Uniform memory access (numa) on nykyisissä moniprosessointijärjestelmissä käytetty jaetun muistin arkkitehtuuri. Jokaiselle suorittimelle on osoitettu oma paikallinen muisti ja se voi käyttää muistia järjestelmän muilta Suorittimilta. Paikallinen muistiyhteys tarjoaa alhaisen latenssin-suuren kaistanleveyden suorituskyvyn. Toisen suorittimen omistamaa muistia käytettäessä on korkeampi latenssi ja pienempi kaistanleveyden suorituskyky. Nykyaikaiset sovellukset ja käyttöjärjestelmät, kuten ESXi, tukevat NUMAA oletusarvoisesti, mutta parhaan suorituskyvyn saavuttamiseksi virtuaalikoneen konfigurointi tulisi tehdä NUMA-arkkitehtuuria silmällä pitäen. Jos suunniteltu väärin, kyseiselle virtuaalikoneelle tai pahimmassa tapauksessa kaikille ESXi-isännällä toimiville VMs-laitteille tapahtuu merkityksetöntä käyttäytymistä tai yleistä suorituskyvyn heikkenemistä.
tämä sarja pyrkii tarjoamaan tietoa SUORITINARKKITEHTUURISTA, muistialajärjestelmästä sekä ESXi-suorittimesta ja muistin ajoituksesta. Voit luoda suorituskykyisen alustan, joka luo perustan korkeammille palveluille ja suuremmille konsolidointisuhteille. Ennen kuin saavumme nykyaikaisiin laskenta-arkkitehtuureihin, on hyödyllistä tarkastella jaetun muistin moniprosessoriarkkitehtuurien historiaa ymmärtääksemme, miksi käytämme NUMA-järjestelmiä tänään.
- jaetun muistin moniprosessoriarkkitehtuurin kehitys viime vuosikymmeninä
- välimuistin snoop-protokollien käyttöönotto
- Uniform Memory Access Architecture
- Uniform Memory Access Architecture
- 1: epäyhtenäinen Muistiyhteysorganisaatio
- 2: Point-to-Point interconnect
- 3: skaalautuva välimuistin koherenssi
- ei-interleaved enabled numa = SUMA
- Nehalem & Core microarchitecture overview
jaetun muistin moniprosessoriarkkitehtuurin kehitys viime vuosikymmeninä
näyttää siltä, että Uniform Memory Access-niminen arkkitehtuuri sopisi paremmin suunniteltaessa johdonmukaista matalan latenssin, suuren kaistanleveyden alustaa. Silti nykyaikaiset järjestelmäarkkitehtuurit rajoittavat sitä olemasta todella yhtenäinen. Ymmärtääksemme syyn tähän meidän on palattava historiaan tunnistaaksemme rinnakkaislaskennan Keskeiset ajurit.
relaatiotietokantojen käyttöönoton myötä 1970-luvun alussa yleistyi tarve järjestelmille, jotka voisivat palvella useita samanaikaisia käyttäjien toimintoja ja liiallista tiedon tuottamista. Uniprosessorin tehokkuudesta huolimatta moniprosessorijärjestelmät olivat paremmin varustettuja käsittelemään tätä työmäärää. Kustannustehokas järjestelmä tuli tutkimuksen keskiöön jaetusta muistiosoiteavaruudesta. Jo varhain kannatettiin crossbar-kytkintä käyttäviä järjestelmiä, mutta tämä suunnittelun monimutkaisuus skaalautui prosessorien lisääntymisen myötä, mikä teki väyläpohjaisesta järjestelmästä houkuttelevamman. Väyläjärjestelmän prosessorit pääsevät käyttämään koko muistitilaa lähettämällä pyyntöjä väylälle, mikä on erittäin kustannustehokas tapa käyttää käytettävissä olevaa muistia mahdollisimman optimaalisesti.
