické paměti je distribuován po celé desce, nicméně, systém může poskytnout jediný adresový prostor paměti tím, prokládání paměti mezi dvěma NUMA uzly. Tomu se říká prokládání uzlů (nastavení je zahrnuto v části 2). Pokud je povoleno prokládání uzlů, systém se stává dostatečně jednotnou architekturou paměti (SUMA). Místo předávání topologie info a povaze procesorů a paměti v systému operační systém systém porouchá celou paměť rozsah do 4KB adresovatelné regiony a mapy je v round robin módy z každého uzlu. To poskytuje „prokládanou“ strukturu paměti, kde je adresový prostor paměti distribuován napříč uzly. Když ESXi přiřadí paměti pro virtuální stroj přiděluje fyzické paměti se nachází ze dvou různých uzlů při fyzické CPU se nachází v Uzlu 0 potřebuje načíst paměť z Uzlu 1, paměť bude procházet QPI links.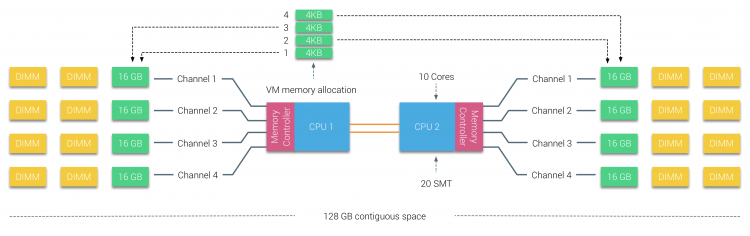
zajímavé je, že systém SUMA poskytuje jednotný čas přístupu k paměti. Pouze ne nejoptimálnější a silně závisí na úrovních sporu v architektuře QPI. Intel Memory Latency Checker byl použit k prokázání rozdílů mezi konfigurací NUMA a SUMA ve stejném systému.
tento test měří latence nečinnosti (v nanosekundách) z každé zásuvky do druhé zásuvky v systému. Latence hlášeny Paměti Uzlu 0 do Zásuvky 0 je lokální přístupu do paměti, přístupu k paměti od zásuvky 0 paměti uzlu 1 je vzdálený přístup do paměti v systému nakonfigurován jako NUMA.
| NUMA | Paměť Uzlu 0 | Paměti Uzlu 1 | – | SUMA | Paměť Uzlu 0 | Paměti Uzlu 1 |
| Zásuvka 0 | 75.7 | 132.0 | – | Zásuvka 0 | 105.5 | 106.4 |
| Zásuvka 1 | 131.9 | 75.8 | – | Zásuvka 1 | 106.0 | 104.6 |
Jak se očekávalo prokládání je ovlivněn neustálé křížení QPI links. Test nečinnosti paměti je nejlepším scénářem, zajímavějším testem je měření načtených latencí. Byla by to špatná investice, kdyby vaše servery ESXi byly na volnoběh, proto můžete předpokládat, že systém ESXi zpracovává data. Měření zatěžovaných latencí poskytuje lepší přehled o tom, jak bude systém fungovat při normálním zatížení. Během zkoušky se zpoždění vstřikování zátěže automaticky mění každé 2 sekundy a na této úrovni se měří šířka pásma i odpovídající latence. Tento test používá 100% čtení provozu.NUMA výsledky testů na levé straně, SUMA výsledky testů na pravé straně.
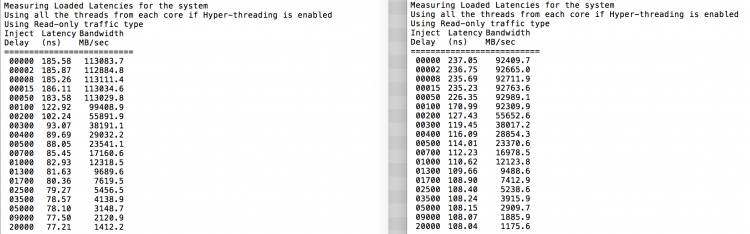
hlášená šířka pásma pro systém SUMA je nižší při zachování vyšší latence než systém nakonfigurovaný jako NUMA. Proto by se mělo zaměřit na optimalizaci velikosti VM, aby se využily NUMA charakteristiky systému.
Nehalem & Core mikroarchitektury přehled
S zavedení mikroarchitektury Nehalem v roce 2008, Intel vzdálil od Netburst architektury. Mikroarchitektura Nehalem představila zákazníkům Intel NUMA. V průběhu let Intel představil nové mikroarchitektury a optimalizace podle svého slavného modelu Tick-Tock. S každým zaškrtnutím dochází k optimalizaci, zmenšení procesní technologie a s každým Takkem je zavedena nová mikroarchitektura. I když Intel poskytuje konzistentní značky, model od roku 2012, lidé mají tendenci, aby na architektuře Intel kódová označení diskutovat CPU tick a tock generace. Dokonce i základní linie EVC uvádí tyto interní kódová jména Intel, v této sérii budou použity názvy značek i kódová jména architektury:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tak | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | Zaškrtněte | 14 nm |
další, Část 2: Architektura Systému
2016 NUMA Hluboký Ponor Série:
Část 0: Úvod NUMA Hluboký Ponor Série
1. Část: Od UMA NUMA
Část 2: Architektura Systému
Část 3: Koherence Cache
Část 4: Lokální Paměti Optimalizace
Část 5: VMkernel ESXi NUMA Konstrukty