po Částech regrese je speciální typ lineární regrese, který vzniká, když jeden řádek nestačí, aby model množiny dat. Po částech regrese rozděluje doménu na potenciálně mnoho „segmentů“ a zapadá do samostatného řádku přes každý z nich. Například, v níže uvedených grafech, jeden řádek není schopen modelovat data, stejně jako po částech regrese se třemi řádky:
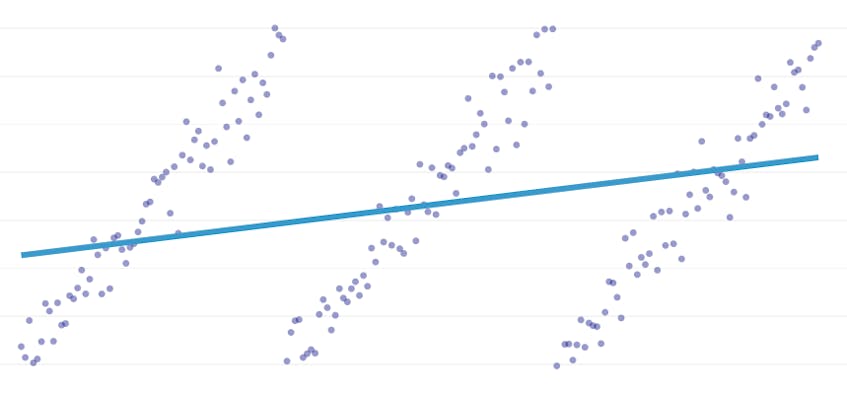
Tento příspěvek představuje Datadog přístup k automatizaci po částech regrese na data časové řady.
Cíle
po Částech regrese může znamenat poněkud odlišné věci v různých kontextech, takže pojďme se na chvíli, aby objasnila, co přesně se snažíme dosáhnout s naší po částech regresní algoritmus.
Automatická detekce zarážek. V klasické statistické literatuře se při manuální regresní analýze často navrhuje po částech regrese, kde je pouhým okem zřejmé, kde jeden lineární trend ustupuje druhému. V takovém případě může člověk určit bod zlomu mezi segmenty po částech, rozdělit datovou sadu a provést lineární regresi na každém segmentu nezávisle. V našich případech použití chceme provádět stovky regresí za sekundu a není možné, aby člověk určil všechny zarážky. Místo toho máme požadavek, aby náš po částech regresní algoritmus identifikoval své vlastní zarážky.
Automatická detekce počtu segmentů. Pokud bychom měli vědět, že datová sada má přesně dva segmenty, mohli bychom se snadno podívat na každý z možných párů segmentů. Nicméně v praxi, když je dána libovolná časová řada, není důvod se domnívat, že musí existovat více než jeden segment nebo méně než 3 nebo 4 nebo 5. Náš algoritmus musí zvolit vhodný počet segmentů, aniž by byl zadán uživatelem.
žádný požadavek na kontinuitu. Některé metody pro regrese po částech generují připojené segmenty, kde koncový bod každého segmentu je počátečním bodem dalšího segmentu. Na náš algoritmus neukládáme žádný takový požadavek.
Problémy
nejviditelnější výzvu k provádění po částech regrese s automatickým zarážku odhalení je velké velikosti řešení, hledání prostoru; brute-force vyhledávání všech možných segmentů je neúnosně drahé. Počet způsobů, jak lze časovou řadu rozdělit na segmenty, je exponenciální v délce časové řady. Zatímco dynamické programování lze použít k procházení tohoto vyhledávacího prostoru mnohem efektivněji než naivní implementace hrubé síly, v praxi je to stále příliš pomalé. K rychlému vyřazení velkých ploch vyhledávacího prostoru bude zapotřebí chamtivý heurista.
jemnější výzvou je, že potřebujeme nějaký způsob, jak porovnat kvalitu jednoho řešení s druhým. Pro naše verze na problém, s neznámých čísel a umístění segmentů, musíme porovnat potenciální řešení s různým počtem segmentů a různé zarážky. Zjistili jsme, že se snažíme vyvážit dva konkurenční cíle:
- minimalizujte chyby. To znamená, aby regresní přímka každého segmentu byla blízko pozorovaných datových bodů.
- použijte nejmenší počet segmentů, které dobře modelují data. Nulovou chybu můžeme vždy získat vytvořením jednoho segmentu pro každý bod (nebo dokonce jednoho segmentu pro každé dva body). Přesto, že by porazit celý smysl dělat regresi; nebudeme učit nic o obecný vztah mezi časovým údajem a jeho přidružené metrické hodnoty, a my jsme nemohli snadno použít výsledek interpolace nebo extrapolace.
naše řešení
používáme následující chamtivý algoritmus pro problém po částech regrese:
- proveďte po částech regresi s n / 2 segmenty, kde n je počet pozorování v časové řadě. Regresní přímka v každém segmentu se hodí pomocí běžné regrese nejmenších čtverců (OLS). Tato počáteční po částech regrese bude mít téměř žádnou chybu, ale to bude vážně overfit datovou sadu.