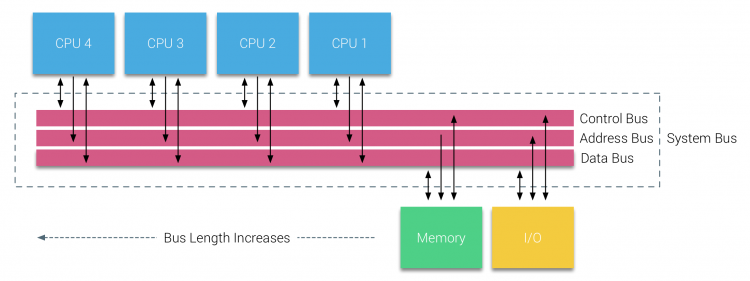
väyläpohjaisissa järjestelmissä on kuitenkin omat skaalautuvuusongelmansa. Tärkein ongelma on rajallinen määrä kaistanleveyttä, tämä rajoittaa useita prosessoreita linja mahtuu. Suorittimien lisääminen järjestelmään tuo kaksi suurta huolenaihetta:
- käytettävissä oleva kaistanleveys solmua kohti pienenee, kun jokainen suoritin lisätään.
- väylän pituus kasvaa, kun prosessoreita lisätään, jolloin latenssi kasvaa.
suorittimen suorituskyvyn kasvu ja erityisesti nopeuskuilu suorittimen ja muistin suorituskyvyn välillä oli ja on edelleen musertava moniprosessoreille. Koska muistin kuilun prosessorin ja muistin välillä odotettiin kasvavan, panostettiin paljon tehokkaiden strategioiden kehittämiseen muistijärjestelmien hallitsemiseksi. Yksi näistä strategioista oli muistivälimuistin lisääminen, joka toi mukanaan lukuisia haasteita. Näiden haasteiden ratkaiseminen on edelleen pääpaino tänään suorittimen suunnitteluryhmien, paljon tutkimusta tehdään välimuistin rakenteita ja kehittyneitä algoritmeja välttää välimuistin huteja.
välimuistin snoop-protokollien käyttöönotto
välimuistin liittäminen kuhunkin suorittimeen lisää suorituskykyä monin tavoin. Muistin tuominen lähemmäs suoritinta vähentää muistin keskimääräistä käyttöaikaa ja samalla vähentää muistiväylän kaistanleveyskuormaa. Haasteena välimuistin lisäämisessä jokaiselle suorittimelle jaetussa muistiarkkitehtuurissa on se, että se mahdollistaa useita kopioita muistilohkosta. Tätä kutsutaan välimuistin koherenssiongelmaksi. Tämän ratkaisemiseksi keksittiin välimuistin snoop-protokollat, joilla yritettiin luoda malli, joka tarjosi oikeat tiedot, mutta ei yritetty syödä kaikkea väylän kaistanleveyttä. Suosituin protokolla, write invalidate, poistaa kaikki muut kopiot tiedoista ennen paikallisen välimuistin kirjoittamista. Jos Muut Prosessorit myöhemmin lukevat näitä tietoja, ne havaitsevat välimuistin puuttumisen paikalliseen välimuistiin ja se huolletaan toisen suorittimen välimuistista, joka sisältää viimeksi muutetut tiedot. Tämä malli säästi paljon väylän kaistanleveyttä ja mahdollisti yhtenäisten Muistiyhteysjärjestelmien syntymisen 1990-luvun alussa. nykyaikaiset välimuistin koherenssiprotokollat käsitellään tarkemmin osassa 3.
