paloittain regressio on erityinen lineaarinen regressio, joka syntyy, kun yksi rivi ei riitä mallintamaan tietojoukkoa. Paloittain regressio rikkoo verkkotunnuksen mahdollisesti moniin ”segmentteihin” ja sopii erilliseen linjaan jokaisen läpi. Esimerkiksi alla olevissa kaavioissa yksi rivi ei pysty mallintamaan tietoja yhtä hyvin kuin paloittain regressio, jossa on kolme riviä:
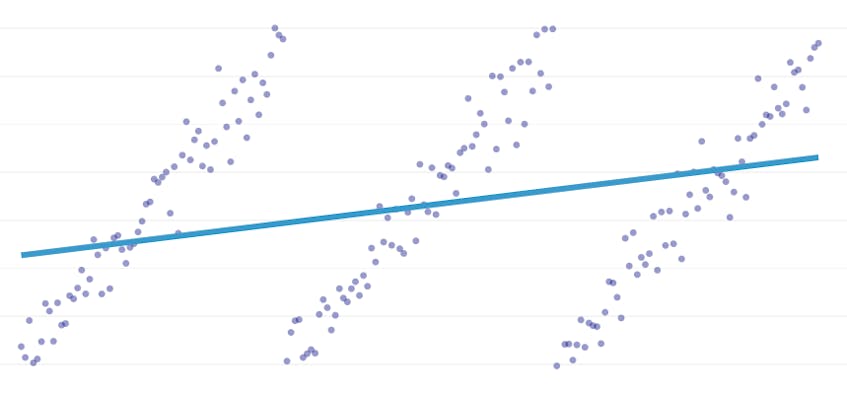
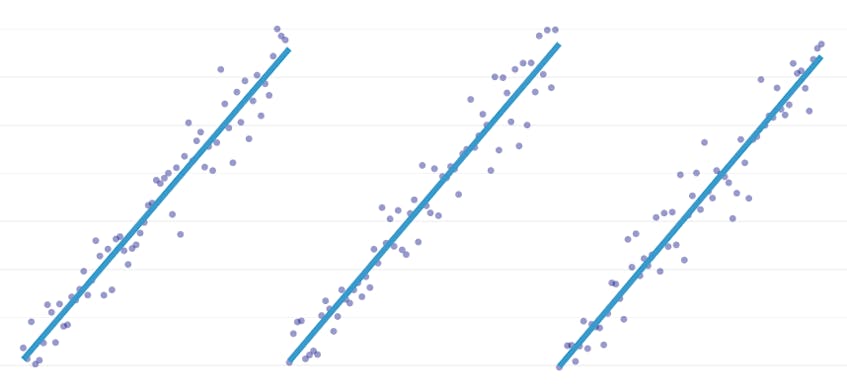
tämä viesti esittelee Datadogin lähestymistapa automatisoida paloittain regressio aikasarja tiedot.
tavoitteet
paloittain regressio voi tarkoittaa hieman eri asioita eri yhteyksissä, joten selvennetäänpä hetki, mitä yritämme saavuttaa paloittain regressioalgoritmillamme.
Automaattinen keskeytyspisteiden havaitseminen. Klassisessa tilastokirjallisuudessa paloittain tapahtuvaa regressiota ehdotetaan usein manuaalisen regressioanalyysin aikana, jossa on ilmeistä paljain silmin, kun yksi lineaarinen suuntaus väistyy toisen tieltä. Siinä tapauksessa ihminen voi määrittää katkeamispisteen paloittain segmenttien välillä, jakaa aineiston ja suorittaa lineaarisen regression kullekin segmentille itsenäisesti. Meidän käyttö tapauksissa, haluamme tehdä satoja regressioita sekunnissa, ja se ei ole mahdollista, että ihminen määrittää kaikki keskeytyspisteet. Sen sijaan meillä on vaatimus, että paloittain regressioalgoritmimme tunnistaa omat keskeytyspisteensä.