- Iterativně, dokud je tam jen jeden segment:
- Pro všechny dvojice sousedních segmentů, zhodnotit, zvýšení celkové chyba, která by dojít, pokud dva segmenty byly spojeny, jejich dvě regresní přímky být nahrazeny jediným regresní přímky.
- spojte dohromady pár segmentů, které by vedly k nejmenšímu nárůstu chyb.
- pokud provedení tohoto sloučení splňuje naše kritéria zastavení (definovaná níže), pak jsme možná zašli příliš daleko a sloučili dva segmenty, které by měly zůstat oddělené. Pokud tomu tak je, zapamatujte si stav segmentů před sloučením této iterace.
- Pokud není sloučení mělo za následek připomenout, státní segmentů v (2c) výše, pak nejlepším řešením je jeden velký segment. V opačném případě je nejlepším řešením stav posledního segmentu, který má být zapamatován v (2c).
kritéria zastavení
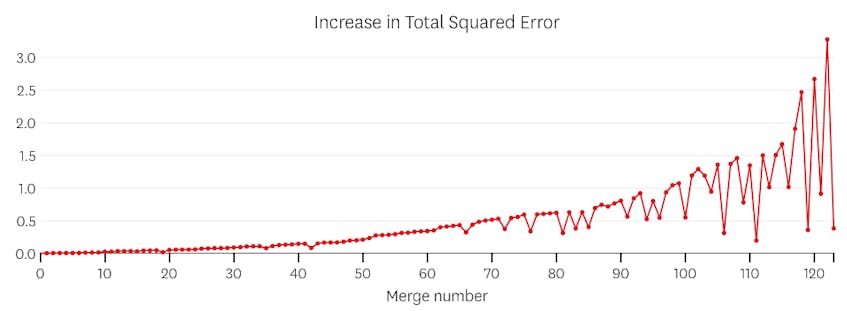
sloučení považujeme za potenciální bod zastavení, pokud zvýší celkový součet chyb na druhou o více než jakékoli předchozí sloučení. Aby se zabránilo zastavení příliš brzy v případech, kdy by měl být pouze jeden segment, nebudeme uvažovat o sloučení se být potenciální místa na zastavení, pokud to má za následek zvýšení celkové chyby, která je méně než 3% z celkového chyba regrese s jednou segmentu. (3% je libovolná prahová hodnota, ale zjistili jsme, že v praxi funguje dobře.) Níže uvádíme několik příkladů, které ukazují, proč tato kritéria zastavení fungují.
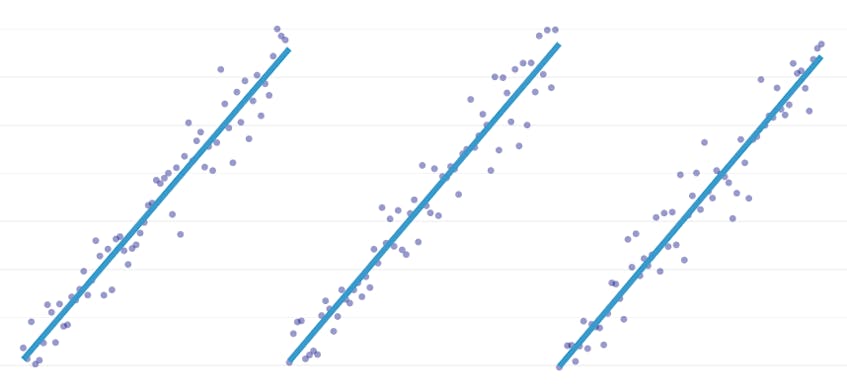
nejprve se podívejme na datovou sadu, která byla vygenerována přidáním normálně distribuovaného šumu k bodům podél jedné čáry. Algoritmus správně zapadá pouze do jednoho segmentu prostřednictvím této datové sady.
V tomto případě, není sloučení, kdy se zvyšuje celkový součet čtverečkovaných chyb o více než 3%. Proto žádné sloučení není považováno za adekvátní bod zastavení a konečný stav použijeme po provedení všech fúzí. V grafu níže vidíme, že později splývá mají tendenci zavádět více chyb než dříve (což dává smysl, protože každý dopad více bodů), ale zvýšení chyby, ale postupně se zvyšuje, jak více segmenty jsou sloučeny.