Uniform Memory Access Architecture
Väyläpohjaisten moniprosessoreiden suorittimia, jotka kokevat saman uniform-käyttöajan mille tahansa järjestelmän muistimoduulille, kutsutaan usein uniform Memory Access – järjestelmiksi (UMA) tai Symmetrisiksi Moniprosessoreiksi (SMPS).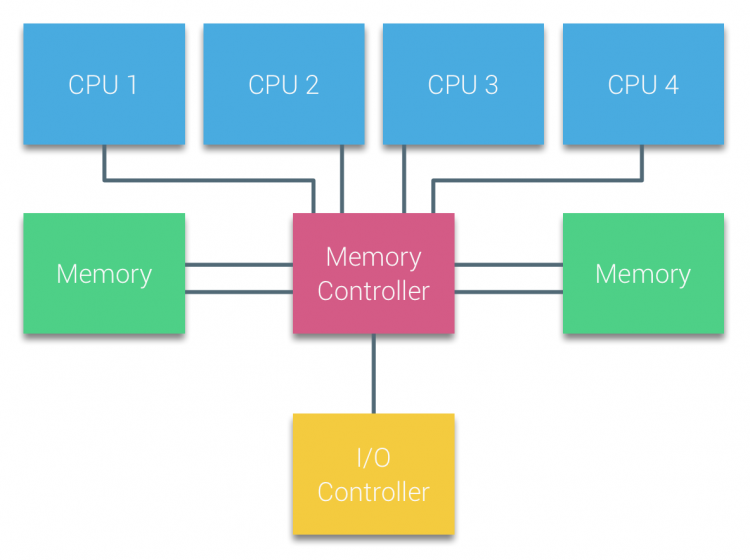
UMA-järjestelmissä suorittimet on kytketty järjestelmäväylän (Etuväylä) kautta Northbridgeen. Northbridge sisältää muistiohjaimen, ja kaiken muistille tulevan ja sieltä lähtevän viestinnän on kuljettava Northbridgen kautta. I/O-ohjain, joka vastaa I / O: n hallinnoinnista kaikissa laitteissa, on kytketty Northbridgeen. Siksi jokaisen I / O: n on kuljettava Northbridgen läpi päästäkseen suorittimeen.
useita väyliä ja muistikanavia käytetään kaksinkertaistamaan käytettävissä oleva kaistanleveys ja pienentämään Northbridgen pullonkaulaa. Lisätäkseen muistin kaistanleveyttä entisestään jotkin järjestelmät yhdistivät ulkoisia muistiohjaimia Northbridgeen, parantaen kaistanleveyttä ja lisätuen muistia. Northbridgen sisäisen kaistanleveyden ja varhaisten snoopy-välimuistiprotokollien lähetystoiminnan luonteen vuoksi UMA: lla katsottiin kuitenkin olevan rajallinen skaalautuvuus. Kun nykyään käytetään nopeita salamalaitteita, jotka työntävät satoja tuhansia IO: ta sekunnissa, he olivat täysin oikeassa siinä, että tämä arkkitehtuuri ei skaalautuisi tulevia työmääriä varten.
Uniform Memory Access Architecture
skaalautuvuuden ja suorituskyvyn parantamiseksi jaetun muistin moniprosessoriarkkitehtuuriin tehdään kolme kriittistä muutosta;
- Uniform Memory Access organization
- Point-to-Point interconnect topology
- Scalable cache coherence solutions
1: epäyhtenäinen Muistiyhteysorganisaatio
NUMA siirtyy pois keskitetystä muistipoolista ja esittelee topologisia ominaisuuksia. Luokittelemalla muistin sijaintipohjat signaalitien pituuteen prosessorista muistiin voidaan välttää latenssi-ja kaistanleveyden pullonkaulat. Tämä tapahtuu uudistamalla koko suoritin – ja piirisarjajärjestelmä. NUMA-arkkitehtuurit saavuttivat suosiota 90-luvun lopulla, kun sitä käytettiin SGI-supertietokoneissa, kuten Cray Origin 2000: ssa. NUMA auttoi tunnistamaan muistin sijainnin, tässä tapauksessa nämä järjestelmät, he joutuivat miettimään, mikä muistialue, jossa alusta piti muistibittejä.