automatisoitu segmenttiluvun tunnistus. Jos olisimme tietää, että tietojoukko on täsmälleen kaksi segmenttiä, voisimme helposti tarkastella kunkin mahdollisen paria segmenttien. Kuitenkin käytännössä, kun annetaan mielivaltainen aikasarja, ei ole mitään syytä uskoa, että on oltava enemmän kuin yksi segmentti tai vähemmän kuin 3, 4 tai 5. Algoritmimme on valittava sopiva määrä segmenttejä ilman, että se on käyttäjän määrittelemä.
ei jatkuvuusvaatimusta. Jotkut menetelmät paloittain regressioita tuottaa kytketty segmenttien, jossa kunkin segmentin päätepiste on seuraavan segmentin alkupiste. Emme aseta tällaista vaatimusta meidän algoritmi.
haasteet
ilmeisin haaste paloittain tapahtuvan regression toteuttamiselle automaattisella keskeytyspisteiden tunnistuksella on ratkaisun hakuavaruuden suuri koko; kaikkien mahdollisten segmenttien raa ’ an voiman haku on kohtuuttoman kallista. Aikasarjan pituudessa on eksponentiaalinen määrä tapoja, joilla aikasarja voidaan jakaa segmentteihin. Vaikka dynaamisella ohjelmoinnilla voidaan kulkea tämän hakuavaruuden läpi paljon tehokkaammin kuin naiivilla raa ’ alla voimalla toteutetulla toteutuksella, on se silti käytännössä liian hidas. Ahnetta heuristia tarvitaan nopeasti hävittämään suuria alueita etsintäalueesta.
hienovaraisempi haaste on, että tarvitsemme jonkinlaisen tavan verrata yhden ratkaisun laatua toiseen. Meidän versio ongelmasta, jossa Tuntematon numerot ja sijainnit segmenttien, meidän täytyy vertailla mahdollisia ratkaisuja eri määrä segmenttien ja eri keskeytyspisteitä. Huomaamme yrittävämme tasapainottaa kahta kilpailevaa tavoitetta:
- minimoi virheet. Toisin sanoen tee kunkin janan regressiolinja lähelle havaittuja datapisteitä.
- käytetään vähiten dataa hyvin mallintavia segmenttejä. Voisimme aina saada nolla virhe luomalla yhden segmentin jokaisen pisteen (tai jopa yhden segmentin jokaista kahta pistettä). Se kuitenkin tekisi tyhjäksi regression tekemisen koko Pointin; emme oppisi mitään aikaleiman ja siihen liittyvän metrisen arvon välisestä yleisestä suhteesta, emmekä voisi helposti käyttää tulosta interpolointiin tai ekstrapolointiin.
our solution
we use the following ahne algorithm for the piecewise regression problem:
- tee paloittain regressio, jossa N / 2 segmenttiä, jossa n on aikasarjan havaintojen lukumäärä. Kunkin segmentin regressiolinja sovitetaan tavallisen pienimmän neliösumman (OLS) regression avulla. Tämä alkuperäinen paloittain regressio on tuskin mitään virhettä,mutta se vakavasti ylitetä tiedot.
- iteratiivisesti, kunnes on vain yksi Jana:
- kaikkien naapurisegmenttien parien osalta, arvioidaan kokonaisvirheen kasvu, joka aiheutuisi, jos kaksi segmenttiä yhdistettäisiin siten, että niiden kaksi regressioriviä korvattaisiin yhdellä regressiorivillä.
- yhdistä yhteen se segmenttipari, joka johtaisi pienimpään virheiden lisääntymiseen.
- jos tämän yhdistämisen suorittaminen täyttää jäljempänä määritellyt pysähtymiskriteerit, olemme saattaneet mennä liian pitkälle ja yhdistää kaksi segmenttiä, joiden pitäisi pysyä erillisinä. Jos näin on, muista segmenttien tila ennen tämän iteraation yhdistämistä.
- jos yhdistäminen ei johtanut muistaa tilan segmenttien (2C) edellä, niin paras ratkaisu on yksi suuri segmentti. Muussa tapauksessa viimeinen segmentin tila, joka muistetaan (2c), on paras ratkaisu.