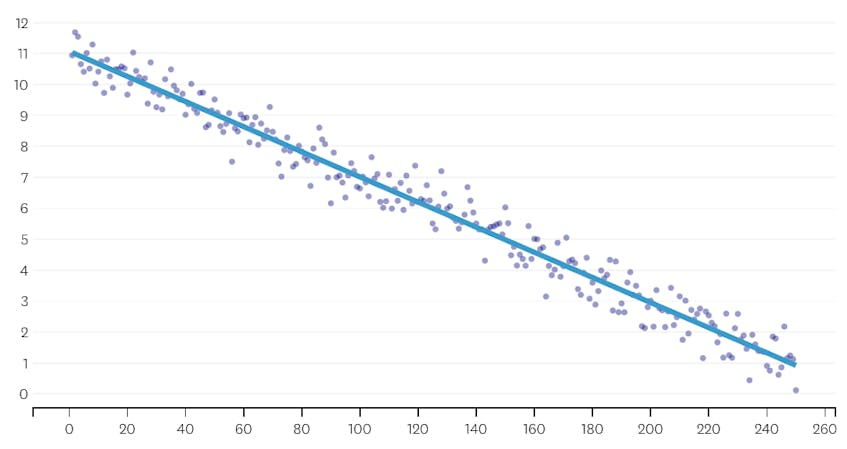
za druhé, podívejme se na příklad, kde je v datové sadě sedm odlišných segmentů.
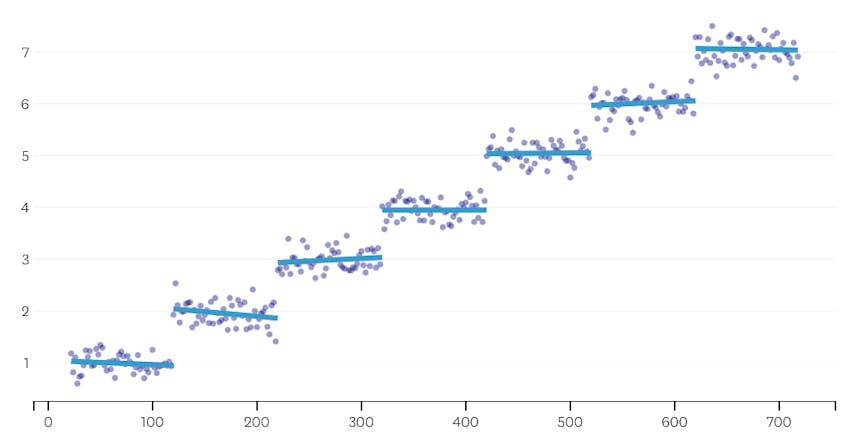
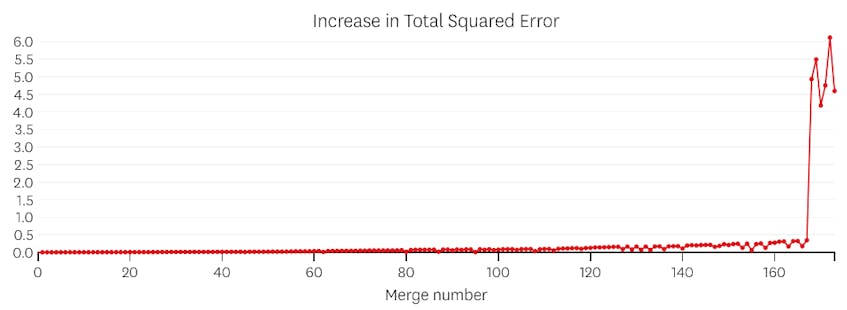
V tomto případě, když se podíváme na děj chyby představen každý sloučit, vidíme, že posledních šest splývá představil mnohem více chyb, než jakýkoli předchozí spojuje. Proto, náš algoritmus pamatoval stav segmenty z před 6-k-poslední sloučit a použít to jako konečné řešení.
kód
V Datadog/po částech Github repo, zjistíte, že naše Python implementace algoritmu. Funkce piecewise() je místo, kde dochází k těžkému zvedání; vzhledem k sadě dat vrátí koeficienty umístění a regrese pro každý z namontovaných segmentů.
součástí podstaty je také plot_data_with_regression() – funkce obalu pro rychlé a snadné Vykreslování. Rychlý příklad toho, jak by to mohlo být:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)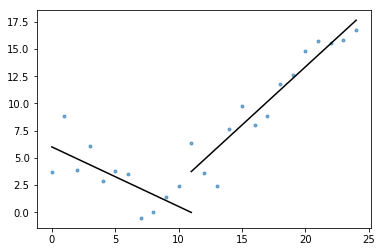
Zatímco tato implementace používá OLS lineární regrese, stejný rámec může být přizpůsoben řešit související problémy. Nahrazením kvadratické chyby absolutní chybou nebo Huberovou ztrátou může být regrese robustní. Nebo lze funkci kroku přizpůsobit přiřazením každému segmentu konstantní hodnotu rovnající se průměru pozorování v jeho doméně.