vuosituhannen vuosikymmenen alkupuoliskolla AMD toi Numan yritysmaisemaan, jossa UMA systems hallitsi ylivoimaa. Vuonna 2003 esiteltiin AMD Opteron-perhe, jossa on integroidut muistiohjaimet, joissa jokainen suoritin omistaa nimetyt muistipankit. Jokaisella suorittimella on nyt oma muistiosoiteavaruutensa. Numa-optimoitu käyttöjärjestelmä, kuten ESXi, sallii työmäärän kuluttaa muistia molemmista muistiosoitteista optimoiden samalla paikallisen muistin käytön. Käytetään esimerkkiä kahden suorittimen järjestelmästä selventämään eroa paikallisen ja etämuistin välillä yhden järjestelmän sisällä.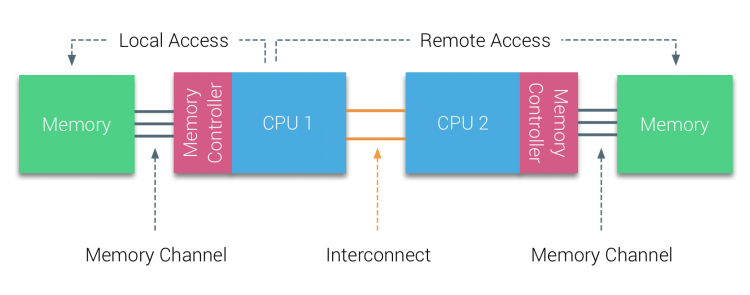
CPU1: n muistiohjaimeen liitettyä muistia pidetään paikallismuistina. Toiseen SUORITINPISTORASIAAN (CPU2)liitettyä muistia pidetään CPU1: lle vieraana tai etänä. Remote memory access on ylimääräisiä latenssi yläpuolella paikallisen muistin access, koska se on läpäistävä interconnect (point-to-point link) ja yhteyden etämuistiohjain. Erilaisten muistipaikkojen seurauksena tämä järjestelmä kokee” epäyhtenäisen ” muistinkäyttöajan.
2: Point-to-Point interconnect
AMD esitteli pisteyhteyden Hypertransporttinsa AMD Opteron-mikroarkkitehtuurilla. Intel siirtyi vuonna 2007 eroon kahdesta itsenäisestä väyläarkkitehtuuristaan esittelemällä QuickPath-arkkitehtuurin Nehalem-prosessoriperheen suunnittelussa.
Nehalem-arkkitehtuuri oli merkittävä suunnittelumuutos Intelin mikroarkkitehtuurissa ja sitä pidetään Intel Core-sarjan ensimmäisenä todellisena sukupolvena. Nykyinen Broadwell-arkkitehtuuri on Intel Core-brändin 4. sukupolvi (Intel Xeon E5 v4), viimeinen kappale sisältää lisätietoa mikroarkkitehtuurisukupolvista. QuickPath-arkkitehtuurissa muistiohjaimet siirtyivät suorittimelle ja ottivat käyttöön QuickPath point-to-point Interconnect (QPI)-järjestelmän suorittimien välisinä datalinkkeinä.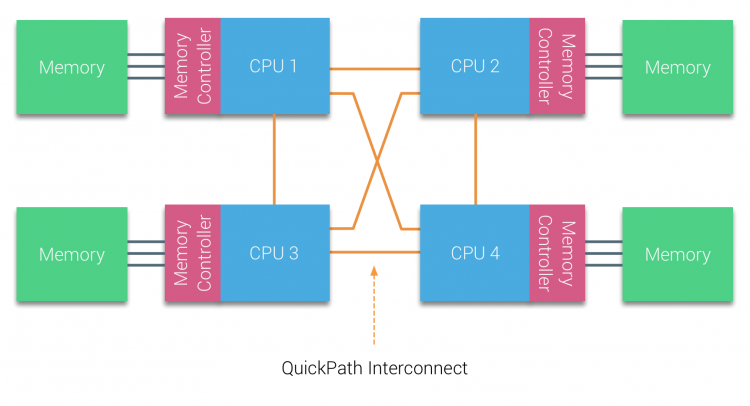
Nehalemin mikroarkkitehtuuri ei ainoastaan korvannut vanhaa etuväylää, vaan koko alijärjestelmä uudelleenorganisoitiin modulaariseksi rakenteeksi palvelinyksikölle. Tämä modulaarinen rakenne otettiin käyttöön nimellä ”Uncore” ja luo rakennuspalikka kirjasto välimuistiin ja yhdistää nopeuksia. Etuväylän poistaminen parantaa kaistanleveyden skaalautuvuusongelmia, mutta prosessorien sisäinen ja välinen viestintä on ratkaistava, kun käsitellään valtavia määriä