Pysähtymiskriteerit
yhdistämistä pidetään mahdollisena pysähtymispisteenä, jos se kasvattaa neliövirheiden kokonaismäärää enemmän kuin mikään aikaisempi yhdistäminen. Estää pysähtymisen liian aikaisin tapauksissa, joissa pitäisi olla vain yksi segmentti, emme pidä yhdistää olla mahdollinen pysähtymispiste, ellei se johtaa kasvuun kokonaisvirhe, joka on vähemmän kuin 3% kokonaisvirhe regressio yhden segmentin. (3% on mielivaltainen kynnysarvo, mutta olemme havainneet sen toimivan hyvin käytännössä.) Alla on pari esimerkkiä, jotka osoittavat, miksi tämä pysäytyskriteeri toimii.
tarkastellaan ensin tietojoukkoa, joka on syntynyt lisäämällä normaalisti jakautunutta kohinaa yhden linjan suuntaisiin pisteisiin. Algoritmi sopii oikein vain yhteen segmenttiin tämän datajoukon läpi.
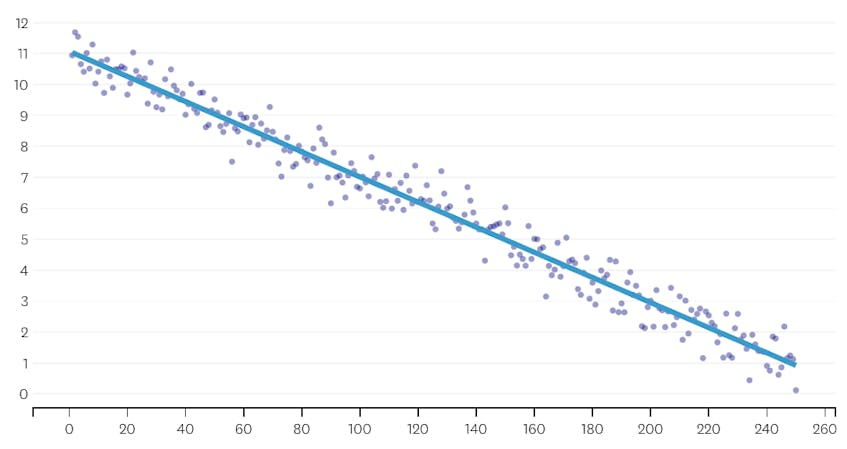
tällöin mikään yhdistäminen ei koskaan lisää neliövirheiden kokonaismäärää yli 3%. Siksi yhdistämistä ei pidetä riittävänä pysähdyspaikkana, ja käytämme lopullista tilaa, kun kaikki fuusiot on suoritettu. Alla olevassa kaaviossa näemme, että myöhemmät fuusiot pyrkivät tuomaan enemmän virheitä kuin aikaisemmat (mikä on järkevää, koska ne kukin vaikuttavat enemmän pisteitä), mutta virheiden lisääntyminen kasvaa vain vähitellen, kun useampia segmenttejä yhdistetään.
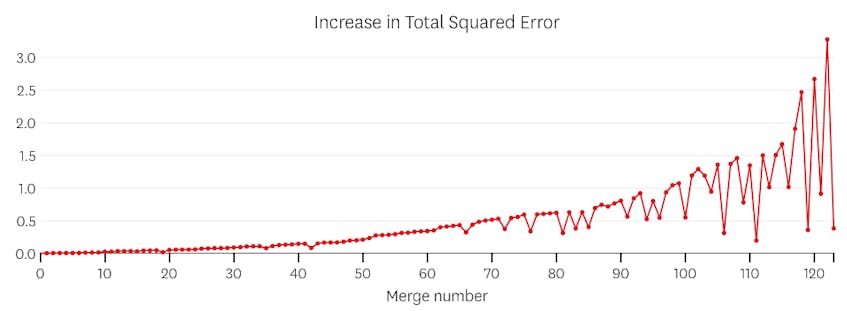
toiseksi, katsotaanpa esimerkki, jossa on seitsemän erillistä segmentti tiedot.