muistikapasiteettia ja kaistanleveyttä. Sekä integroitu muistiohjain että QuickPath-liitäntälaitteet ovat osa Uncore-järjestelmää ja ovat mallikohtaisia rekistereitä (MSR). Ne kytkeytyvät MSR: ään, joka tarjoaa prosessorien sisäisen ja välisen viestinnän. Uncoren modulaarisuus mahdollistaa myös Intelin eri QPI-nopeuksien tarjoamisen, sillä Intel Broadwell-EP microarchitecture (2016) tarjoaa suorittimien välillä 6,4 gigan siirtoja sekunnissa (GT/s), 8,0 GT/S ja 9,6 GT/s. vastaavasti teoreettiset maksimikaistanleveydet ovat 25,6 GB/s, 32 GB/s ja 38,4 GB/s. Viimeksi käytetty etuväylä tarjosi 1,6 GT/s tai 12,8 Gt/s Alustan kaistanleveyttä. Kun otetaan käyttöön Sandy Bridge Intel uudelleenbrändäsi Uncore osaksi järjestelmän agentti, silti termi Uncore käytetään edelleen nykyisessä dokumentaatiossa. Lisää Quickpathista ja Uncoresta löytyy osasta 2.
3: skaalautuva välimuistin koherenssi
jokaisella ytimellä oli yksityinen polku L3-välimuistiin. Jokainen polku koostui tuhannesta johtimesta ja voit kuvitella, että tämä ei skaalaudu hyvin, jos haluat vähentää nanometrin valmistusprosessia ja samalla lisätä välimuistiin haluavia ytimiä. Pystyäkseen skaalaamaan Sandy Bridge-arkkitehtuuri siirsi L3-välimuistin pois Uncoresta ja otti käyttöön skaalautuvan ring on-die Interconnect-järjestelmän. Tämä mahdollisti Intelin jakaa ja jakaa L3-välimuistin yhtä suurina viipaleina. Tämä tarjoaa suuremman kaistanleveyden ja assosiatiivisuuden. Jokainen siivu on 2,5 MB ja yksi siivu liittyy jokaiseen ytimeen. Renkaan avulla jokainen ydin käyttää joka toinen pala samoin. Kuvassa alla on Broadwell Microarchitecture (v4) (2016) – mikroarkkitehtuurin (Low Core Count) Xeon-suorittimen die-kokoonpano.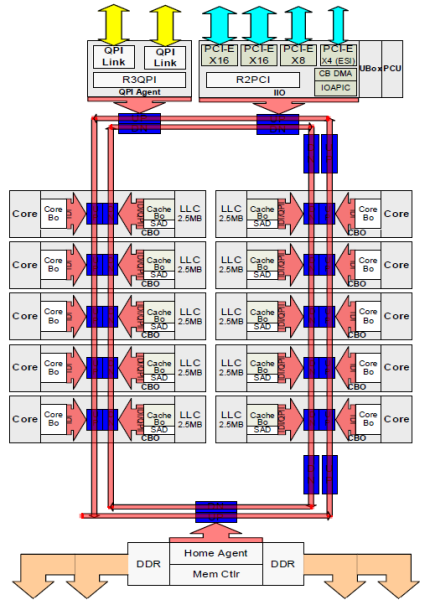
tämä välimuistiarkkitehtuuri vaatii nuuskimisprotokollan, joka sisältää sekä hajautetun paikallisen välimuistin että järjestelmän Muut Prosessorit välimuistin koherenssin varmistamiseksi. Kun järjestelmään lisätään lisää ytimiä, snoop-liikenteen määrä kasvaa, koska jokaisella ytimellä on oma tasainen virta välimuistin huteja. Tämä vaikuttaa QPI-linkkien ja viimeisen tason välimuistien kulutukseen, mikä edellyttää Snoop-koherenssiprotokollien jatkuvaa kehittämistä. Syvällinen näkymä Uncore, skaalautuva rengas on-Die Interconnect ja merkitys välimuistin snoop protokollia NUMA suorituskykyä sisällytetään osaan 3.
ei-interleaved enabled numa = SUMA
fyysinen muisti jakautuu emolevylle, mutta järjestelmä voi tarjota yhden muistiosoiteavaruuden sijoittamalla muistin kahden NUMA-solmun väliin. Tätä kutsutaan Node-interleaving (asetus on katettu osassa 2). Kun solmujen lomitus on käytössä, järjestelmästä tulee riittävän yhtenäinen muistiarkkitehtuuri (SUMA). Sen sijaan, että järjestelmän suorittimien ja muistin topologiatiedot ja luonne välitettäisiin käyttöjärjestelmälle, järjestelmä pilkkoo koko muistialueen 4KB: n osoitteellisiin alueisiin ja kartoittaa ne pyöreällä Robinilla jokaisesta solmusta. Näin saadaan ”interleaved” – muistirakenne, jossa muistiosoiteavaruus jaetaan solmujen kesken. Kun ESXi määrittää muistin virtual machine se jakaa fyysisen muistin sijaitsee kahdesta eri solmuista kun fyysinen CPU sijaitsee solmussa 0 täytyy hakea muistia solmu 1, muisti kulkee QPI linkkejä.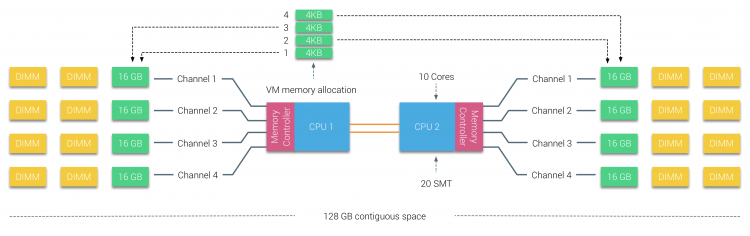
mielenkiintoista on se, että SUMA-järjestelmä tarjoaa yhtenäisen muistinkäyttöajan. Vain ei kaikkein optimaalinen ja riippuu voimakkaasti väitteen tasolla QPI arkkitehtuuri. Intel Memory Latency Checkeriä käytettiin osoittamaan numa-ja SUMA-konfiguraatioiden erot samassa järjestelmässä.
tämä testi mittaa tyhjäkäyntiviiveitä (nanosekunteina) järjestelmän jokaisesta pistorasiasta toiseen pistorasiaan. Muistisolmun 0 latenssi Socket 0: lla on paikallinen muistiyhteys, muistisolmun 1 socket 0: n muistiyhteys on etämuistiyhteys numa: ksi määritetyssä järjestelmässä.