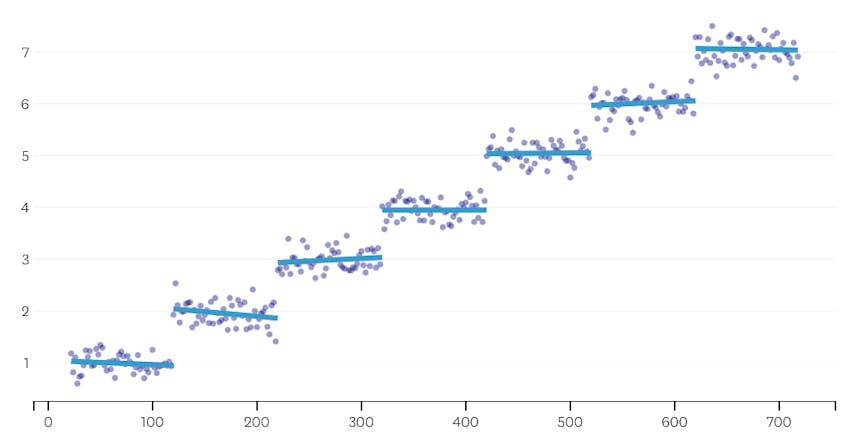
tässä tapauksessa, kun tarkastelemme juoni virheitä käyttöön kunkin yhdistämisen, näemme, että kuusi viimeistä fuusiot käyttöön paljon enemmän virheitä kuin mikään aiemmista fuusioista. Siksi meidän algoritmi muisti tilan segmenttien ennen 6th-to-last yhdistää ja käyttää sitä lopullisena ratkaisuna.
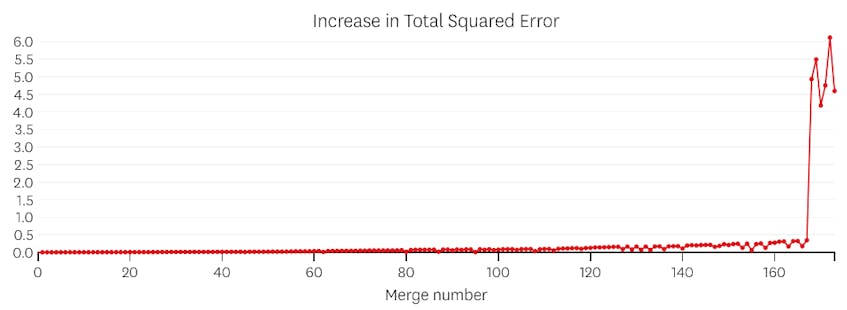
koodi
Datadogista / piecewise Github reposta löydät algoritmin Python-toteutuksen. piecewise() funktio on paikka, jossa raskas nosto tapahtuu; kun otetaan huomioon joukko tietoja, se palauttaa sijainti-ja regressiokertoimet kunkin asennetun segmentin osalta.
mukana on myös plot_data_with_regression() – käärintätoiminto nopeaan ja helppoon piirtämiseen. Nopea esimerkki siitä, miten tätä voitaisiin käyttää:
# Generate a short time series.t = np.arange(25)v = np.abs(t-7) + np.random.normal(0, 2, len(t))# Fit a piecewise regression, and plot the result.plot_data_with_regression(t, v)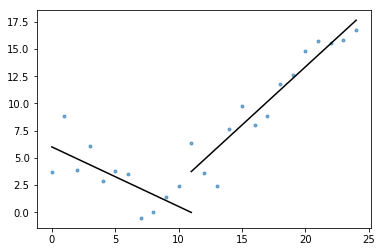
vaikka tämä toteutus käyttää OLS-lineaarista regressiota, samaa kehystä voidaan mukauttaa siihen liittyvien ongelmien ratkaisemiseksi. Korvaamalla potenssiin virhe absoluuttinen virhe tai Huber menetys, regressio voidaan tehdä vankka. Tai, askelfunktio voidaan sovittaa asettamalla jokaiselle segmentille vakioarvo, joka vastaa sen toimialueen havaintojen keskiarvoa.