| NUMA | Muistisolmu 0 | Muistisolmu 1 | – | SUMA | Muistisolmu 0 | Muistisolmu 1 |
| Socket 0 | 75.7 | 132.0 | – | Socket 0 | 105.5 | 106.4 |
| Socket 1 | 131.9 | 75.8 | – | Socket 1 | 106.0 | 104.6 |
odotetusti interleaving vaikuttaa jatkuva läpi QPI linkkejä. Tyhjäkäyntimuistitesti on parhaassa tapauksessa, kiinnostavampi testi mittaa ladattuja latensseja. Olisi ollut huono sijoitus, jos ESXi-palvelimet ovat tyhjäkäynnillä, joten voit olettaa, että ESXi-järjestelmä käsittelee tietoja. Latenssien mittaaminen antaa paremman käsityksen siitä, miten järjestelmä toimii normaalissa kuormituksessa. Testin aikana kuorman injektioviiveet vaihdetaan automaattisesti 2 sekunnin välein ja sekä kaistanleveys että vastaava latenssi mitataan kyseisellä tasolla. Tämä testi käyttää 100% lukuliikennettä.NUMA testitulokset vasemmalla, SUMA testitulokset oikealla.
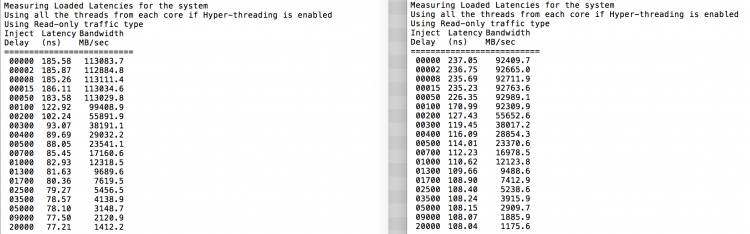
SUMA-järjestelmän ilmoitettu kaistanleveys on pienempi, mutta latenssi on suurempi kuin numa-järjestelmällä. Siksi painopiste tulisi olla optimoimalla VM koko hyödyntää numa ominaisuudet järjestelmän.
Nehalem & Core microarchitecture overview
Nehalemin mikroarkkitehtuurin käyttöönoton myötä vuonna 2008 Intel siirtyi pois Netburst-arkkitehtuurista. Nehalem-mikroarkkitehtuuri esitteli Intelin asiakkaita NUMALLE. Vuosien varrella Intel esitteli uusia mikroarkkitehtuureja ja optimointeja kuuluisan Tick-Tock-mallinsa mukaan. Jokaisella rastilla optimointi tapahtuu, kutistuu prosessitekniikka ja jokaisella Tockilla otetaan käyttöön uusi mikroarkkitehtuuri. Vaikka Intel tarjoaa johdonmukainen brändäys malli vuodesta 2012, ihmiset taipumus Intel arkkitehtuurin koodinimet keskustella CPU tick ja tock sukupolvet. Jopa EVC-pohjalinjat luettelevat nämä sisäiset Intel-koodinimet, sekä brändäys-että arkkitehtuurikoodenimet käytetään koko tässä sarjassa:
| Microarchitecture DP servers | Branding | Year | Cores | LLC (MB) | QPI Speed (GT/s) | Memory Frequency | Architectural change | Fabrication Process |
| Nehalem | x55xx | 10-2008 | 4 | 8 | 6.4 | 3xDDR3-1333 | Tock | 45nm |
| Westmere | x56xx | 01-2010 | 6 | 12 | 6.4 | 3xDDR3-1333 | Tick | 32nm |
| Sandy Bridge | E5-26xx v1 | 03-2012 | 8 | 20 | 8.0 | 4xDDR3-1600 | Tock | 32nm |
| Ivy Bridge | E5-26xx v2 | 09-2013 | 12 | 30 | 8.0 | 4xDDR3-1866 | Tick | 22 nm |
| Haswell | E5-26xx v3 | 09-2014 | 18 | 45 | 9.6 | 4xDDR3-2133 | Tock | 22nm |
| Broadwell | E5-26xx v4 | 03-2016 | 22 | 55 | 9.6 | 4xDDR3-2400 | rasti | 14 nm |
Up next, Part 2: System Architecture
the 2016 numa Deep Dive Series:
Part 0: Introduction NUMA Deep Dive Series
Part 1: from UMA to NUMA
Part 2: System Architecture
Part 3: Cache Coherency
Part 4: Local Memory Optimization
Part 5: ESXi VMkernel NUMA Constructs